 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPIRE: A Diagnostic Benchmark for Embodied Spatial Reasoning of Vision-Language Models
Mar 13, 2026A recent trend in vision-language models (VLMs) has been to enhance their spatial cognition for embodied domains. Despite progress, existing evaluations have been limited both in paradigm and in coverage, hindering rapid, iterative model development. To address these limitations, we propose ESPIRE, a diagnostic benchmark for embodied spatial reasoning. ESPIRE offers a simulated world that physically grounds VLMs and evaluates them on spatial-reasoning-centric robotic tasks, thus narrowing the gap between evaluation and real-world deployment. To adapt VLMs to robotic tasks, we decompose each task into localization and execution, and frame both as generative problems, in stark contrast to predominant discriminative evaluations (e.g., via visual-question answering) that rely on distractors and discard execution. This decomposition further enables a fine-grained analysis beyond passive spatial reasoning toward reasoning to act. We systematically design ESPIRE both at the instruction level and at the environment level, ensuring broad coverage of spatial reasoning scenarios. We use ESPIRE to diagnose a range of frontier VLMs and provide in-depth analysis of their spatial reasoning behaviors.
Adaptable and Precise: Enterprise-Scenario LLM Function-Calling Capability Training Pipeline
Dec 20, 2024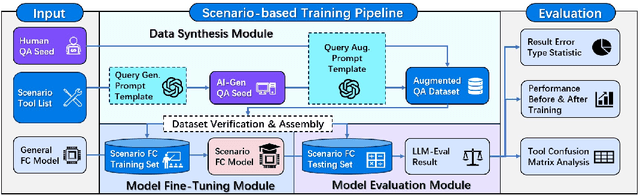


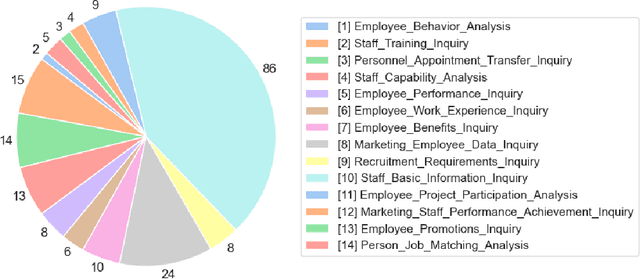
Enterprises possess a vast array of API assets scattered across various functions, forming the backbone of existing business processes. By leveraging these APIs as functional tools, enterprises can design diverse, scenario-specific agent applications, driven by on-premise function-calling models as the core engine. However, generic models often fail to meet enterprise requirements in terms of computational efficiency, output accuracy, and stability, necessitating scenario-specific adaptation. In this paper, we propose a training pipeline for function-calling capabilities tailored to real-world business scenarios. This pipeline includes the synthesis and augmentation of scenario-specific function-calling data, model fine-tuning, and performance evaluation and analysis. Using this pipeline, we generated 1,260 fully AI-generated samples and 1,035 augmented manually-labeled samples in digital HR agent scenario. The Qwen2.5-Coder-7B-Instruct model was employed as the base model and fine-tuned using the LoRA method on four GPUs with 24GB VRAM. Our fine-tuned model demonstrated outstanding performance in evaluations and practical applications, surpassing GPT-4 and GPT-4o in accuracy on the test set. These results validate the reliability of the proposed pipeline for training scenario-specific function-calling models.
Timeline-based Sentence Decomposition with In-Context Learning for Temporal Fact Extraction
May 16, 2024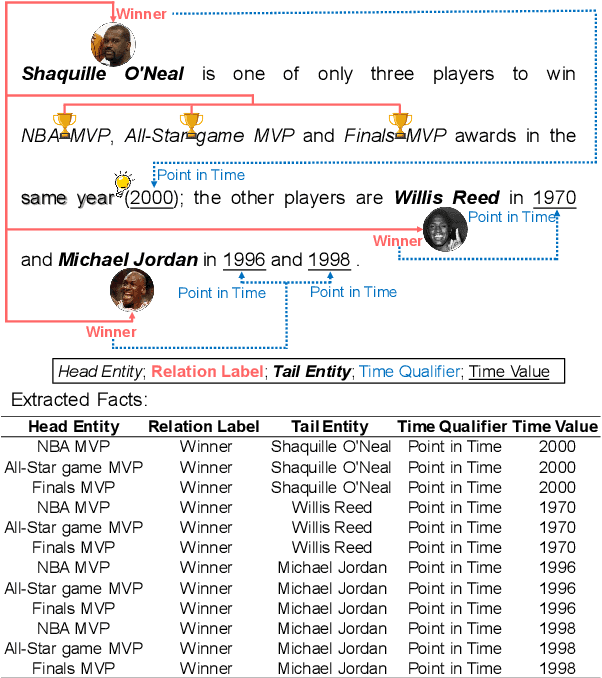
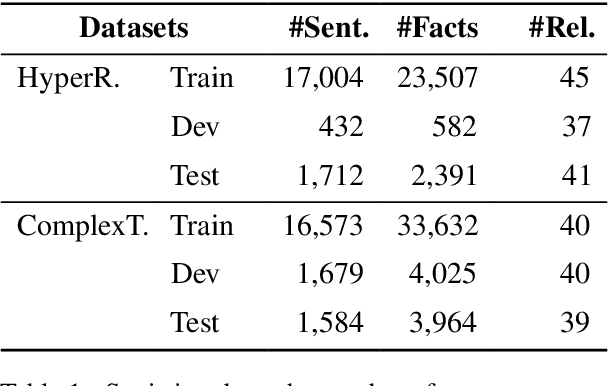
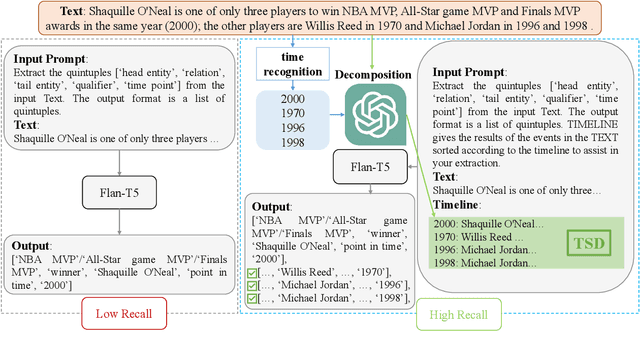

Facts extraction is pivotal for constructing knowledge graphs. Recently, the increasing demand for temporal facts in downstream tasks has led to the emergence of the task of temporal fact extraction. In this paper, we specifically address the extraction of temporal facts from natural language text. Previous studies fail to handle the challenge of establishing time-to-fact correspondences in complex sentences. To overcome this hurdle, we propose a timeline-based sentence decomposition strategy using large language models (LLMs) with in-context learning, ensuring a fine-grained understanding of the timeline associated with various facts. In addition, we evaluate the performance of LLMs for direct temporal fact extraction and get unsatisfactory results. To this end, we introduce TSDRE, a method that incorporates the decomposition capabilities of LLMs into the traditional fine-tuning of smaller pre-trained language models (PLMs). To support the evaluation, we construct ComplexTRED, a complex temporal fact extraction dataset. Our experiments show that TSDRE achieves state-of-the-art results on both HyperRED-Temporal and ComplexTRED datasets.
Enhancing Complex Question Answering over Knowledge Graphs through Evidence Pattern Retrieval
Feb 03, 2024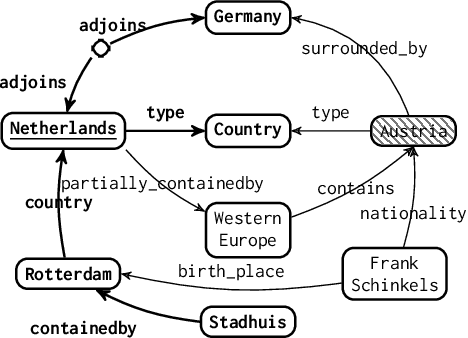

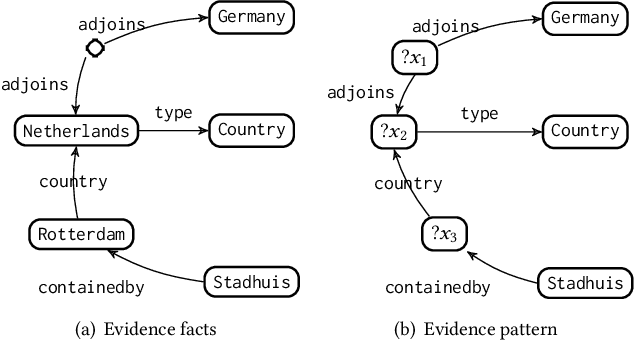
Information retrieval (IR) methods for KGQA consist of two stages: subgraph extraction and answer reasoning. We argue current subgraph extraction methods underestimate the importance of structural dependencies among evidence facts. We propose Evidence Pattern Retrieval (EPR) to explicitly model the structural dependencies during subgraph extraction. We implement EPR by indexing the atomic adjacency pattern of resource pairs. Given a question, we perform dense retrieval to obtain atomic patterns formed by resource pairs. We then enumerate their combinations to construct candidate evidence patterns. These evidence patterns are scored using a neural model, and the best one is selected to extract a subgraph for downstream answer reasoning. Experimental results demonstrate that the EPR-based approach has significantly improved the F1 scores of IR-KGQA methods by over 10 points on ComplexWebQuestions and achieves competitive performance on WebQuestionsSP.
Conflict Detection for Temporal Knowledge Graphs:A Fast Constraint Mining Algorithm and New Benchmarks
Dec 18, 2023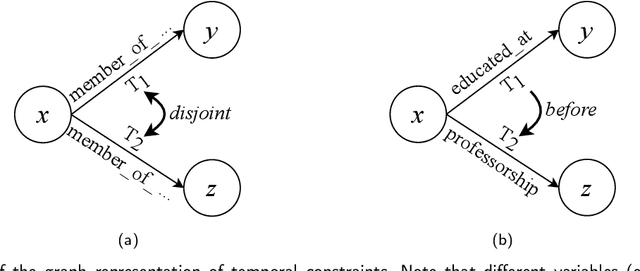
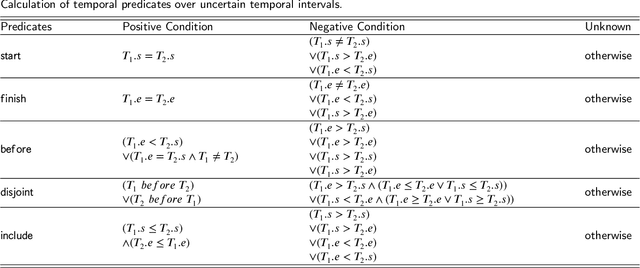
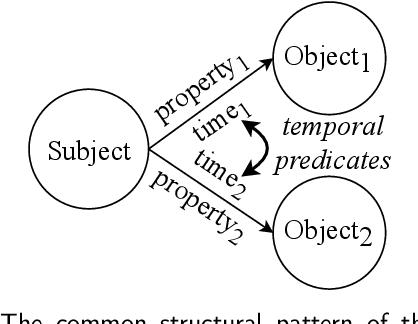

Temporal facts, which are used to describe events that occur during specific time periods, have become a topic of increased interest in the field of knowledge graph (KG) research. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. To address this problem, we start from the common pattern of temporal facts and propose a pattern-based temporal constraint mining method, PaTeCon. Unlike previous studies, PaTeCon uses graph patterns and statistical information relevant to the given KG to automatically generate temporal constraints, without the need for human experts. In this paper, we illustrate how this method can be optimized to achieve significant speed improvement. We also annotate Wikidata and Freebase to build two new benchmarks for conflict detection. Extensive experiments demonstrate that our pattern-based automatic constraint mining approach is highly effective in generating valuable temporal constraints.
PaTeCon: A Pattern-Based Temporal Constraint Mining Method for Conflict Detection on Knowledge Graphs
Apr 23, 2023



Temporal facts, the facts for characterizing events that hold in specific time periods, are attracting rising attention in the knowledge graph (KG) research communities. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs and detecting potential temporal conflicts. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. We start from the common pattern of temporal facts and constraints and propose a pattern-based temporal constraint mining method, PaTeCon. PaTeCon uses automatically determined graph patterns and their relevant statistical information over the given KG instead of human experts to generate time constraints. Specifically, PaTeCon dynamically attaches class restriction to candidate constraints according to their measuring scores.We evaluate PaTeCon on two large-scale datasets based on Wikidata and Freebase respectively. The experimental results show that pattern-based automatic constraint mining is powerful in generating valuable temporal constraints.
Automatic Rule Generation for Time Expression Normalization
Aug 31, 2021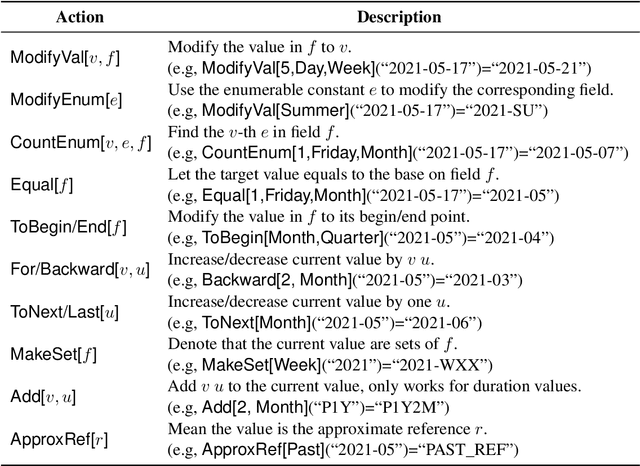
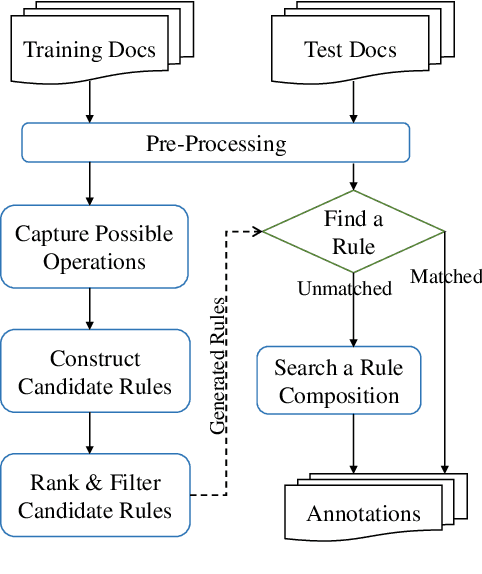

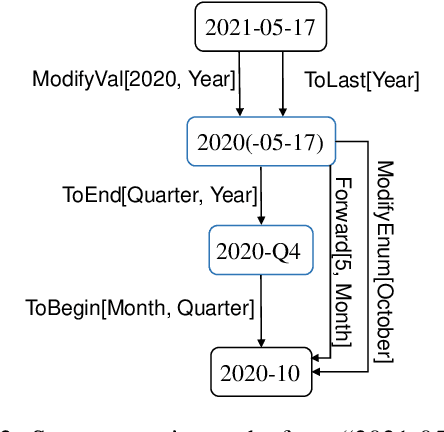
The understanding of time expressions includes two sub-tasks: recognition and normalization. In recent years, significant progress has been made in the recognition of time expressions while research on normalization has lagged behind. Existing SOTA normalization methods highly rely on rules or grammars designed by experts, which limits their performance on emerging corpora, such as social media texts. In this paper, we model time expression normalization as a sequence of operations to construct the normalized temporal value, and we present a novel method called ARTime, which can automatically generate normalization rules from training data without expert interventions. Specifically, ARTime automatically captures possible operation sequences from annotated data and generates normalization rules on time expressions with common surface forms. The experimental results show that ARTime can significantly surpass SOTA methods on the Tweets benchmark, and achieves competitive results with existing expert-engineered rule methods on the TempEval-3 benchmark.
Spatio-Temporal Neural Network for Fitting and Forecasting COVID-19
Mar 22, 2021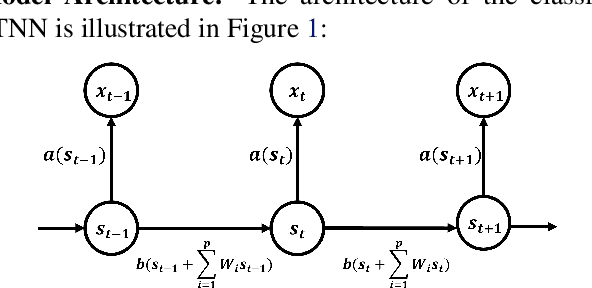
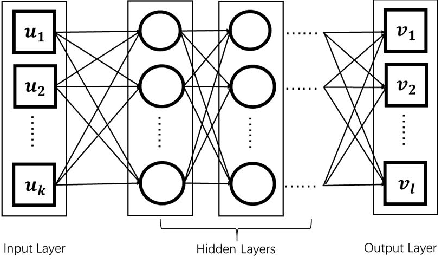

We established a Spatio-Temporal Neural Network, namely STNN, to forecast the spread of the coronavirus COVID-19 outbreak worldwide in 2020. The basic structure of STNN is similar to the Recurrent Neural Network (RNN) incorporating with not only temporal data but also spatial features. Two improved STNN architectures, namely the STNN with Augmented Spatial States (STNN-A) and the STNN with Input Gate (STNN-I), are proposed, which ensure more predictability and flexibility. STNN and its variants can be trained using Stochastic Gradient Descent (SGD) algorithm and its improved variants (e.g., Adam, AdaGrad and RMSProp). Our STNN models are compared with several classical epidemic prediction models, including the fully-connected neural network (BPNN), and the recurrent neural network (RNN), the classical curve fitting models, as well as the SEIR dynamical system model. Numerical simulations demonstrate that STNN models outperform many others by providing more accurate fitting and prediction, and by handling both spatial and temporal data.
A Difference-of-Convex Programming Approach With Parallel Branch-and-Bound For Sentence Compression Via A Hybrid Extractive Model
Feb 02, 2020

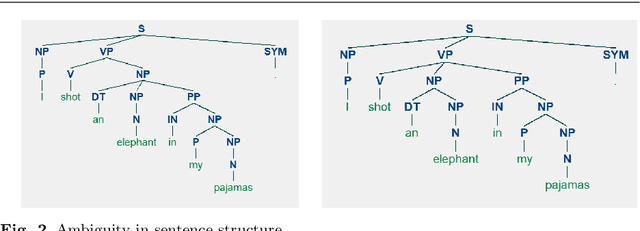

Sentence compression is an important problem in natural language processing with wide applications in text summarization, search engine and human-AI interaction system etc. In this paper, we design a hybrid extractive sentence compression model combining a probability language model and a parse tree language model for compressing sentences by guaranteeing the syntax correctness of the compression results. Our compression model is formulated as an integer linear programming problem, which can be rewritten as a Difference-of-Convex (DC) programming problem based on the exact penalty technique. We use a well known efficient DC algorithm -- DCA to handle the penalized problem for local optimal solutions. Then a hybrid global optimization algorithm combining DCA with a parallel branch-and-bound framework, namely PDCABB, is used for finding global optimal solutions. Numerical results demonstrate that our sentence compression model can provide excellent compression results evaluated by F-score, and indicate that PDCABB is a promising algorithm for solving our sentence compression model.