 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeline-based Sentence Decomposition with In-Context Learning for Temporal Fact Extraction
May 16, 2024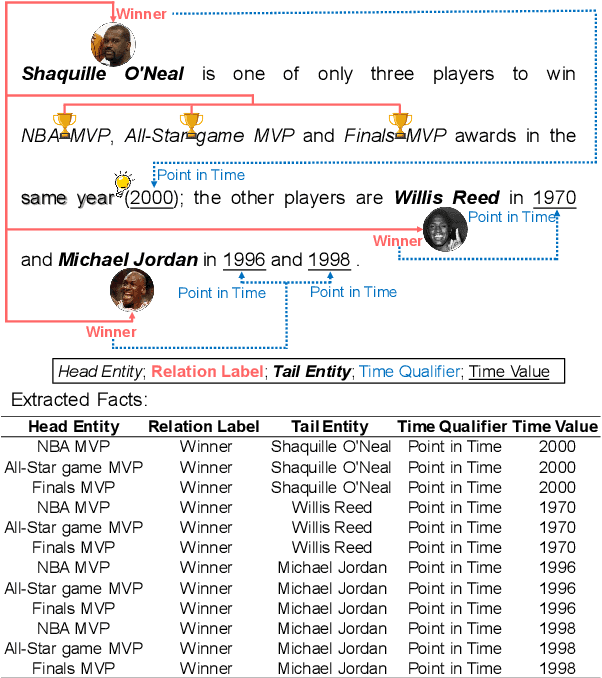
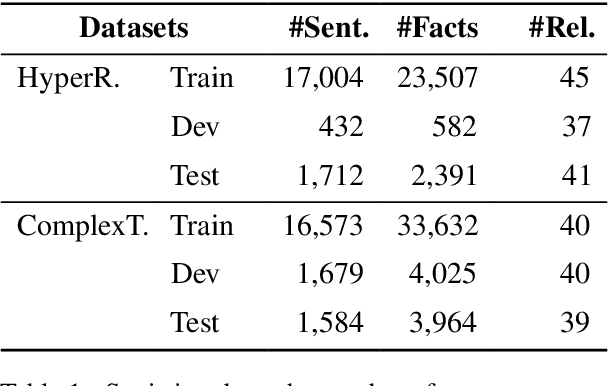
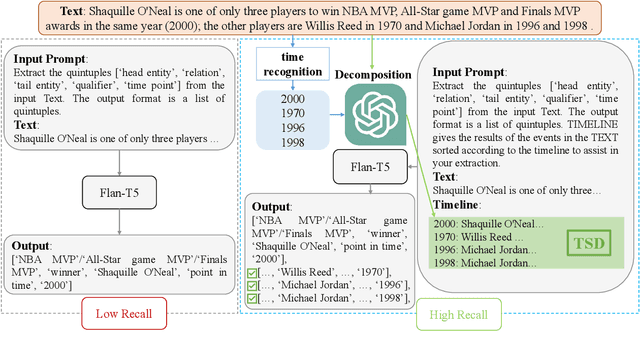

Facts extraction is pivotal for constructing knowledge graphs. Recently, the increasing demand for temporal facts in downstream tasks has led to the emergence of the task of temporal fact extraction. In this paper, we specifically address the extraction of temporal facts from natural language text. Previous studies fail to handle the challenge of establishing time-to-fact correspondences in complex sentences. To overcome this hurdle, we propose a timeline-based sentence decomposition strategy using large language models (LLMs) with in-context learning, ensuring a fine-grained understanding of the timeline associated with various facts. In addition, we evaluate the performance of LLMs for direct temporal fact extraction and get unsatisfactory results. To this end, we introduce TSDRE, a method that incorporates the decomposition capabilities of LLMs into the traditional fine-tuning of smaller pre-trained language models (PLMs). To support the evaluation, we construct ComplexTRED, a complex temporal fact extraction dataset. Our experiments show that TSDRE achieves state-of-the-art results on both HyperRED-Temporal and ComplexTRED datasets.
Conflict Detection for Temporal Knowledge Graphs:A Fast Constraint Mining Algorithm and New Benchmarks
Dec 18, 2023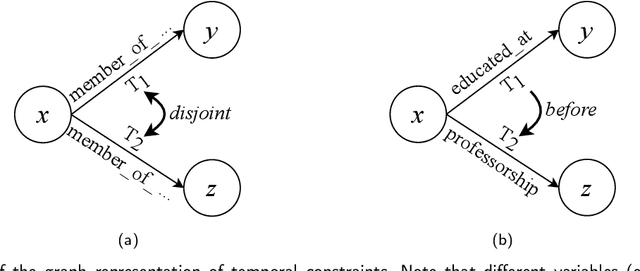
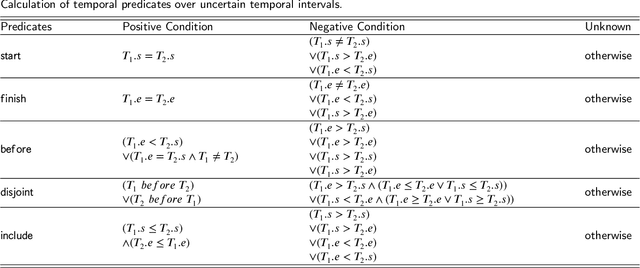
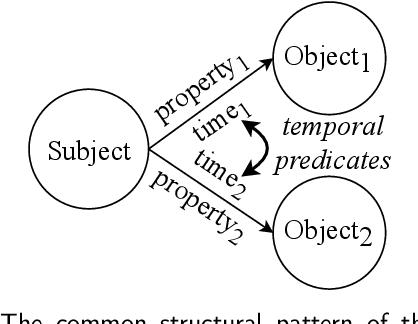

Temporal facts, which are used to describe events that occur during specific time periods, have become a topic of increased interest in the field of knowledge graph (KG) research. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. To address this problem, we start from the common pattern of temporal facts and propose a pattern-based temporal constraint mining method, PaTeCon. Unlike previous studies, PaTeCon uses graph patterns and statistical information relevant to the given KG to automatically generate temporal constraints, without the need for human experts. In this paper, we illustrate how this method can be optimized to achieve significant speed improvement. We also annotate Wikidata and Freebase to build two new benchmarks for conflict detection. Extensive experiments demonstrate that our pattern-based automatic constraint mining approach is highly effective in generating valuable temporal constraints.
Priority prediction of Asian Hornet sighting report using machine learning methods
Jun 28, 2021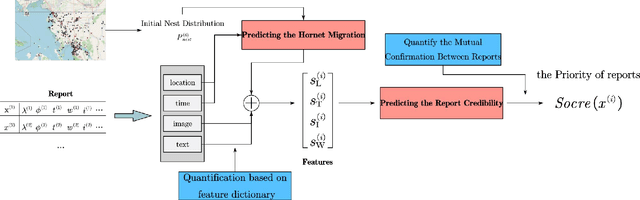
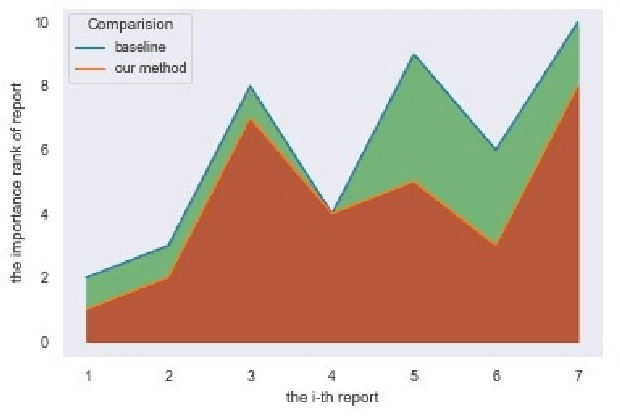
As infamous invaders to the North American ecosystem, the Asian giant hornet (Vespa mandarinia) is devastating not only to native bee colonies, but also to local apiculture. One of the most effective way to combat the harmful species is to locate and destroy their nests. By mobilizing the public to actively report possible sightings of the Asian giant hornet, the governmentcould timely send inspectors to confirm and possibly destroy the nests. However, such confirmation requires lab expertise, where manually checking the reports one by one is extremely consuming of human resources. Further given the limited knowledge of the public about the Asian giant hornet and the randomness of report submission, only few of the numerous reports proved positive, i.e. existing nests. How to classify or prioritize the reports efficiently and automatically, so as to determine the dispatch of personnel, is of great significance to the control of the Asian giant hornet. In this paper, we propose a method to predict the priority of sighting reports based on machine learning. We model the problem of optimal prioritization of sighting reports as a problem of classification and prediction. We extracted a variety of rich features in the report: location, time, image(s), and textual description. Based on these characteristics, we propose a classification model based on logistic regression to predict the credibility of a certain report. Furthermore, our model quantifies the impact between reports to get the priority ranking of the reports. Extensive experiments on the public dataset from the WSDA (the Washington State Department of Agriculture) have proved the effectiveness of our method.