 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto Invariant Representation Learning for Multimedia Recommendation
Paper and Code
Aug 23, 2023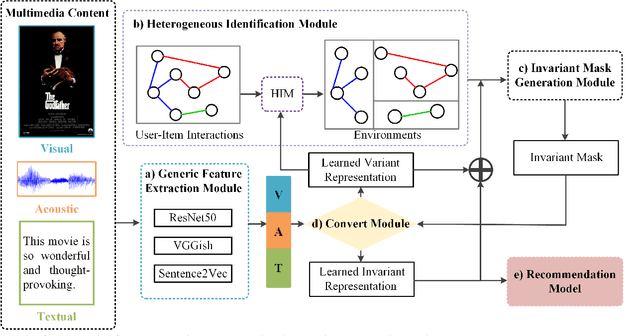
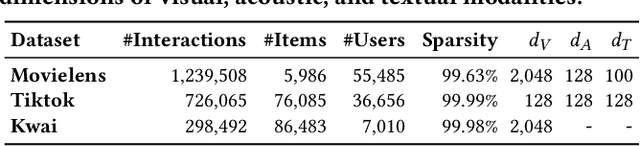
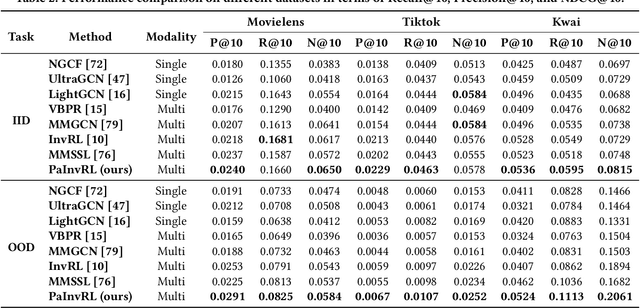
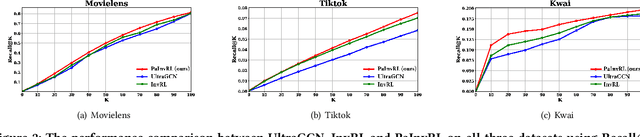
Multimedia recommendation involves personalized ranking tasks, where multimedia content is usually represented using a generic encoder. However, these generic representations introduce spurious correlations that fail to reveal users' true preferences. Existing works attempt to alleviate this problem by learning invariant representations, but overlook the balance between independent and identically distributed (IID) and out-of-distribution (OOD) generalization. In this paper, we propose a framework called Pareto Invariant Representation Learning (PaInvRL) to mitigate the impact of spurious correlations from an IID-OOD multi-objective optimization perspective, by learning invariant representations (intrinsic factors that attract user attention) and variant representations (other factors) simultaneously. Specifically, PaInvRL includes three iteratively executed modules: (i) heterogeneous identification module, which identifies the heterogeneous environments to reflect distributional shifts for user-item interactions; (ii) invariant mask generation module, which learns invariant masks based on the Pareto-optimal solutions that minimize the adaptive weighted Invariant Risk Minimization (IRM) and Empirical Risk (ERM) losses; (iii) convert module, which generates both variant representations and item-invariant representations for training a multi-modal recommendation model that mitigates spurious correlations and balances the generalization performance within and cross the environmental distributions. We compare the proposed PaInvRL with state-of-the-art recommendation models on three public multimedia recommendation datasets (Movielens, Tiktok, and Kwai), and the experimental results validate the effectiveness of PaInvRL for both within- and cross-environmental learning.