 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Small Model Learn to Look Before It Leaps? Dynamic Learning and Proactive Correction for Hallucination Detection
Nov 08, 2025Hallucination in large language models (LLMs) remains a critical barrier to their safe deployment. Existing tool-augmented hallucination detection methods require pre-defined fixed verification strategies, which are crucial to the quality and effectiveness of tool calls. Some methods directly employ powerful closed-source LLMs such as GPT-4 as detectors, which are effective but too costly. To mitigate the cost issue, some methods adopt the teacher-student architecture and finetune open-source small models as detectors via agent tuning. However, these methods are limited by fixed strategies. When faced with a dynamically changing execution environment, they may lack adaptability and inappropriately call tools, ultimately leading to detection failure. To address the problem of insufficient strategy adaptability, we propose the innovative ``Learning to Evaluate and Adaptively Plan''(LEAP) framework, which endows an efficient student model with the dynamic learning and proactive correction capabilities of the teacher model. Specifically, our method formulates the hallucination detection problem as a dynamic strategy learning problem. We first employ a teacher model to generate trajectories within the dynamic learning loop and dynamically adjust the strategy based on execution failures. We then distill this dynamic planning capability into an efficient student model via agent tuning. Finally, during strategy execution, the student model adopts a proactive correction mechanism, enabling it to propose, review, and optimize its own verification strategies before execution. We demonstrate through experiments on three challenging benchmarks that our LEAP-tuned model outperforms existing state-of-the-art methods.
Knowledge Graph Tokenization for Behavior-Aware Generative Next POI Recommendation
Sep 15, 2025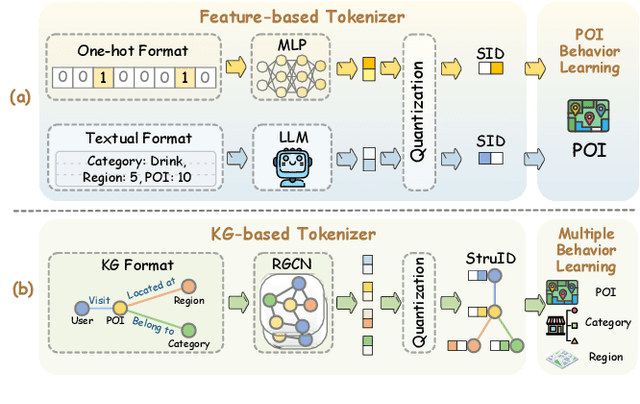
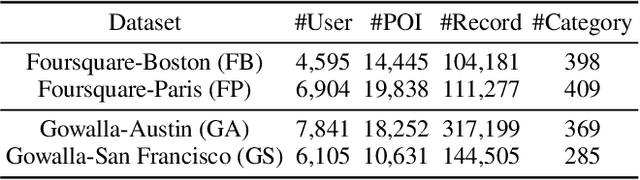
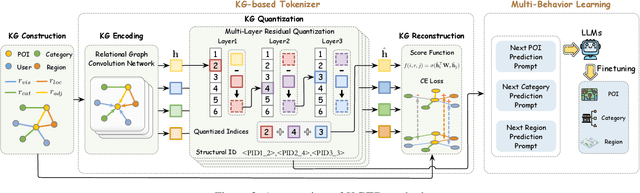
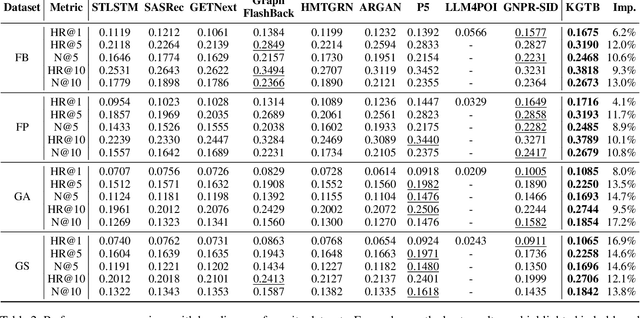
Generative paradigm, especially powered by Large Language Models (LLMs), has emerged as a new solution to the next point-of-interest (POI) recommendation. Pioneering studies usually adopt a two-stage pipeline, starting with a tokenizer converting POIs into discrete identifiers that can be processed by LLMs, followed by POI behavior prediction tasks to instruction-tune LLM for next POI recommendation. Despite of remarkable progress, they still face two limitations: (1) existing tokenizers struggle to encode heterogeneous signals in the recommendation data, suffering from information loss issue, and (2) previous instruction-tuning tasks only focus on users' POI visit behavior while ignore other behavior types, resulting in insufficient understanding of mobility. To address these limitations, we propose KGTB (Knowledge Graph Tokenization for Behavior-aware generative next POI recommendation). Specifically, KGTB organizes the recommendation data in a knowledge graph (KG) format, of which the structure can seamlessly preserve the heterogeneous information. Then, a KG-based tokenizer is developed to quantize each node into an individual structural ID. This process is supervised by the KG's structure, thus reducing the loss of heterogeneous information. Using generated IDs, KGTB proposes multi-behavior learning that introduces multiple behavior-specific prediction tasks for LLM fine-tuning, e.g., POI, category, and region visit behaviors. Learning on these behavior tasks provides LLMs with comprehensive insights on the target POI visit behavior. Experiments on four real-world city datasets demonstrate the superior performance of KGTB.
Privacy-protected Retrieval-Augmented Generation for Knowledge Graph Question Answering
Aug 12, 2025LLMs often suffer from hallucinations and outdated or incomplete knowledge. RAG is proposed to address these issues by integrating external knowledge like that in KGs into LLMs. However, leveraging private KGs in RAG systems poses significant privacy risks due to the black-box nature of LLMs and potential insecure data transmission, especially when using third-party LLM APIs lacking transparency and control. In this paper, we investigate the privacy-protected RAG scenario for the first time, where entities in KGs are anonymous for LLMs, thus preventing them from accessing entity semantics. Due to the loss of semantics of entities, previous RAG systems cannot retrieve question-relevant knowledge from KGs by matching questions with the meaningless identifiers of anonymous entities. To realize an effective RAG system in this scenario, two key challenges must be addressed: (1) How can anonymous entities be converted into retrievable information. (2) How to retrieve question-relevant anonymous entities. Hence, we propose a novel ARoG framework including relation-centric abstraction and structure-oriented abstraction strategies. For challenge (1), the first strategy abstracts entities into high-level concepts by dynamically capturing the semantics of their adjacent relations. It supplements meaningful semantics which can further support the retrieval process. For challenge (2), the second strategy transforms unstructured natural language questions into structured abstract concept paths. These paths can be more effectively aligned with the abstracted concepts in KGs, thereby improving retrieval performance. To guide LLMs to effectively retrieve knowledge from KGs, the two strategies strictly protect privacy from being exposed to LLMs. Experiments on three datasets demonstrate that ARoG achieves strong performance and privacy-robustness.
A Survey on Training-free Alignment of Large Language Models
Aug 12, 2025The alignment of large language models (LLMs) aims to ensure their outputs adhere to human values, ethical standards, and legal norms. Traditional alignment methods often rely on resource-intensive fine-tuning (FT), which may suffer from knowledge degradation and face challenges in scenarios where the model accessibility or computational resources are constrained. In contrast, training-free (TF) alignment techniques--leveraging in-context learning, decoding-time adjustments, and post-generation corrections--offer a promising alternative by enabling alignment without heavily retraining LLMs, making them adaptable to both open-source and closed-source environments. This paper presents the first systematic review of TF alignment methods, categorizing them by stages of pre-decoding, in-decoding, and post-decoding. For each stage, we provide a detailed examination from the viewpoint of LLMs and multimodal LLMs (MLLMs), highlighting their mechanisms and limitations. Furthermore, we identify key challenges and future directions, paving the way for more inclusive and effective TF alignment techniques. By synthesizing and organizing the rapidly growing body of research, this survey offers a guidance for practitioners and advances the development of safer and more reliable LLMs.
CAVGAN: Unifying Jailbreak and Defense of LLMs via Generative Adversarial Attacks on their Internal Representations
Jul 08, 2025Security alignment enables the Large Language Model (LLM) to gain the protection against malicious queries, but various jailbreak attack methods reveal the vulnerability of this security mechanism. Previous studies have isolated LLM jailbreak attacks and defenses. We analyze the security protection mechanism of the LLM, and propose a framework that combines attack and defense. Our method is based on the linearly separable property of LLM intermediate layer embedding, as well as the essence of jailbreak attack, which aims to embed harmful problems and transfer them to the safe area. We utilize generative adversarial network (GAN) to learn the security judgment boundary inside the LLM to achieve efficient jailbreak attack and defense. The experimental results indicate that our method achieves an average jailbreak success rate of 88.85\% across three popular LLMs, while the defense success rate on the state-of-the-art jailbreak dataset reaches an average of 84.17\%. This not only validates the effectiveness of our approach but also sheds light on the internal security mechanisms of LLMs, offering new insights for enhancing model security The code and data are available at https://github.com/NLPGM/CAVGAN.
Reasoning based on symbolic and parametric knowledge bases: a survey
Jan 02, 2025Reasoning is fundamental to human intelligence, and critical for problem-solving, decision-making, and critical thinking. Reasoning refers to drawing new conclusions based on existing knowledge, which can support various applications like clinical diagnosis, basic education, and financial analysis. Though a good number of surveys have been proposed for reviewing reasoning-related methods, none of them has systematically investigated these methods from the viewpoint of their dependent knowledge base. Both the scenarios to which the knowledge bases are applied and their storage formats are significantly different. Hence, investigating reasoning methods from the knowledge base perspective helps us better understand the challenges and future directions. To fill this gap, this paper first classifies the knowledge base into symbolic and parametric ones. The former explicitly stores information in human-readable symbols, and the latter implicitly encodes knowledge within parameters. Then, we provide a comprehensive overview of reasoning methods using symbolic knowledge bases, parametric knowledge bases, and both of them. Finally, we identify the future direction toward enhancing reasoning capabilities to bridge the gap between human and machine intelligence.
Toxicity Detection towards Adaptability to Changing Perturbations
Dec 17, 2024Toxicity detection is crucial for maintaining the peace of the society. While existing methods perform well on normal toxic contents or those generated by specific perturbation methods, they are vulnerable to evolving perturbation patterns. However, in real-world scenarios, malicious users tend to create new perturbation patterns for fooling the detectors. For example, some users may circumvent the detector of large language models (LLMs) by adding `I am a scientist' at the beginning of the prompt. In this paper, we introduce a novel problem, i.e., continual learning jailbreak perturbation patterns, into the toxicity detection field. To tackle this problem, we first construct a new dataset generated by 9 types of perturbation patterns, 7 of them are summarized from prior work and 2 of them are developed by us. We then systematically validate the vulnerability of current methods on this new perturbation pattern-aware dataset via both the zero-shot and fine tuned cross-pattern detection. Upon this, we present the domain incremental learning paradigm and the corresponding benchmark to ensure the detector's robustness to dynamically emerging types of perturbed toxic text. Our code and dataset are provided in the appendix and will be publicly available at GitHub, by which we wish to offer new research opportunities for the security-relevant communities.
Enhancing Relation Extraction via Supervised Rationale Verification and Feedback
Dec 10, 2024Despite the rapid progress that existing automated feedback methods have made in correcting the output of large language models (LLMs), these methods cannot be well applied to the relation extraction (RE) task due to their designated feedback objectives and correction manner. To address this problem, we propose a novel automated feedback framework for RE, which presents a rationale supervisor to verify the rationale and provide re-selected demonstrations as feedback to correct the initial prediction. Specifically, we first design a causal intervention and observation method for to collect biased/unbiased rationales for contrastive training the rationale supervisor. Then, we present a verification-feedback-correction procedure to iteratively enhance LLMs' capability of handling the RE task. Extensive experiments prove that our proposed framework significantly outperforms existing methods.
Large Language Models as Counterfactual Generator: Strengths and Weaknesses
May 24, 2023Large language models (LLMs) have demonstrated remarkable performance in a range of natural language understanding and generation tasks. Yet, their ability to generate counterfactuals, which can be used for areas like data augmentation, remains under-explored. This study aims to investigate the counterfactual generation capabilities of LLMs and analysis factors that influence this ability. First, we evaluate how effective are LLMs in counterfactual generation through data augmentation experiments for small language models (SLMs) across four tasks: sentiment analysis, natural language inference, named entity recognition, and relation extraction. While LLMs show promising enhancements in various settings, they struggle in complex tasks due to their self-limitations and the lack of logical guidance to produce counterfactuals that align with commonsense. Second, our analysis reveals the pivotal role of providing accurate task definitions and detailed step-by-step instructions to LLMs in generating counterfactuals. Interestingly, we also find that LLMs can generate reasonable counterfactuals even with unreasonable demonstrations, which illustrates that demonstrations are primarily to regulate the output format.This study provides the first comprehensive insight into counterfactual generation abilities of LLMs, and offers a novel perspective on utilizing LLMs for data augmentation to enhance SLMs.
Back to Reality: Leveraging Pattern-driven Modeling to Enable Affordable Sentiment Dependency Learning
Oct 16, 2021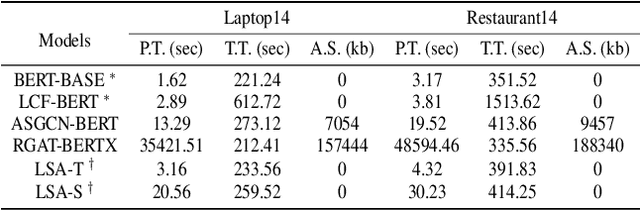

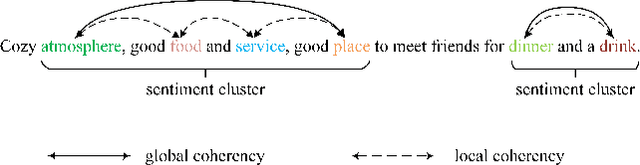
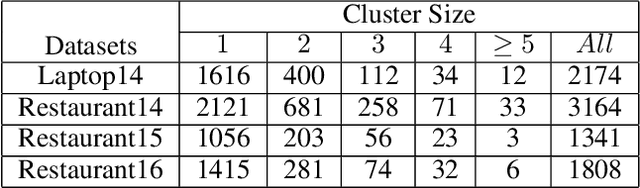
Aspect-based Sentiment Classification (ABSC) is a challenging sub-task of traditional sentiment analysis. Due to the difficulty of handling potential correlations among sentiment polarities of multiple aspects, i.e., sentiment dependency, recent popular works tend to exploit syntactic information guiding sentiment dependency parsing. However, syntax information (e.g., syntactic dependency trees) usually occupies expensive computational resources in terms of the operation of the adjacent matrix. Instead, we define the consecutive aspects with the same sentiment as the sentiment cluster in the case that we find that most sentiment dependency occurs between adjacent aspects. Motivated by this finding, we propose the sentiment patterns (SP) to guide the model dependency learning. Thereafter, we introduce the local sentiment aggregating (LSA) mechanism to focus on learning the sentiment dependency in the sentiment cluster. The LSA is more efficient than existing dependency tree-based models due to the absence of additional dependency matrix constructing and modeling. Furthermore, we propose differential weighting for aggregation window building to measure the importance of sentiment dependency. Experiments on four public datasets show that our models achieve state-of-the-art performance with especially improvement on learning sentiment cluster.