 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkrull: Towards Efficient Long Context Fine-tuning through Dynamic Data Scheduling
May 26, 2025Long-context supervised fine-tuning (Long-SFT) plays a vital role in enhancing the performance of large language models (LLMs) on long-context tasks. To smoothly adapt LLMs to long-context scenarios, this process typically entails training on mixed datasets containing both long and short sequences. However, this heterogeneous sequence length distribution poses significant challenges for existing training systems, as they fail to simultaneously achieve high training efficiency for both long and short sequences, resulting in sub-optimal end-to-end system performance in Long-SFT. In this paper, we present a novel perspective on data scheduling to address the challenges posed by the heterogeneous data distributions in Long-SFT. We propose Skrull, a dynamic data scheduler specifically designed for efficient long-SFT. Through dynamic data scheduling, Skrull balances the computation requirements of long and short sequences, improving overall training efficiency. Furthermore, we formulate the scheduling process as a joint optimization problem and thoroughly analyze the trade-offs involved. Based on those analysis, Skrull employs a lightweight scheduling algorithm to achieve near-zero cost online scheduling in Long-SFT. Finally, we implement Skrull upon DeepSpeed, a state-of-the-art distributed training system for LLMs. Experimental results demonstrate that Skrull outperforms DeepSpeed by 3.76x on average (up to 7.54x) in real-world long-SFT scenarios.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Back to Reality: Leveraging Pattern-driven Modeling to Enable Affordable Sentiment Dependency Learning
Oct 16, 2021

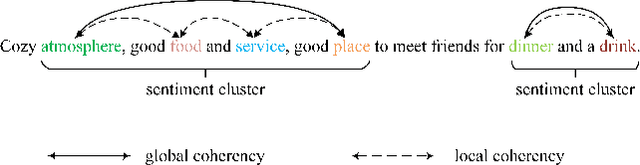
Aspect-based Sentiment Classification (ABSC) is a challenging sub-task of traditional sentiment analysis. Due to the difficulty of handling potential correlations among sentiment polarities of multiple aspects, i.e., sentiment dependency, recent popular works tend to exploit syntactic information guiding sentiment dependency parsing. However, syntax information (e.g., syntactic dependency trees) usually occupies expensive computational resources in terms of the operation of the adjacent matrix. Instead, we define the consecutive aspects with the same sentiment as the sentiment cluster in the case that we find that most sentiment dependency occurs between adjacent aspects. Motivated by this finding, we propose the sentiment patterns (SP) to guide the model dependency learning. Thereafter, we introduce the local sentiment aggregating (LSA) mechanism to focus on learning the sentiment dependency in the sentiment cluster. The LSA is more efficient than existing dependency tree-based models due to the absence of additional dependency matrix constructing and modeling. Furthermore, we propose differential weighting for aggregation window building to measure the importance of sentiment dependency. Experiments on four public datasets show that our models achieve state-of-the-art performance with especially improvement on learning sentiment cluster.
Importance-Aware Semantic Segmentation in Self-Driving with Discrete Wasserstein Training
Oct 21, 2020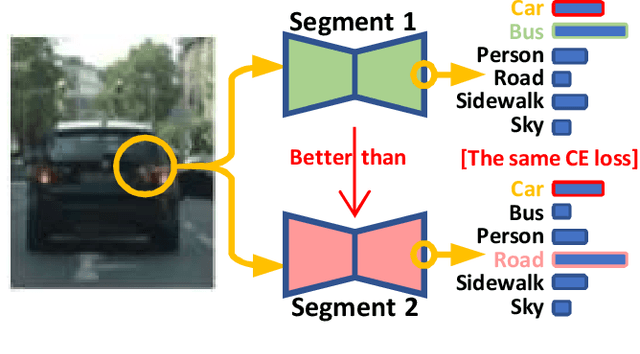
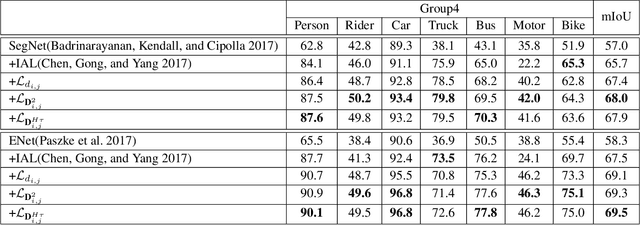
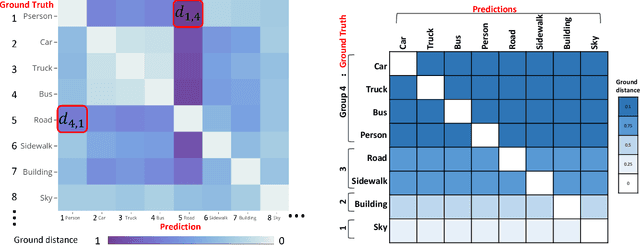
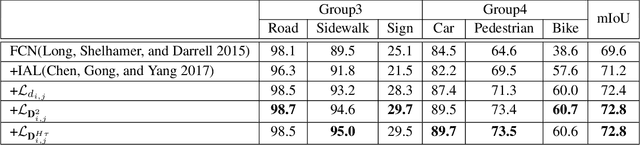
Semantic segmentation (SS) is an important perception manner for self-driving cars and robotics, which classifies each pixel into a pre-determined class. The widely-used cross entropy (CE) loss-based deep networks has achieved significant progress w.r.t. the mean Intersection-over Union (mIoU). However, the cross entropy loss can not take the different importance of each class in an self-driving system into account. For example, pedestrians in the image should be much more important than the surrounding buildings when make a decisions in the driving, so their segmentation results are expected to be as accurate as possible. In this paper, we propose to incorporate the importance-aware inter-class correlation in a Wasserstein training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori in a specific task, and the previous importance-ignored methods can be the particular cases. From an optimization perspective, we also extend our ground metric to a linear, convex or concave increasing function $w.r.t.$ pre-defined ground distance. We evaluate our method on CamVid and Cityscapes datasets with different backbones (SegNet, ENet, FCN and Deeplab) in a plug and play fashion. In our extenssive experiments, Wasserstein loss demonstrates superior segmentation performance on the predefined critical classes for safe-driving.