 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Image: Pushing the Boundaries of Generative Visual Intelligence
Apr 21, 2026We present Wan-Image, a unified visual generation system explicitly engineered to paradigm-shift image generation models from casual synthesizers into professional-grade productivity tools. While contemporary diffusion models excel at aesthetic generation, they frequently encounter critical bottlenecks in rigorous design workflows that demand absolute controllability, complex typography rendering, and strict identity preservation. To address these challenges, Wan-Image features a natively unified multi-modal architecture by synergizing the cognitive capabilities of large language models with the high-fidelity pixel synthesis of diffusion transformers, which seamlessly translates highly nuanced user intents into precise visual outputs. It is fundamentally powered by large-scale multi-modal data scaling, a systematic fine-grained annotation engine, and curated reinforcement learning data to surpass basic instruction following and unlock expert-level professional capabilities. These include ultra-long complex text rendering, hyper-diverse portrait generation, palette-guided generation, multi-subject identity preservation, coherent sequential visual generation, precise multi-modal interactive editing, native alpha-channel generation, and high-efficiency 4K synthesis. Across diverse human evaluations, Wan-Image exceeds Seedream 5.0 Lite and GPT Image 1.5 in overall performance, reaching parity with Nano Banana Pro in challenging tasks. Ultimately, Wan-Image revolutionizes visual content creation across e-commerce, entertainment, education, and personal productivity, redefining the boundaries of professional visual synthesis.
Skrull: Towards Efficient Long Context Fine-tuning through Dynamic Data Scheduling
May 26, 2025Long-context supervised fine-tuning (Long-SFT) plays a vital role in enhancing the performance of large language models (LLMs) on long-context tasks. To smoothly adapt LLMs to long-context scenarios, this process typically entails training on mixed datasets containing both long and short sequences. However, this heterogeneous sequence length distribution poses significant challenges for existing training systems, as they fail to simultaneously achieve high training efficiency for both long and short sequences, resulting in sub-optimal end-to-end system performance in Long-SFT. In this paper, we present a novel perspective on data scheduling to address the challenges posed by the heterogeneous data distributions in Long-SFT. We propose Skrull, a dynamic data scheduler specifically designed for efficient long-SFT. Through dynamic data scheduling, Skrull balances the computation requirements of long and short sequences, improving overall training efficiency. Furthermore, we formulate the scheduling process as a joint optimization problem and thoroughly analyze the trade-offs involved. Based on those analysis, Skrull employs a lightweight scheduling algorithm to achieve near-zero cost online scheduling in Long-SFT. Finally, we implement Skrull upon DeepSpeed, a state-of-the-art distributed training system for LLMs. Experimental results demonstrate that Skrull outperforms DeepSpeed by 3.76x on average (up to 7.54x) in real-world long-SFT scenarios.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024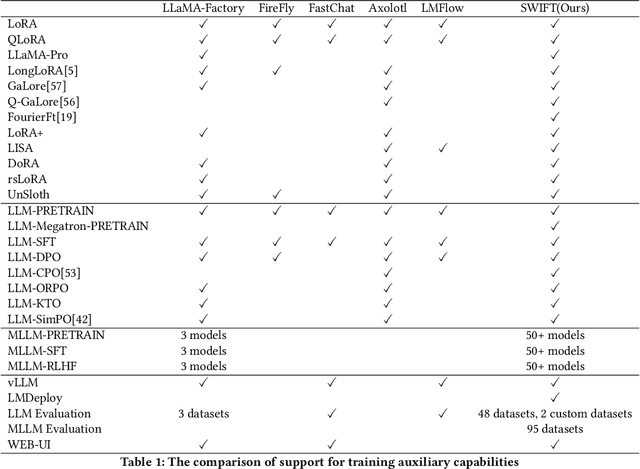
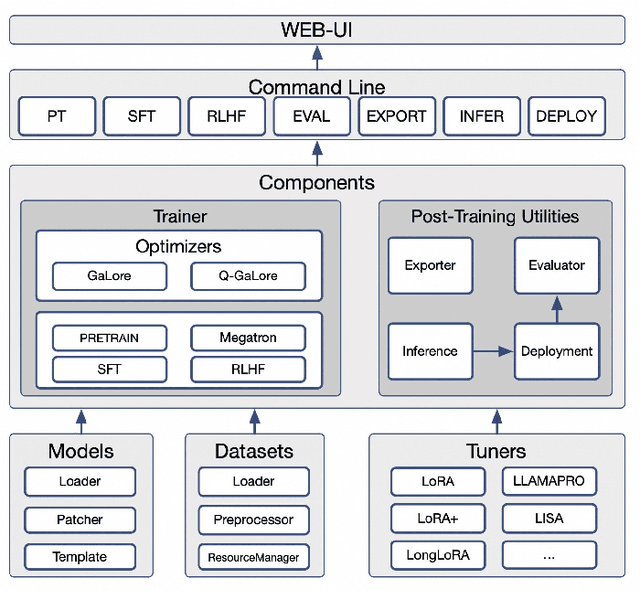


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
ROAM: memory-efficient large DNN training via optimized operator ordering and memory layout
Oct 30, 2023



As deep learning models continue to increase in size, the memory requirements for training have surged. While high-level techniques like offloading, recomputation, and compression can alleviate memory pressure, they also introduce overheads. However, a memory-efficient execution plan that includes a reasonable operator execution order and tensor memory layout can significantly increase the models' memory efficiency and reduce overheads from high-level techniques. In this paper, we propose ROAM which operates on computation graph level to derive memory-efficient execution plan with optimized operator order and tensor memory layout for models. We first propose sophisticated theories that carefully consider model structure and training memory load to support optimization for large complex graphs that have not been well supported in the past. An efficient tree-based algorithm is further proposed to search task divisions automatically, along with delivering high performance and effectiveness to solve the problem. Experiments show that ROAM achieves a substantial memory reduction of 35.7%, 13.3%, and 27.2% compared to Pytorch and two state-of-the-art methods and offers a remarkable 53.7x speedup. The evaluation conducted on the expansive GPT2-XL further validates ROAM's scalability.
TAP: Accelerating Large-Scale DNN Training Through Tensor Automatic Parallelisation
Feb 01, 2023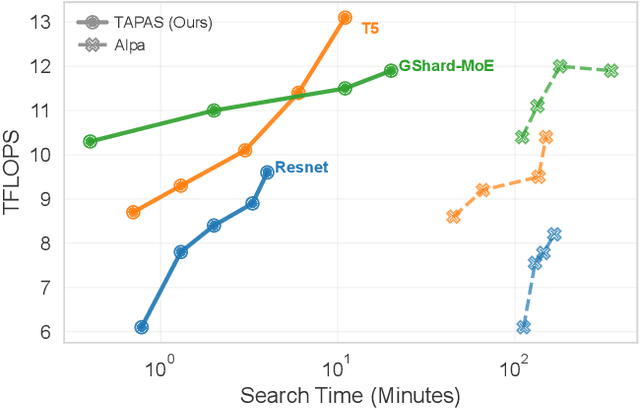

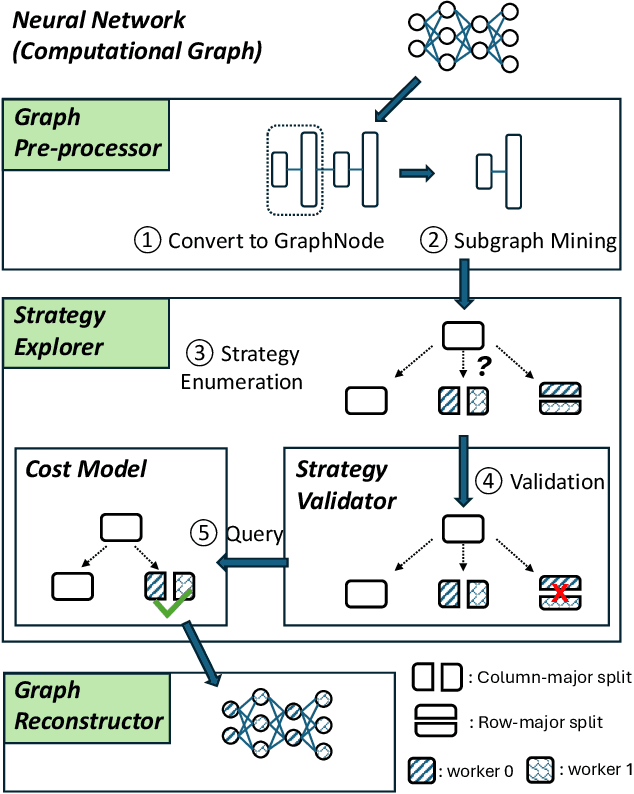
Model parallelism has become necessary to train large neural networks. However, finding a suitable model parallel schedule for an arbitrary neural network is a non-trivial task due to the exploding search space. In this work, we present a model parallelism framework TAP that automatically searches for the best data and tensor parallel schedules. Leveraging the key insight that a neural network can be represented as a directed acyclic graph, within which may only exist a limited set of frequent subgraphs, we design a graph pruning algorithm to fold the search space efficiently. TAP runs at sub-linear complexity concerning the neural network size. Experiments show that TAP is $20\times- 160\times$ faster than the state-of-the-art automatic parallelism framework, and the performance of its discovered schedules is competitive with the expert-engineered ones.
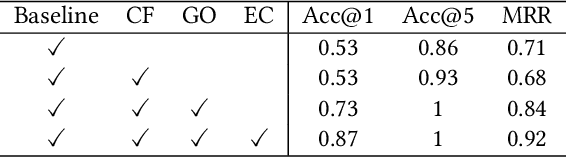
Revisiting and Advancing Chinese Natural Language Understanding with Accelerated Heterogeneous Knowledge Pre-training
Oct 12, 2022
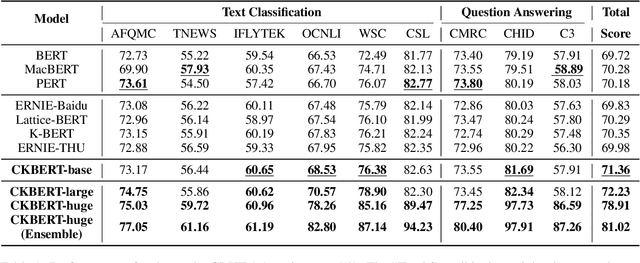
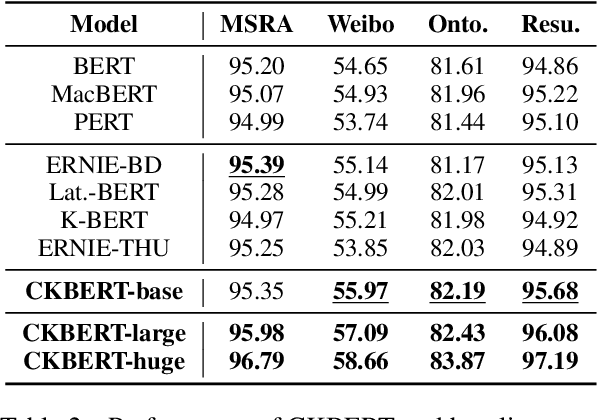
Recently, knowledge-enhanced pre-trained language models (KEPLMs) improve context-aware representations via learning from structured relations in knowledge graphs, and/or linguistic knowledge from syntactic or dependency analysis. Unlike English, there is a lack of high-performing open-source Chinese KEPLMs in the natural language processing (NLP) community to support various language understanding applications. In this paper, we revisit and advance the development of Chinese natural language understanding with a series of novel Chinese KEPLMs released in various parameter sizes, namely CKBERT (Chinese knowledge-enhanced BERT).Specifically, both relational and linguistic knowledge is effectively injected into CKBERT based on two novel pre-training tasks, i.e., linguistic-aware masked language modeling and contrastive multi-hop relation modeling. Based on the above two pre-training paradigms and our in-house implemented TorchAccelerator, we have pre-trained base (110M), large (345M) and huge (1.3B) versions of CKBERT efficiently on GPU clusters. Experiments demonstrate that CKBERT outperforms strong baselines for Chinese over various benchmark NLP tasks and in terms of different model sizes.
M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining
Oct 25, 2021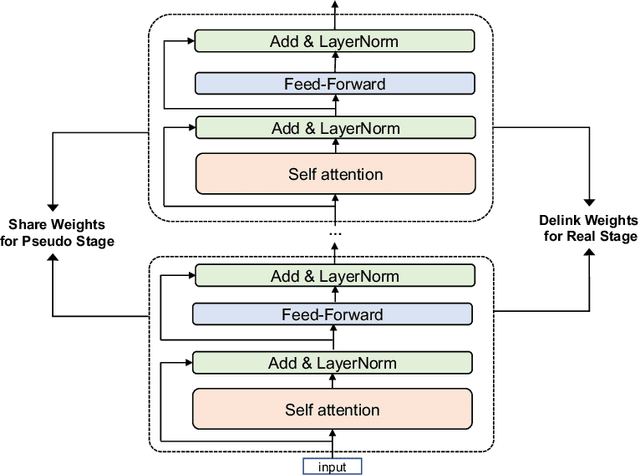

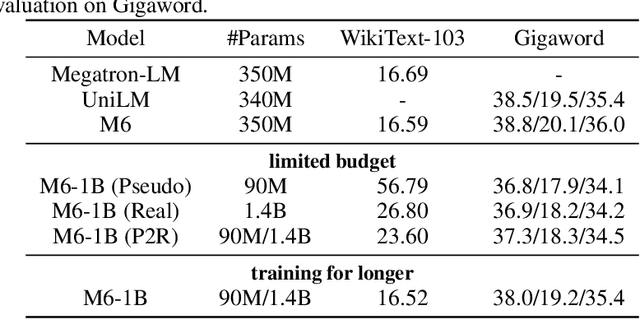
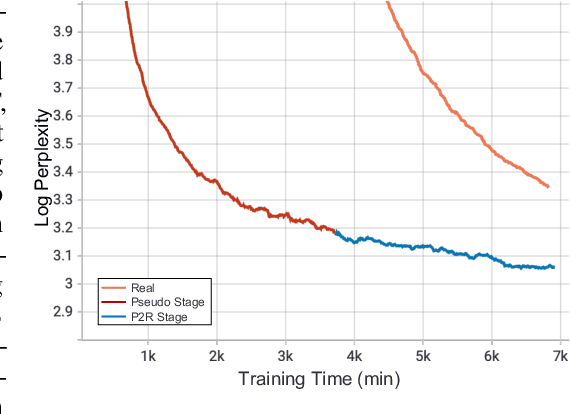
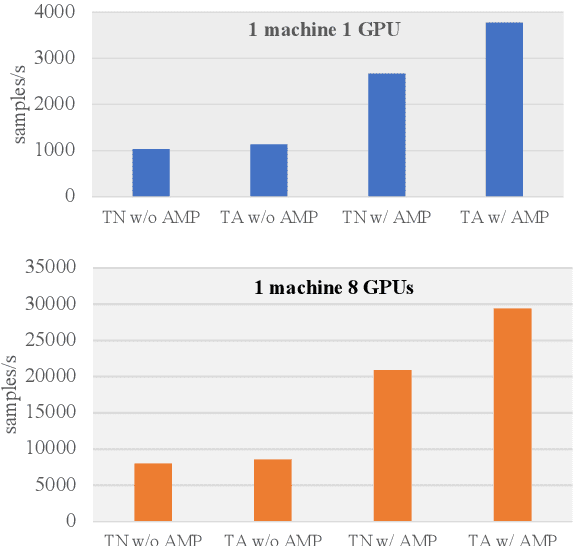
Recent expeditious developments in deep learning algorithms, distributed training, and even hardware design for large models have enabled training extreme-scale models, say GPT-3 and Switch Transformer possessing hundreds of billions or even trillions of parameters. However, under limited resources, extreme-scale model training that requires enormous amounts of computes and memory footprint suffers from frustratingly low efficiency in model convergence. In this paper, we propose a simple training strategy called "Pseudo-to-Real" for high-memory-footprint-required large models. Pseudo-to-Real is compatible with large models with architecture of sequential layers. We demonstrate a practice of pretraining unprecedented 10-trillion-parameter model, an order of magnitude larger than the state-of-the-art, on solely 512 GPUs within 10 days. Besides demonstrating the application of Pseudo-to-Real, we also provide a technique, Granular CPU offloading, to manage CPU memory for training large model and maintain high GPU utilities. Fast training of extreme-scale models on a decent amount of resources can bring much smaller carbon footprint and contribute to greener AI.
Exploring Sparse Expert Models and Beyond
Jun 14, 2021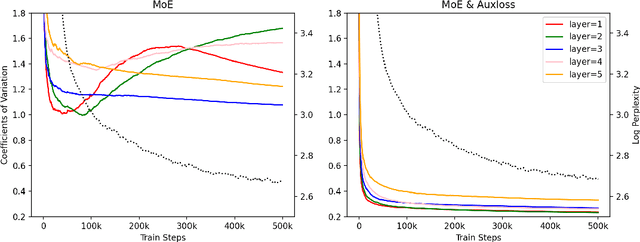

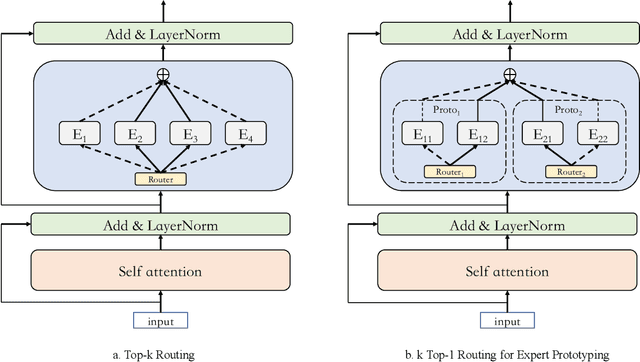
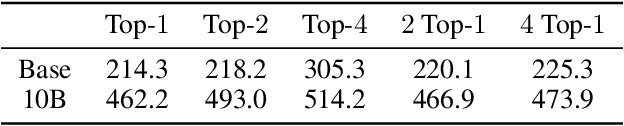
Mixture-of-Experts (MoE) models can achieve promising results with outrageous large amount of parameters but constant computation cost, and thus it has become a trend in model scaling. Still it is a mystery how MoE layers bring quality gains by leveraging the parameters with sparse activation. In this work, we investigate several key factors in sparse expert models. We observe that load imbalance may not be a significant problem affecting model quality, contrary to the perspectives of recent studies, while the number of sparsely activated experts $k$ and expert capacity $C$ in top-$k$ routing can significantly make a difference in this context. Furthermore, we take a step forward to propose a simple method called expert prototyping that splits experts into different prototypes and applies $k$ top-$1$ routing. This strategy improves the model quality but maintains constant computational costs, and our further exploration on extremely large-scale models reflects that it is more effective in training larger models. We push the model scale to over $1$ trillion parameters and implement it on solely $480$ NVIDIA V100-32GB GPUs, in comparison with the recent SOTAs on $2048$ TPU cores. The proposed giant model achieves substantial speedup in convergence over the same-size baseline.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021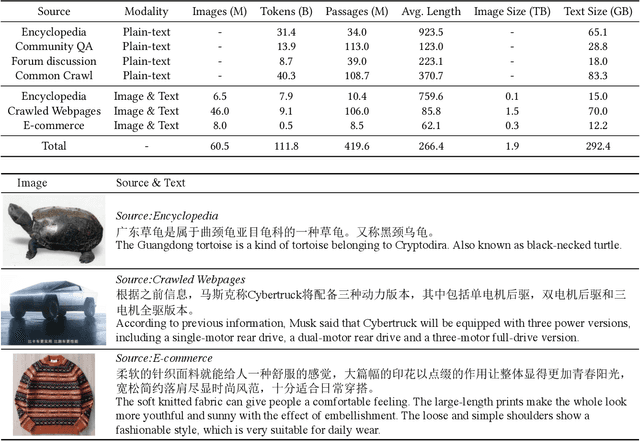
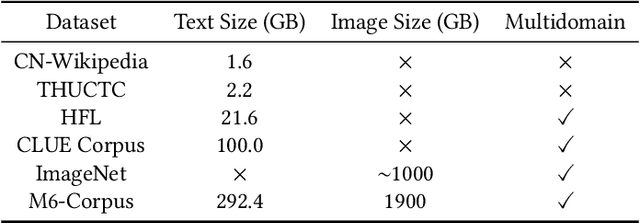

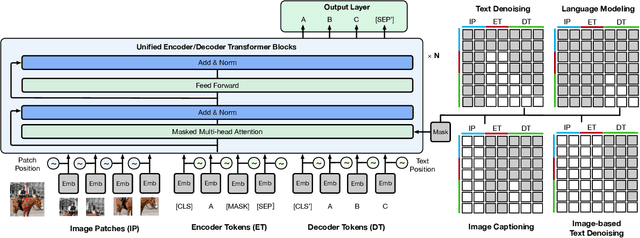
In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.