 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compact Representations of LLM Abilities via Item Response Theory
Oct 01, 2025



Recent years have witnessed a surge in the number of large language models (LLMs), yet efficiently managing and utilizing these vast resources remains a significant challenge. In this work, we explore how to learn compact representations of LLM abilities that can facilitate downstream tasks, such as model routing and performance prediction on new benchmarks. We frame this problem as estimating the probability that a given model will correctly answer a specific query. Inspired by the item response theory (IRT) in psychometrics, we model this probability as a function of three key factors: (i) the model's multi-skill ability vector, (2) the query's discrimination vector that separates models of differing skills, and (3) the query's difficulty scalar. To learn these parameters jointly, we introduce a Mixture-of-Experts (MoE) network that couples model- and query-level embeddings. Extensive experiments demonstrate that our approach leads to state-of-the-art performance in both model routing and benchmark accuracy prediction. Moreover, analysis validates that the learned parameters encode meaningful, interpretable information about model capabilities and query characteristics.
Reverse Preference Optimization for Complex Instruction Following
May 28, 2025Instruction following (IF) is a critical capability for large language models (LLMs). However, handling complex instructions with multiple constraints remains challenging. Previous methods typically select preference pairs based on the number of constraints they satisfy, introducing noise where chosen examples may fail to follow some constraints and rejected examples may excel in certain respects over the chosen ones. To address the challenge of aligning with multiple preferences, we propose a simple yet effective method called Reverse Preference Optimization (RPO). It mitigates noise in preference pairs by dynamically reversing the constraints within the instruction to ensure the chosen response is perfect, alleviating the burden of extensive sampling and filtering to collect perfect responses. Besides, reversal also enlarges the gap between chosen and rejected responses, thereby clarifying the optimization direction and making it more robust to noise. We evaluate RPO on two multi-turn IF benchmarks, Sysbench and Multi-IF, demonstrating average improvements over the DPO baseline of 4.6 and 2.5 points (on Llama-3.1 8B), respectively. Moreover, RPO scales effectively across model sizes (8B to 70B parameters), with the 70B RPO model surpassing GPT-4o.
Do We Truly Need So Many Samples? Multi-LLM Repeated Sampling Efficiently Scales Test-Time Compute
Apr 02, 2025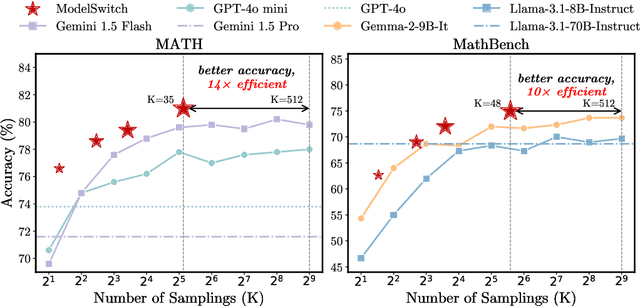

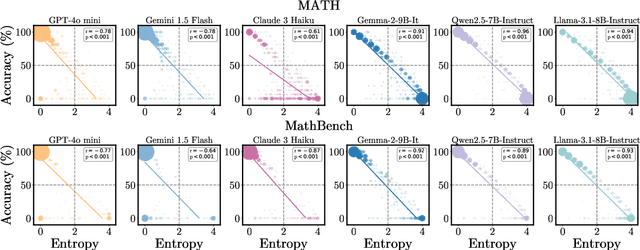
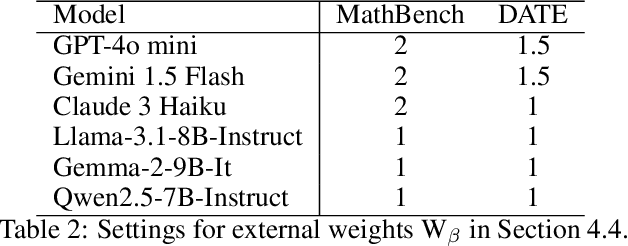
This paper presents a simple, effective, and cost-efficient strategy to improve LLM performance by scaling test-time compute. Our strategy builds upon the repeated-sampling-then-voting framework, with a novel twist: incorporating multiple models, even weaker ones, to leverage their complementary strengths that potentially arise from diverse training data and paradigms. By using consistency as a signal, our strategy dynamically switches between models. Theoretical analysis highlights the efficiency and performance advantages of our strategy. Extensive experiments on six datasets demonstrate that our strategy not only outperforms self-consistency and state-of-the-art multi-agent debate approaches, but also significantly reduces inference costs. Additionally, ModelSwitch requires only a few comparable LLMs to achieve optimal performance and can be extended with verification methods, demonstrating the potential of leveraging multiple LLMs in the generation-verification paradigm.
TARGA: Targeted Synthetic Data Generation for Practical Reasoning over Structured Data
Dec 27, 2024



Semantic parsing, which converts natural language questions into logic forms, plays a crucial role in reasoning within structured environments. However, existing methods encounter two significant challenges: reliance on extensive manually annotated datasets and limited generalization capability to unseen examples. To tackle these issues, we propose Targeted Synthetic Data Generation (TARGA), a practical framework that dynamically generates high-relevance synthetic data without manual annotation. Starting from the pertinent entities and relations of a given question, we probe for the potential relevant queries through layer-wise expansion and cross-layer combination. Then we generate corresponding natural language questions for these constructed queries to jointly serve as the synthetic demonstrations for in-context learning. Experiments on multiple knowledge base question answering (KBQA) datasets demonstrate that TARGA, using only a 7B-parameter model, substantially outperforms existing non-fine-tuned methods that utilize close-sourced model, achieving notable improvements in F1 scores on GrailQA(+7.7) and KBQA-Agent(+12.2). Furthermore, TARGA also exhibits superior sample efficiency, robustness, and generalization capabilities under non-I.I.D. settings.
Timeline-based Sentence Decomposition with In-Context Learning for Temporal Fact Extraction
May 16, 2024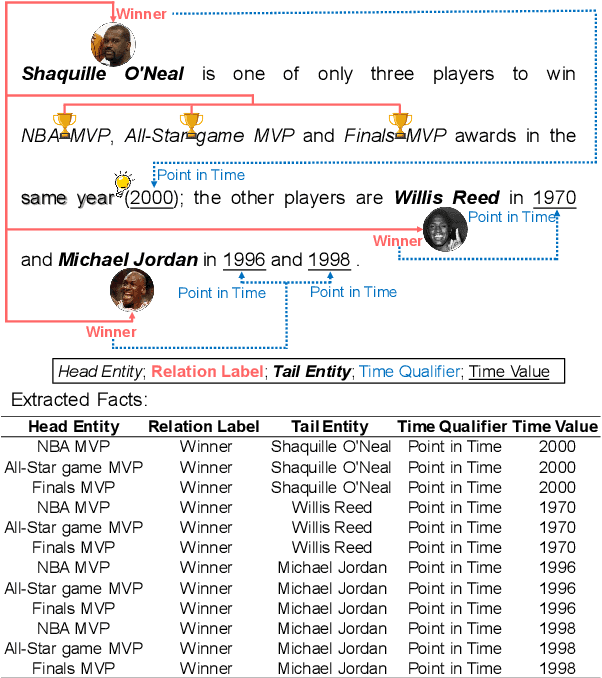
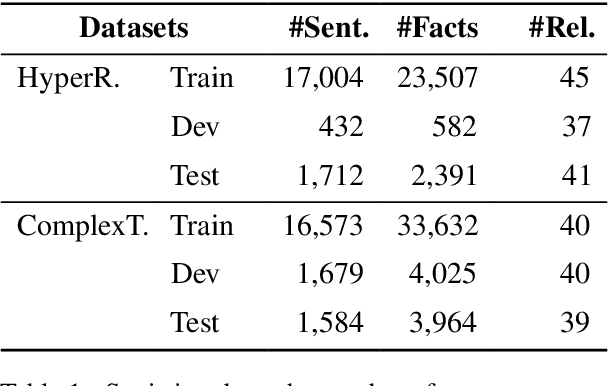
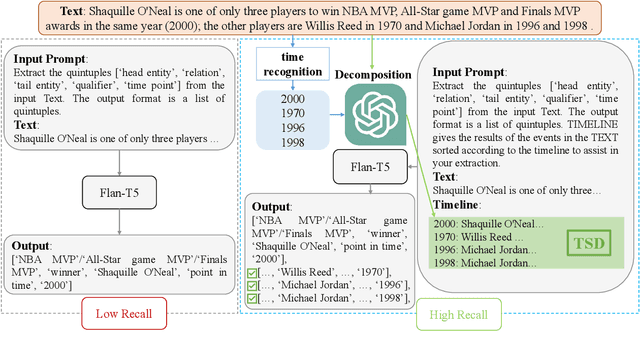

Facts extraction is pivotal for constructing knowledge graphs. Recently, the increasing demand for temporal facts in downstream tasks has led to the emergence of the task of temporal fact extraction. In this paper, we specifically address the extraction of temporal facts from natural language text. Previous studies fail to handle the challenge of establishing time-to-fact correspondences in complex sentences. To overcome this hurdle, we propose a timeline-based sentence decomposition strategy using large language models (LLMs) with in-context learning, ensuring a fine-grained understanding of the timeline associated with various facts. In addition, we evaluate the performance of LLMs for direct temporal fact extraction and get unsatisfactory results. To this end, we introduce TSDRE, a method that incorporates the decomposition capabilities of LLMs into the traditional fine-tuning of smaller pre-trained language models (PLMs). To support the evaluation, we construct ComplexTRED, a complex temporal fact extraction dataset. Our experiments show that TSDRE achieves state-of-the-art results on both HyperRED-Temporal and ComplexTRED datasets.
QueryAgent: A Reliable and Efficient Reasoning Framework with Environmental Feedback based Self-Correction
Mar 18, 2024



Employing Large Language Models (LLMs) for semantic parsing has achieved remarkable success. However, we find existing methods fall short in terms of reliability and efficiency when hallucinations are encountered. In this paper, we address these challenges with a framework called QueryAgent, which solves a question step-by-step and performs step-wise self-correction. We introduce an environmental feedback-based self-correction method called ERASER. Unlike traditional approaches, ERASER leverages rich environmental feedback in the intermediate steps to perform selective and differentiated self-correction only when necessary. Experimental results demonstrate that QueryAgent notably outperforms all previous few-shot methods using only one example on GrailQA and GraphQ by 7.0 and 15.0 F1. Moreover, our approach exhibits superiority in terms of efficiency, including runtime, query overhead, and API invocation costs. By leveraging ERASER, we further improve another baseline (i.e., AgentBench) by approximately 10 points, revealing the strong transferability of our approach.
Enhancing Complex Question Answering over Knowledge Graphs through Evidence Pattern Retrieval
Feb 03, 2024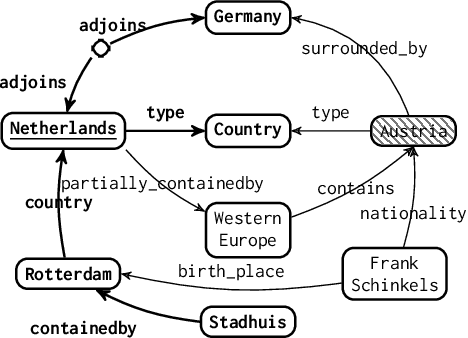

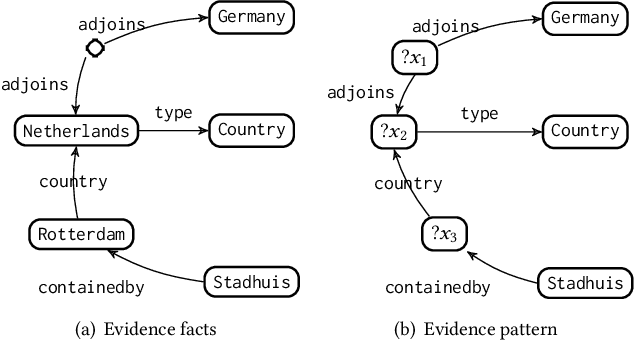
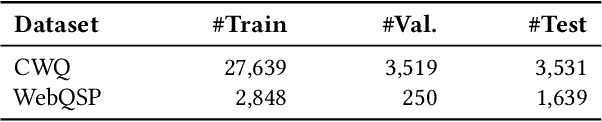
Information retrieval (IR) methods for KGQA consist of two stages: subgraph extraction and answer reasoning. We argue current subgraph extraction methods underestimate the importance of structural dependencies among evidence facts. We propose Evidence Pattern Retrieval (EPR) to explicitly model the structural dependencies during subgraph extraction. We implement EPR by indexing the atomic adjacency pattern of resource pairs. Given a question, we perform dense retrieval to obtain atomic patterns formed by resource pairs. We then enumerate their combinations to construct candidate evidence patterns. These evidence patterns are scored using a neural model, and the best one is selected to extract a subgraph for downstream answer reasoning. Experimental results demonstrate that the EPR-based approach has significantly improved the F1 scores of IR-KGQA methods by over 10 points on ComplexWebQuestions and achieves competitive performance on WebQuestionsSP.
Conflict Detection for Temporal Knowledge Graphs:A Fast Constraint Mining Algorithm and New Benchmarks
Dec 18, 2023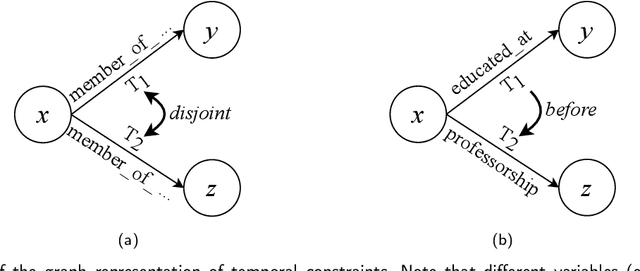
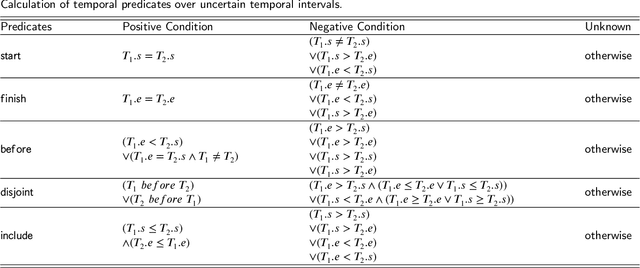
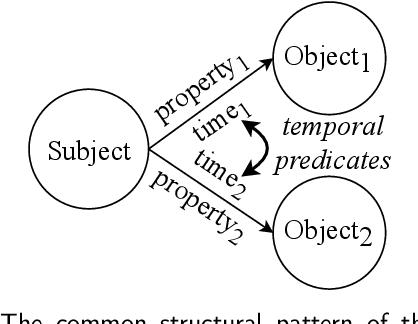

Temporal facts, which are used to describe events that occur during specific time periods, have become a topic of increased interest in the field of knowledge graph (KG) research. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. To address this problem, we start from the common pattern of temporal facts and propose a pattern-based temporal constraint mining method, PaTeCon. Unlike previous studies, PaTeCon uses graph patterns and statistical information relevant to the given KG to automatically generate temporal constraints, without the need for human experts. In this paper, we illustrate how this method can be optimized to achieve significant speed improvement. We also annotate Wikidata and Freebase to build two new benchmarks for conflict detection. Extensive experiments demonstrate that our pattern-based automatic constraint mining approach is highly effective in generating valuable temporal constraints.
MarkQA: A large scale KBQA dataset with numerical reasoning
Oct 24, 2023


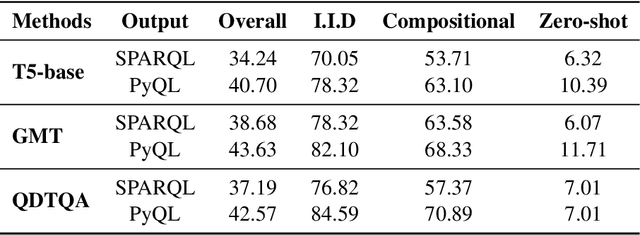
While question answering over knowledge bases (KBQA) has shown progress in addressing factoid questions, KBQA with numerical reasoning remains relatively unexplored. In this paper, we focus on the complex numerical reasoning in KBQA and propose a new task, NR-KBQA, which necessitates the ability to perform both multi-hop reasoning and numerical reasoning. We design a logic form in Python format called PyQL to represent the reasoning process of numerical reasoning questions. To facilitate the development of NR-KBQA, we present a large dataset called MarkQA, which is automatically constructed from a small set of seeds. Each question in MarkQA is equipped with its corresponding SPARQL query, alongside the step-by-step reasoning process in the QDMR format and PyQL program. Experimental results of some state-of-the-art QA methods on the MarkQA show that complex numerical reasoning in KBQA faces great challenges.
Question Decomposition Tree for Answering Complex Questions over Knowledge Bases
Jun 13, 2023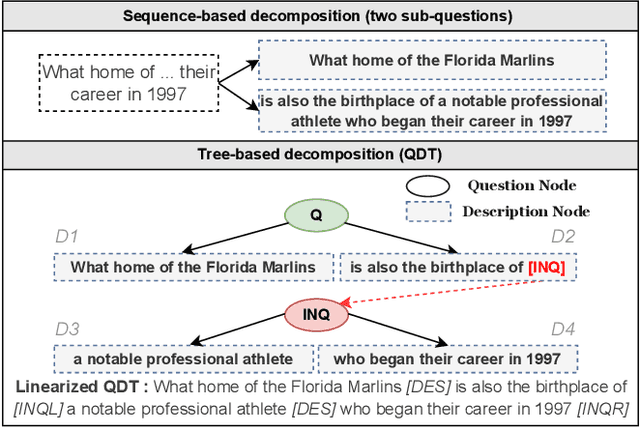


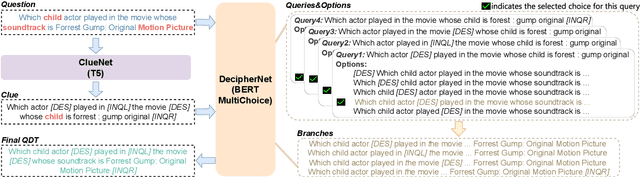
Knowledge base question answering (KBQA) has attracted a lot of interest in recent years, especially for complex questions which require multiple facts to answer. Question decomposition is a promising way to answer complex questions. Existing decomposition methods split the question into sub-questions according to a single compositionality type, which is not sufficient for questions involving multiple compositionality types. In this paper, we propose Question Decomposition Tree (QDT) to represent the structure of complex questions. Inspired by recent advances in natural language generation (NLG), we present a two-staged method called Clue-Decipher to generate QDT. It can leverage the strong ability of NLG model and simultaneously preserve the original questions. To verify that QDT can enhance KBQA task, we design a decomposition-based KBQA system called QDTQA. Extensive experiments show that QDTQA outperforms previous state-of-the-art methods on ComplexWebQuestions dataset. Besides, our decomposition method improves an existing KBQA system by 12% and sets a new state-of-the-art on LC-QuAD 1.0.