 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMoLM: Leveraging Visual and Geometric Structural Information for Molecule-Text Modeling
Jan 21, 2026AI models for drug discovery and chemical literature mining must interpret molecular images and generate outputs consistent with 3D geometry and stereochemistry. Most molecular language models rely on strings or graphs, while vision-language models often miss stereochemical details and struggle to map continuous 3D structures into discrete tokens. We propose DeepMoLM: Deep Molecular Language M odeling, a dual-view framework that grounds high-resolution molecular images in geometric invariants derived from molecular conformations. DeepMoLM preserves high-frequency evidence from 1024 $\times$ 1024 inputs, encodes conformer neighborhoods as discrete Extended 3-Dimensional Fingerprints, and fuses visual and geometric streams with cross-attention, enabling physically grounded generation without atom coordinates. DeepMoLM improves PubChem captioning with a 12.3% relative METEOR gain over the strongest generalist baseline while staying competitive with specialist methods. It produces valid numeric outputs for all property queries and attains MAE 13.64 g/mol on Molecular Weight and 37.89 on Complexity in the specialist setting. On ChEBI-20 description generation from images, it exceeds generalist baselines and matches state-of- the-art vision-language models. Code is available at https://github.com/1anj/DeepMoLM.
Structure-Aware Contrastive Learning with Fine-Grained Binding Representations for Drug Discovery
Sep 18, 2025



Accurate identification of drug-target interactions (DTI) remains a central challenge in computational pharmacology, where sequence-based methods offer scalability. This work introduces a sequence-based drug-target interaction framework that integrates structural priors into protein representations while maintaining high-throughput screening capability. Evaluated across multiple benchmarks, the model achieves state-of-the-art performance on Human and BioSNAP datasets and remains competitive on BindingDB. In virtual screening tasks, it surpasses prior methods on LIT-PCBA, yielding substantial gains in AUROC and BEDROC. Ablation studies confirm the critical role of learned aggregation, bilinear attention, and contrastive alignment in enhancing predictive robustness. Embedding visualizations reveal improved spatial correspondence with known binding pockets and highlight interpretable attention patterns over ligand-residue contacts. These results validate the framework's utility for scalable and structure-aware DTI prediction.
Minimum Tuning to Unlock Long Output from LLMs with High Quality Data as the Key
Oct 15, 2024As large language models rapidly evolve to support longer context, there is a notable disparity in their capability to generate output at greater lengths. Recent study suggests that the primary cause for this imbalance may arise from the lack of data with long-output during alignment training. In light of this observation, attempts are made to re-align foundation models with data that fills the gap, which result in models capable of generating lengthy output when instructed. In this paper, we explore the impact of data-quality in tuning a model for long output, and the possibility of doing so from the starting points of human-aligned (instruct or chat) models. With careful data curation, we show that it possible to achieve similar performance improvement in our tuned models, with only a small fraction of training data instances and compute. In addition, we assess the generalizability of such approaches by applying our tuning-recipes to several models. our findings suggest that, while capacities for generating long output vary across different models out-of-the-box, our approach to tune them with high-quality data using lite compute, consistently yields notable improvement across all models we experimented on. We have made public our curated dataset for tuning long-writing capability, the implementations of model tuning and evaluation, as well as the fine-tuned models, all of which can be openly-accessed.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024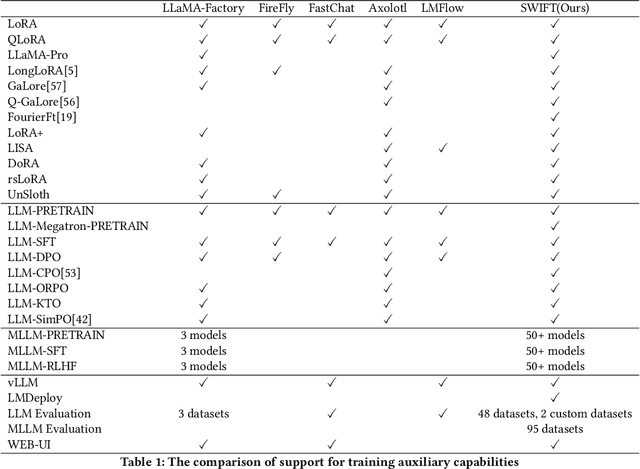
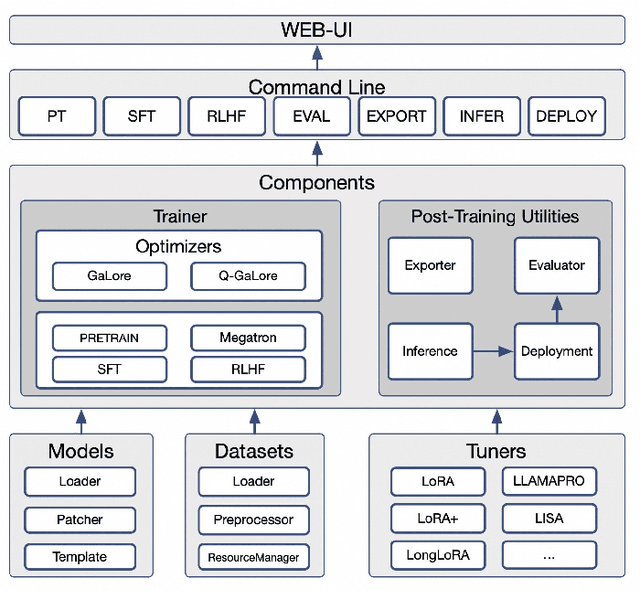


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
A Numerical Reasoning Question Answering System with Fine-grained Retriever and the Ensemble of Multiple Generators for FinQA
Jun 17, 2022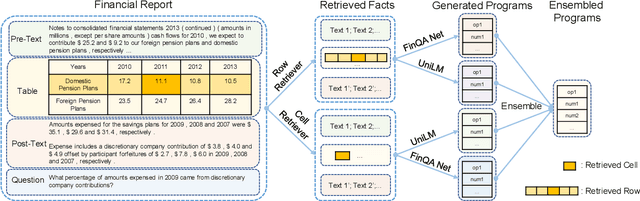


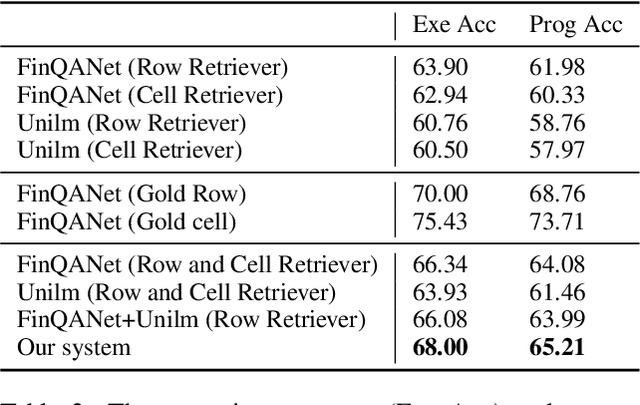
The numerical reasoning in the financial domain -- performing quantitative analysis and summarizing the information from financial reports -- can greatly increase business efficiency and reduce costs of billions of dollars. Here, we propose a numerical reasoning question answering system to answer numerical reasoning questions among financial text and table data sources, consisting of a retriever module, a generator module, and an ensemble module. Specifically, in the retriever module, in addition to retrieving the whole row data, we innovatively design a cell retriever that retrieves the gold cells to avoid bringing unrelated and similar cells in the same row to the inputs of the generator module. In the generator module, we utilize multiple generators to produce programs, which are operation steps to answer the question. Finally, in the ensemble module, we integrate multiple programs to choose the best program as the output of our system. In the final private test set in FinQA Competition, our system obtains 69.79 execution accuracy.