 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMic: A Multi-Agent-Based Stand-Up Comedy Generation System
Jan 13, 2026Chinese stand-up comedy generation goes beyond plain text generation, requiring culturally grounded humor, precise timing, stage-performance cues, and implicit multi-step reasoning. Moreover, commonly used Chinese humor datasets are often better suited for humor understanding and evaluation than for long-form stand-up generation, making direct supervision misaligned with the target task. To address these challenges, we present OpenMic, an end-to-end multi-agent system built on AutoGen that transforms a user-provided life topic into a 3-5 minute Chinese stand-up performance and further produces a narrated comedy video. OpenMic orchestrates multiple specialized agents in a multi-round iterative loop-planning to jointly optimize humor, timing, and performability. To mitigate the dataset-task mismatch, we augment generation with retrieval-augmented generation (RAG) for material grounding and idea expansion, and we fine-tune a dedicated JokeWriter to better internalize stand-up-specific setup-punchline structures and long-range callbacks.
Can a Small Model Learn to Look Before It Leaps? Dynamic Learning and Proactive Correction for Hallucination Detection
Nov 08, 2025Hallucination in large language models (LLMs) remains a critical barrier to their safe deployment. Existing tool-augmented hallucination detection methods require pre-defined fixed verification strategies, which are crucial to the quality and effectiveness of tool calls. Some methods directly employ powerful closed-source LLMs such as GPT-4 as detectors, which are effective but too costly. To mitigate the cost issue, some methods adopt the teacher-student architecture and finetune open-source small models as detectors via agent tuning. However, these methods are limited by fixed strategies. When faced with a dynamically changing execution environment, they may lack adaptability and inappropriately call tools, ultimately leading to detection failure. To address the problem of insufficient strategy adaptability, we propose the innovative ``Learning to Evaluate and Adaptively Plan''(LEAP) framework, which endows an efficient student model with the dynamic learning and proactive correction capabilities of the teacher model. Specifically, our method formulates the hallucination detection problem as a dynamic strategy learning problem. We first employ a teacher model to generate trajectories within the dynamic learning loop and dynamically adjust the strategy based on execution failures. We then distill this dynamic planning capability into an efficient student model via agent tuning. Finally, during strategy execution, the student model adopts a proactive correction mechanism, enabling it to propose, review, and optimize its own verification strategies before execution. We demonstrate through experiments on three challenging benchmarks that our LEAP-tuned model outperforms existing state-of-the-art methods.
Learning Compact Representations of LLM Abilities via Item Response Theory
Oct 01, 2025



Recent years have witnessed a surge in the number of large language models (LLMs), yet efficiently managing and utilizing these vast resources remains a significant challenge. In this work, we explore how to learn compact representations of LLM abilities that can facilitate downstream tasks, such as model routing and performance prediction on new benchmarks. We frame this problem as estimating the probability that a given model will correctly answer a specific query. Inspired by the item response theory (IRT) in psychometrics, we model this probability as a function of three key factors: (i) the model's multi-skill ability vector, (2) the query's discrimination vector that separates models of differing skills, and (3) the query's difficulty scalar. To learn these parameters jointly, we introduce a Mixture-of-Experts (MoE) network that couples model- and query-level embeddings. Extensive experiments demonstrate that our approach leads to state-of-the-art performance in both model routing and benchmark accuracy prediction. Moreover, analysis validates that the learned parameters encode meaningful, interpretable information about model capabilities and query characteristics.
Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing
Aug 18, 2025Balancing performance and efficiency is a central challenge in large language model (LLM) advancement. GPT-5 addresses this with test-time routing, dynamically assigning queries to either an efficient or a high-capacity model during inference. In this work, we present Avengers-Pro, a test-time routing framework that ensembles LLMs of varying capacities and efficiencies, providing a unified solution for all performance-efficiency tradeoffs. The Avengers-Pro embeds and clusters incoming queries, then routes each to the most suitable model based on a performance-efficiency score. Across 6 challenging benchmarks and 8 leading models -- including GPT-5-medium, Gemini-2.5-pro, and Claude-opus-4.1 -- Avengers-Pro achieves state-of-the-art results: by varying a performance-efficiency trade-off parameter, it can surpass the strongest single model (GPT-5-medium) by +7% in average accuracy. Moreover, it can match the average accuracy of the strongest single model at 27% lower cost, and reach ~90% of that performance at 63% lower cost. Last but not least, it achieves a Pareto frontier, consistently yielding the highest accuracy for any given cost, and the lowest cost for any given accuracy, among all single models. Code is available at https://github.com/ZhangYiqun018/AvengersPro.
CAVGAN: Unifying Jailbreak and Defense of LLMs via Generative Adversarial Attacks on their Internal Representations
Jul 08, 2025Security alignment enables the Large Language Model (LLM) to gain the protection against malicious queries, but various jailbreak attack methods reveal the vulnerability of this security mechanism. Previous studies have isolated LLM jailbreak attacks and defenses. We analyze the security protection mechanism of the LLM, and propose a framework that combines attack and defense. Our method is based on the linearly separable property of LLM intermediate layer embedding, as well as the essence of jailbreak attack, which aims to embed harmful problems and transfer them to the safe area. We utilize generative adversarial network (GAN) to learn the security judgment boundary inside the LLM to achieve efficient jailbreak attack and defense. The experimental results indicate that our method achieves an average jailbreak success rate of 88.85\% across three popular LLMs, while the defense success rate on the state-of-the-art jailbreak dataset reaches an average of 84.17\%. This not only validates the effectiveness of our approach but also sheds light on the internal security mechanisms of LLMs, offering new insights for enhancing model security The code and data are available at https://github.com/NLPGM/CAVGAN.
Do We Truly Need So Many Samples? Multi-LLM Repeated Sampling Efficiently Scales Test-Time Compute
Apr 02, 2025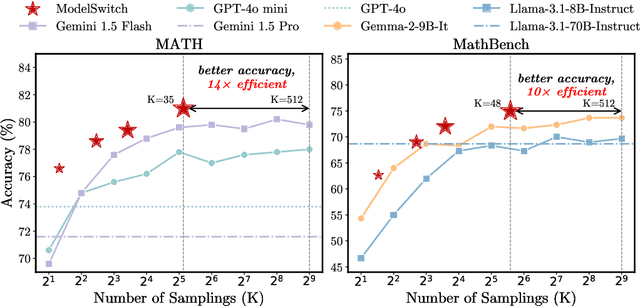

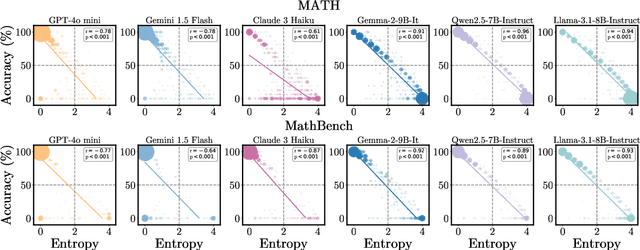
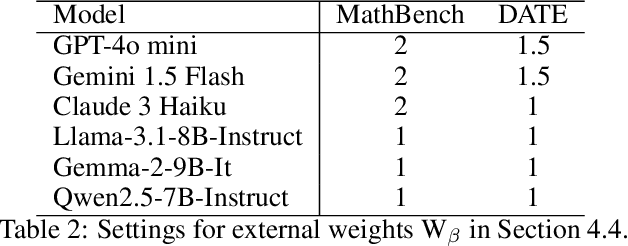
This paper presents a simple, effective, and cost-efficient strategy to improve LLM performance by scaling test-time compute. Our strategy builds upon the repeated-sampling-then-voting framework, with a novel twist: incorporating multiple models, even weaker ones, to leverage their complementary strengths that potentially arise from diverse training data and paradigms. By using consistency as a signal, our strategy dynamically switches between models. Theoretical analysis highlights the efficiency and performance advantages of our strategy. Extensive experiments on six datasets demonstrate that our strategy not only outperforms self-consistency and state-of-the-art multi-agent debate approaches, but also significantly reduces inference costs. Additionally, ModelSwitch requires only a few comparable LLMs to achieve optimal performance and can be extended with verification methods, demonstrating the potential of leveraging multiple LLMs in the generation-verification paradigm.
Reasoning based on symbolic and parametric knowledge bases: a survey
Jan 02, 2025Reasoning is fundamental to human intelligence, and critical for problem-solving, decision-making, and critical thinking. Reasoning refers to drawing new conclusions based on existing knowledge, which can support various applications like clinical diagnosis, basic education, and financial analysis. Though a good number of surveys have been proposed for reviewing reasoning-related methods, none of them has systematically investigated these methods from the viewpoint of their dependent knowledge base. Both the scenarios to which the knowledge bases are applied and their storage formats are significantly different. Hence, investigating reasoning methods from the knowledge base perspective helps us better understand the challenges and future directions. To fill this gap, this paper first classifies the knowledge base into symbolic and parametric ones. The former explicitly stores information in human-readable symbols, and the latter implicitly encodes knowledge within parameters. Then, we provide a comprehensive overview of reasoning methods using symbolic knowledge bases, parametric knowledge bases, and both of them. Finally, we identify the future direction toward enhancing reasoning capabilities to bridge the gap between human and machine intelligence.
Toxicity Detection towards Adaptability to Changing Perturbations
Dec 17, 2024Toxicity detection is crucial for maintaining the peace of the society. While existing methods perform well on normal toxic contents or those generated by specific perturbation methods, they are vulnerable to evolving perturbation patterns. However, in real-world scenarios, malicious users tend to create new perturbation patterns for fooling the detectors. For example, some users may circumvent the detector of large language models (LLMs) by adding `I am a scientist' at the beginning of the prompt. In this paper, we introduce a novel problem, i.e., continual learning jailbreak perturbation patterns, into the toxicity detection field. To tackle this problem, we first construct a new dataset generated by 9 types of perturbation patterns, 7 of them are summarized from prior work and 2 of them are developed by us. We then systematically validate the vulnerability of current methods on this new perturbation pattern-aware dataset via both the zero-shot and fine tuned cross-pattern detection. Upon this, we present the domain incremental learning paradigm and the corresponding benchmark to ensure the detector's robustness to dynamically emerging types of perturbed toxic text. Our code and dataset are provided in the appendix and will be publicly available at GitHub, by which we wish to offer new research opportunities for the security-relevant communities.
Timeline-based Sentence Decomposition with In-Context Learning for Temporal Fact Extraction
May 16, 2024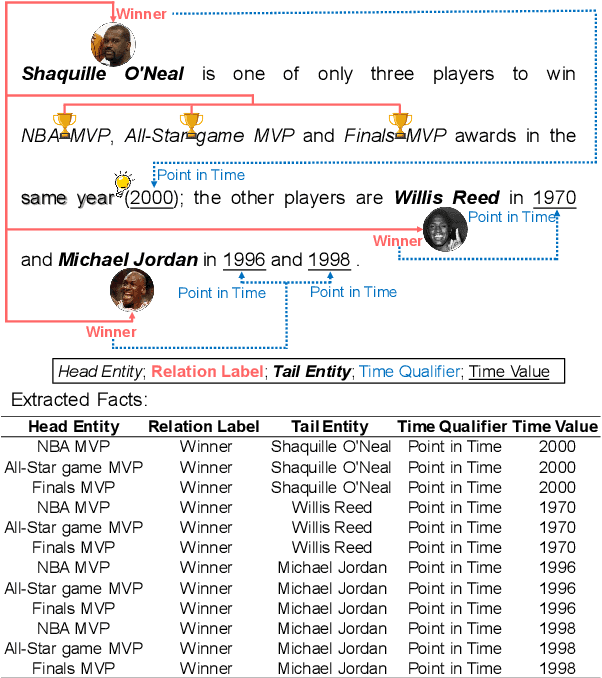
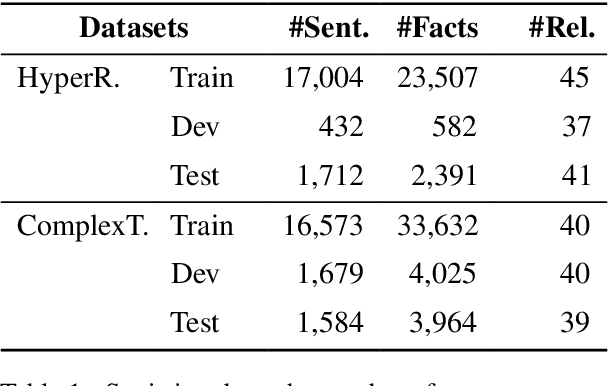
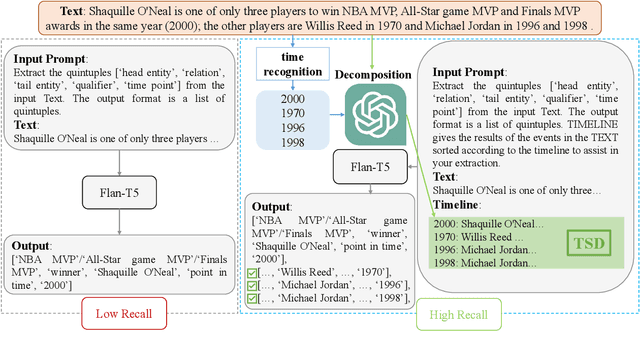

Facts extraction is pivotal for constructing knowledge graphs. Recently, the increasing demand for temporal facts in downstream tasks has led to the emergence of the task of temporal fact extraction. In this paper, we specifically address the extraction of temporal facts from natural language text. Previous studies fail to handle the challenge of establishing time-to-fact correspondences in complex sentences. To overcome this hurdle, we propose a timeline-based sentence decomposition strategy using large language models (LLMs) with in-context learning, ensuring a fine-grained understanding of the timeline associated with various facts. In addition, we evaluate the performance of LLMs for direct temporal fact extraction and get unsatisfactory results. To this end, we introduce TSDRE, a method that incorporates the decomposition capabilities of LLMs into the traditional fine-tuning of smaller pre-trained language models (PLMs). To support the evaluation, we construct ComplexTRED, a complex temporal fact extraction dataset. Our experiments show that TSDRE achieves state-of-the-art results on both HyperRED-Temporal and ComplexTRED datasets.
Conflict Detection for Temporal Knowledge Graphs:A Fast Constraint Mining Algorithm and New Benchmarks
Dec 18, 2023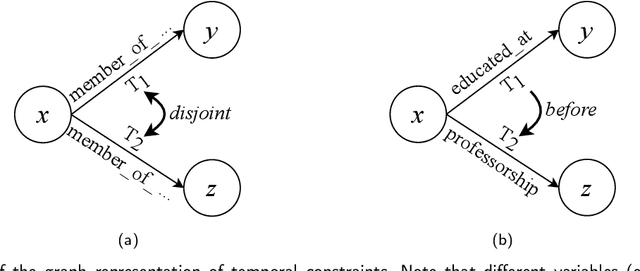
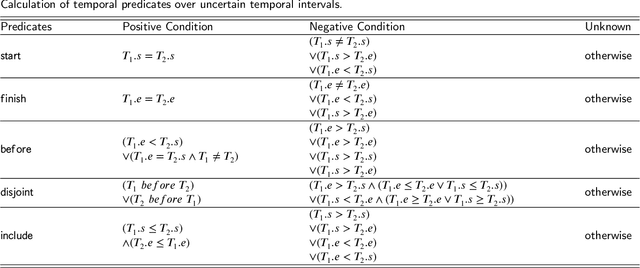
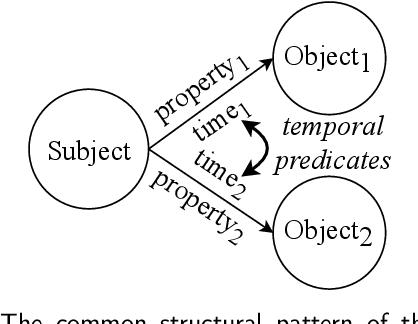

Temporal facts, which are used to describe events that occur during specific time periods, have become a topic of increased interest in the field of knowledge graph (KG) research. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. To address this problem, we start from the common pattern of temporal facts and propose a pattern-based temporal constraint mining method, PaTeCon. Unlike previous studies, PaTeCon uses graph patterns and statistical information relevant to the given KG to automatically generate temporal constraints, without the need for human experts. In this paper, we illustrate how this method can be optimized to achieve significant speed improvement. We also annotate Wikidata and Freebase to build two new benchmarks for conflict detection. Extensive experiments demonstrate that our pattern-based automatic constraint mining approach is highly effective in generating valuable temporal constraints.