 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Weaver: Interleaved Multi-modal Generation via Decoupled Training
Mar 26, 2026Recent unified models have made unprecedented progress in both understanding and generation. However, while most of them accept multi-modal inputs, they typically produce only single-modality outputs. This challenge of producing interleaved content is mainly due to training data scarcity and the difficulty of modeling long-range cross-modal context. To address this issue, we decompose interleaved generation into textual planning and visual consistency modeling, and introduce a framework consisting of a planner and a visualizer. The planner produces dense textual descriptions for visual content, while the visualizer synthesizes images accordingly. Under this guidance, we construct large-scale textual-proxy interleaved data (where visual content is represented in text) to train the planner, and curate reference-guided image data to train the visualizer. These designs give rise to Wan-Weaver, which exhibits emergent interleaved generation ability with long-range textual coherence and visual consistency. Meanwhile, the integration of diverse understanding and generation data into planner training enables Wan-Weaver to achieve robust task reasoning and generation proficiency. To assess the model's capability in interleaved generation, we further construct a benchmark that spans a wide range of use cases across multiple dimensions. Extensive experiments demonstrate that, even without access to any real interleaved data, Wan-Weaver achieves superior performance over existing methods.
Unison: A Fully Automatic, Task-Universal, and Low-Cost Framework for Unified Understanding and Generation
Dec 08, 2025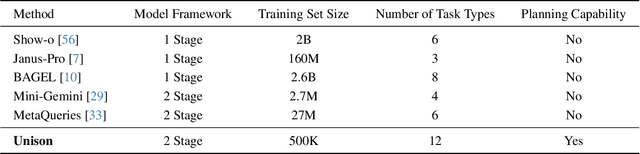
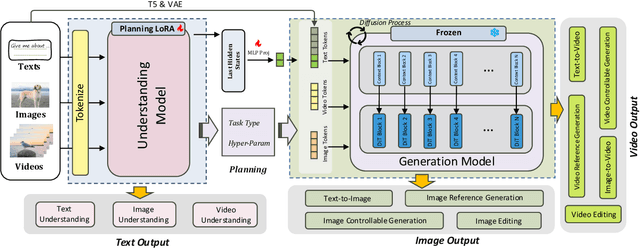


Unified understanding and generation is a highly appealing research direction in multimodal learning. There exist two approaches: one trains a transformer via an auto-regressive paradigm, and the other adopts a two-stage scheme connecting pre-trained understanding and generative models for alignment fine-tuning. The former demands massive data and computing resources unaffordable for ordinary researchers. Though the latter requires a lower training cost, existing works often suffer from limited task coverage or poor generation quality. Both approaches lack the ability to parse input meta-information (such as task type, image resolution, video duration, etc.) and require manual parameter configuration that is tedious and non-intelligent. In this paper, we propose Unison which adopts the two-stage scheme while preserving the capabilities of the pre-trained models well. With an extremely low training cost, we cover a variety of multimodal understanding tasks, including text, image, and video understanding, as well as diverse generation tasks, such as text-to-visual content generation, editing, controllable generation, and IP-based reference generation. We also equip our model with the ability to automatically parse user intentions, determine the target task type, and accurately extract the meta-information required for the corresponding task. This enables full automation of various multimodal tasks without human intervention. Experiments demonstrate that, under a low-cost setting of only 500k training samples and 50 GPU hours, our model can accurately and automatically identify tasks and extract relevant parameters, and achieve superior performance across a variety of understanding and generation tasks.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
ICE-Bench: A Unified and Comprehensive Benchmark for Image Creating and Editing
Mar 18, 2025Image generation has witnessed significant advancements in the past few years. However, evaluating the performance of image generation models remains a formidable challenge. In this paper, we propose ICE-Bench, a unified and comprehensive benchmark designed to rigorously assess image generation models. Its comprehensiveness could be summarized in the following key features: (1) Coarse-to-Fine Tasks: We systematically deconstruct image generation into four task categories: No-ref/Ref Image Creating/Editing, based on the presence or absence of source images and reference images. And further decompose them into 31 fine-grained tasks covering a broad spectrum of image generation requirements, culminating in a comprehensive benchmark. (2) Multi-dimensional Metrics: The evaluation framework assesses image generation capabilities across 6 dimensions: aesthetic quality, imaging quality, prompt following, source consistency, reference consistency, and controllability. 11 metrics are introduced to support the multi-dimensional evaluation. Notably, we introduce VLLM-QA, an innovative metric designed to assess the success of image editing by leveraging large models. (3) Hybrid Data: The data comes from real scenes and virtual generation, which effectively improves data diversity and alleviates the bias problem in model evaluation. Through ICE-Bench, we conduct a thorough analysis of existing generation models, revealing both the challenging nature of our benchmark and the gap between current model capabilities and real-world generation requirements. To foster further advancements in the field, we will open-source ICE-Bench, including its dataset, evaluation code, and models, thereby providing a valuable resource for the research community.
VACE: All-in-One Video Creation and Editing
Mar 11, 2025Diffusion Transformer has demonstrated powerful capability and scalability in generating high-quality images and videos. Further pursuing the unification of generation and editing tasks has yielded significant progress in the domain of image content creation. However, due to the intrinsic demands for consistency across both temporal and spatial dynamics, achieving a unified approach for video synthesis remains challenging. We introduce VACE, which enables users to perform Video tasks within an All-in-one framework for Creation and Editing. These tasks include reference-to-video generation, video-to-video editing, and masked video-to-video editing. Specifically, we effectively integrate the requirements of various tasks by organizing video task inputs, such as editing, reference, and masking, into a unified interface referred to as the Video Condition Unit (VCU). Furthermore, by utilizing a Context Adapter structure, we inject different task concepts into the model using formalized representations of temporal and spatial dimensions, allowing it to handle arbitrary video synthesis tasks flexibly. Extensive experiments demonstrate that the unified model of VACE achieves performance on par with task-specific models across various subtasks. Simultaneously, it enables diverse applications through versatile task combinations. Project page: https://ali-vilab.github.io/VACE-Page/.
ACE++: Instruction-Based Image Creation and Editing via Context-Aware Content Filling
Jan 07, 2025



We report ACE++, an instruction-based diffusion framework that tackles various image generation and editing tasks. Inspired by the input format for the inpainting task proposed by FLUX.1-Fill-dev, we improve the Long-context Condition Unit (LCU) introduced in ACE and extend this input paradigm to any editing and generation tasks. To take full advantage of image generative priors, we develop a two-stage training scheme to minimize the efforts of finetuning powerful text-to-image diffusion models like FLUX.1-dev. In the first stage, we pre-train the model using task data with the 0-ref tasks from the text-to-image model. There are many models in the community based on the post-training of text-to-image foundational models that meet this training paradigm of the first stage. For example, FLUX.1-Fill-dev deals primarily with painting tasks and can be used as an initialization to accelerate the training process. In the second stage, we finetune the above model to support the general instructions using all tasks defined in ACE. To promote the widespread application of ACE++ in different scenarios, we provide a comprehensive set of models that cover both full finetuning and lightweight finetuning, while considering general applicability and applicability in vertical scenarios. The qualitative analysis showcases the superiority of ACE++ in terms of generating image quality and prompt following ability. Code and models will be available on the project page: https://ali-vilab. github.io/ACE_plus_page/.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024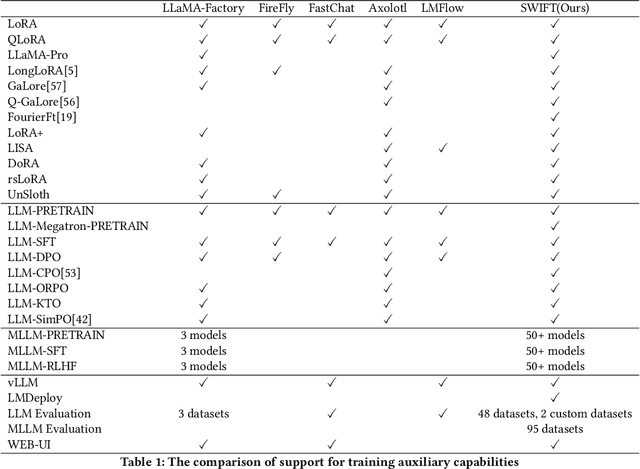
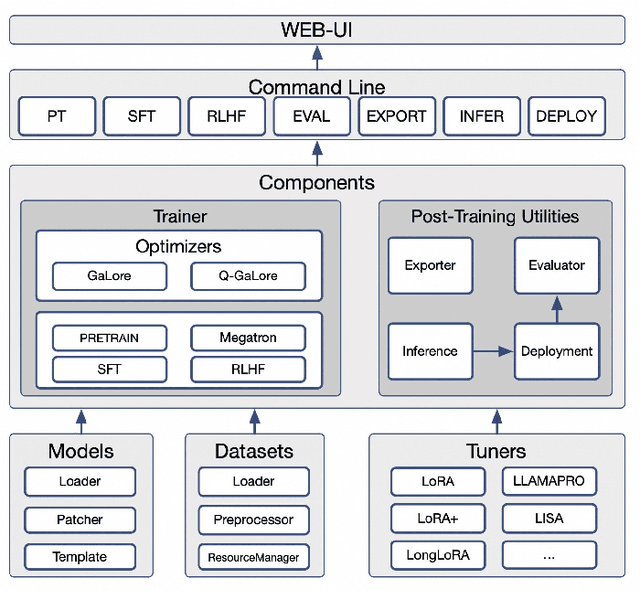


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
StyleBooth: Image Style Editing with Multimodal Instruction
Apr 18, 2024

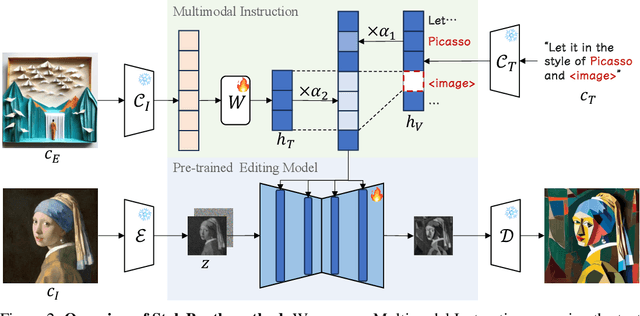

Given an original image, image editing aims to generate an image that align with the provided instruction. The challenges are to accept multimodal inputs as instructions and a scarcity of high-quality training data, including crucial triplets of source/target image pairs and multimodal (text and image) instructions. In this paper, we focus on image style editing and present StyleBooth, a method that proposes a comprehensive framework for image editing and a feasible strategy for building a high-quality style editing dataset. We integrate encoded textual instruction and image exemplar as a unified condition for diffusion model, enabling the editing of original image following multimodal instructions. Furthermore, by iterative style-destyle tuning and editing and usability filtering, the StyleBooth dataset provides content-consistent stylized/plain image pairs in various categories of styles. To show the flexibility of StyleBooth, we conduct experiments on diverse tasks, such as text-based style editing, exemplar-based style editing and compositional style editing. The results demonstrate that the quality and variety of training data significantly enhance the ability to preserve content and improve the overall quality of generated images in editing tasks. Project page can be found at https://ali-vilab.github.io/stylebooth-page/.
Locate, Assign, Refine: Taming Customized Image Inpainting with Text-Subject Guidance
Mar 28, 2024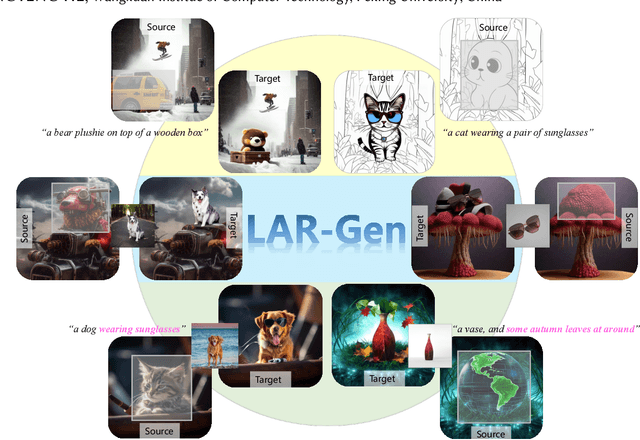
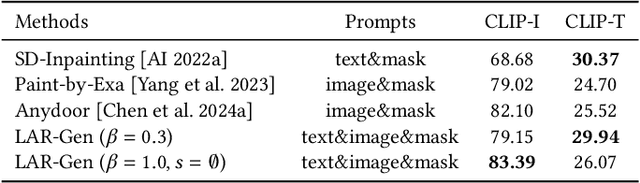
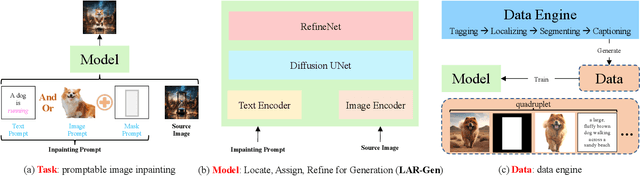
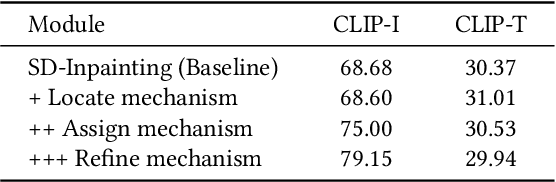
Prior studies have made significant progress in image inpainting guided by either text or subject image. However, the research on editing with their combined guidance is still in the early stages. To tackle this challenge, we present LAR-Gen, a novel approach for image inpainting that enables seamless inpainting of masked scene images, incorporating both the textual prompts and specified subjects. Our approach adopts a coarse-to-fine manner to ensure subject identity preservation and local semantic coherence. The process involves (i) Locate: concatenating the noise with masked scene image to achieve precise regional editing, (ii) Assign: employing decoupled cross-attention mechanism to accommodate multi-modal guidance, and (iii) Refine: using a novel RefineNet to supplement subject details. Additionally, to address the issue of scarce training data, we introduce a novel data construction pipeline. This pipeline extracts substantial pairs of data consisting of local text prompts and corresponding visual instances from a vast image dataset, leveraging publicly available large models. Extensive experiments and varied application scenarios demonstrate the superiority of LAR-Gen in terms of both identity preservation and text semantic consistency. Project page can be found at \url{https://ali-vilab.github.io/largen-page/}.
Res-Attn : An Enhanced Res-Tuning Approach with Lightweight Attention Mechanism
Dec 28, 2023Res-Tuning introduces a flexible and efficient paradigm for model tuning, showing that tuners decoupled from the backbone network can achieve performance comparable to traditional methods. Existing methods commonly construct the tuner as a set of trainable low-rank decomposition matrices, positing that a low-rank subspace suffices for adapting pre-trained foundational models to new scenarios. In this work, we present an advanced, efficient tuner augmented with low-rank attention, termed Res-Attn , which also adheres to the Res-Tuning framework. Res-Attn utilizes a parallel multi-head attention module equipped with low-rank projections for query, key, and value to execute streamlined attention operations. Through training this lightweight attention module, Res-Attn facilitates adaptation to new scenarios. Our extensive experiments across a range of discriminative and generative tasks showcase the superior performance of our method when compared to existing alternatives