 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Weaver: Interleaved Multi-modal Generation via Decoupled Training
Mar 26, 2026Recent unified models have made unprecedented progress in both understanding and generation. However, while most of them accept multi-modal inputs, they typically produce only single-modality outputs. This challenge of producing interleaved content is mainly due to training data scarcity and the difficulty of modeling long-range cross-modal context. To address this issue, we decompose interleaved generation into textual planning and visual consistency modeling, and introduce a framework consisting of a planner and a visualizer. The planner produces dense textual descriptions for visual content, while the visualizer synthesizes images accordingly. Under this guidance, we construct large-scale textual-proxy interleaved data (where visual content is represented in text) to train the planner, and curate reference-guided image data to train the visualizer. These designs give rise to Wan-Weaver, which exhibits emergent interleaved generation ability with long-range textual coherence and visual consistency. Meanwhile, the integration of diverse understanding and generation data into planner training enables Wan-Weaver to achieve robust task reasoning and generation proficiency. To assess the model's capability in interleaved generation, we further construct a benchmark that spans a wide range of use cases across multiple dimensions. Extensive experiments demonstrate that, even without access to any real interleaved data, Wan-Weaver achieves superior performance over existing methods.
Tutor-Student Reinforcement Learning: A Dynamic Curriculum for Robust Deepfake Detection
Mar 25, 2026Standard supervised training for deepfake detection treats all samples with uniform importance, which can be suboptimal for learning robust and generalizable features. In this work, we propose a novel Tutor-Student Reinforcement Learning (TSRL) framework to dynamically optimize the training curriculum. Our method models the training process as a Markov Decision Process where a ``Tutor'' agent learns to guide a ``Student'' (the deepfake detector). The Tutor, implemented as a Proximal Policy Optimization (PPO) agent, observes a rich state representation for each training sample, encapsulating not only its visual features but also its historical learning dynamics, such as EMA loss and forgetting counts. Based on this state, the Tutor takes an action by assigning a continuous weight (0-1) to the sample's loss, thereby dynamically re-weighting the training batch. The Tutor is rewarded based on the Student's immediate performance change, specifically rewarding transitions from incorrect to correct predictions. This strategy encourages the Tutor to learn a curriculum that prioritizes high-value samples, such as hard-but-learnable examples, leading to a more efficient and effective training process. We demonstrate that this adaptive curriculum improves the Student's generalization capabilities against unseen manipulation techniques compared to traditional training methods. Code is available at https://github.com/wannac1/TSRL.
* Accepted to CVPR 2026
Scalable Prompt Routing via Fine-Grained Latent Task Discovery
Mar 23, 2026Prompt routing dynamically selects the most appropriate large language model from a pool of candidates for each query, optimizing performance while managing costs. As model pools scale to include dozens of frontier models with narrow performance gaps, existing approaches face significant challenges: manually defined task taxonomies cannot capture fine-grained capability distinctions, while monolithic routers struggle to differentiate subtle differences across diverse tasks. We propose a two-stage routing architecture that addresses these limitations through automated fine-grained task discovery and task-aware quality estimation. Our first stage employs graph-based clustering to discover latent task types and trains a classifier to assign prompts to discovered tasks. The second stage uses a mixture-of-experts architecture with task-specific prediction heads for specialized quality estimates. At inference, we aggregate predictions from both stages to balance task-level stability with prompt-specific adaptability. Evaluated on 10 benchmarks with 11 frontier models, our method consistently outperforms existing baselines and surpasses the strongest individual model while incurring less than half its cost.
Train Less, Learn More: Adaptive Efficient Rollout Optimization for Group-Based Reinforcement Learning
Feb 15, 2026Reinforcement learning (RL) plays a central role in large language model (LLM) post-training. Among existing approaches, Group Relative Policy Optimization (GRPO) is widely used, especially for RL with verifiable rewards (RLVR) fine-tuning. In GRPO, each query prompts the LLM to generate a group of rollouts with a fixed group size $N$. When all rollouts in a group share the same outcome, either all correct or all incorrect, the group-normalized advantages become zero, yielding no gradient signal and wasting fine-tuning compute. We introduce Adaptive Efficient Rollout Optimization (AERO), an enhancement of GRPO. AERO uses an adaptive rollout strategy, applies selective rejection to strategically prune rollouts, and maintains a Bayesian posterior to prevent zero-advantage dead zones. Across three model configurations (Qwen2.5-Math-1.5B, Qwen2.5-7B, and Qwen2.5-7B-Instruct), AERO improves compute efficiency without sacrificing performance. Under the same total rollout budget, AERO reduces total training compute by about 48% while shortening wall-clock time per step by about 45% on average. Despite the substantial reduction in compute, AERO matches or improves Pass@8 and Avg@8 over GRPO, demonstrating a practical, scalable, and compute-efficient strategy for RL-based LLM alignment.
WebArbiter: A Principle-Guided Reasoning Process Reward Model for Web Agents
Jan 29, 2026Web agents hold great potential for automating complex computer tasks, yet their interactions involve long-horizon, sequential decision-making with irreversible actions. In such settings, outcome-based supervision is sparse and delayed, often rewarding incorrect trajectories and failing to support inference-time scaling. This motivates the use of Process Reward Models (WebPRMs) for web navigation, but existing approaches remain limited: scalar WebPRMs collapse progress into coarse, weakly grounded signals, while checklist-based WebPRMs rely on brittle template matching that fails under layout or semantic changes and often mislabels superficially correct actions as successful, providing little insight or interpretability. To address these challenges, we introduce WebArbiter, a reasoning-first, principle-inducing WebPRM that formulates reward modeling as text generation, producing structured justifications that conclude with a preference verdict and identify the action most conducive to task completion under the current context. Training follows a two-stage pipeline: reasoning distillation equips the model with coherent principle-guided reasoning, and reinforcement learning corrects teacher biases by directly aligning verdicts with correctness, enabling stronger generalization. To support systematic evaluation, we release WebPRMBench, a comprehensive benchmark spanning four diverse web environments with rich tasks and high-quality preference annotations. On WebPRMBench, WebArbiter-7B outperforms the strongest baseline, GPT-5, by 9.1 points. In reward-guided trajectory search on WebArena-Lite, it surpasses the best prior WebPRM by up to 7.2 points, underscoring its robustness and practical value in real-world complex web tasks.
SQL-Trail: Multi-Turn Reinforcement Learning with Interleaved Feedback for Text-to-SQL
Jan 25, 2026While large language models (LLMs) have substantially improved Text-to-SQL generation, a pronounced gap remains between AI systems and human experts on challenging benchmarks such as BIRD-SQL. We argue this gap stems largely from the prevailing single-pass paradigm, which lacks the iterative reasoning, schema exploration, and error-correction behaviors that humans naturally employ. To address this limitation, we introduce SQL-Trail, a multi-turn reinforcement learning (RL) agentic framework for Text-to-SQL. Rather than producing a query in one shot, SQL-Trail interacts with the database environment and uses execution feedback to iteratively refine its predictions. Our approach centers on two key ideas: (i) an adaptive turn-budget allocation mechanism that scales the agent's interaction depth to match question difficulty, and (ii) a composite reward panel that jointly incentivizes SQL correctness and efficient exploration. Across benchmarks, SQL-Trail sets a new state of the art and delivers strong data efficiency--up to 18x higher than prior single-pass RL state-of-the-art methods. Notably, our 7B and 14B models outperform substantially larger proprietary systems by 5% on average, underscoring the effectiveness of interactive, agentic workflows for robust Text-to-SQL generation.
Hierarchical Lexical Graph for Enhanced Multi-Hop Retrieval
Jun 09, 2025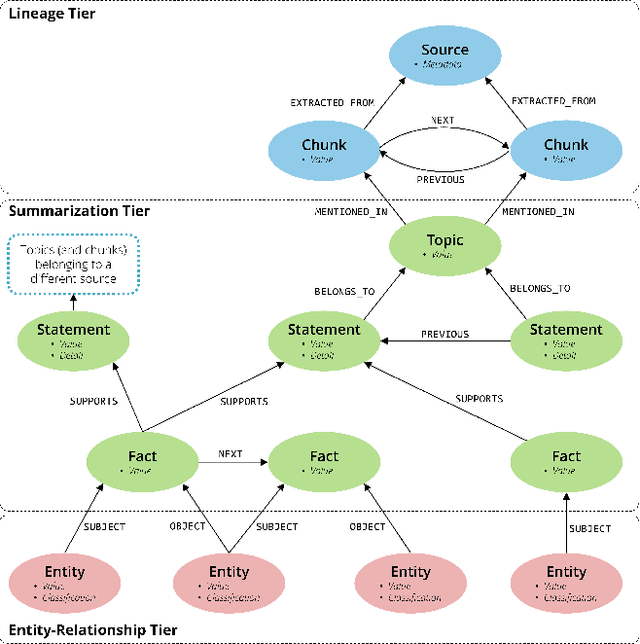

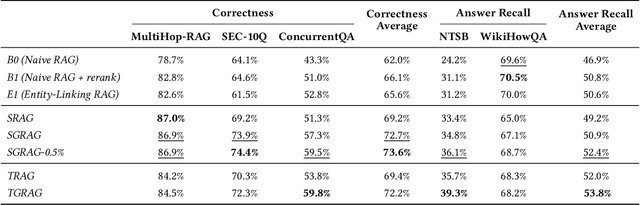
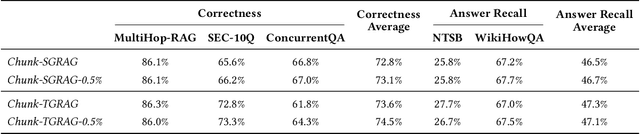
Retrieval-Augmented Generation (RAG) grounds large language models in external evidence, yet it still falters when answers must be pieced together across semantically distant documents. We close this gap with the Hierarchical Lexical Graph (HLG), a three-tier index that (i) traces every atomic proposition to its source, (ii) clusters propositions into latent topics, and (iii) links entities and relations to expose cross-document paths. On top of HLG we build two complementary, plug-and-play retrievers: StatementGraphRAG, which performs fine-grained entity-aware beam search over propositions for high-precision factoid questions, and TopicGraphRAG, which selects coarse topics before expanding along entity links to supply broad yet relevant context for exploratory queries. Additionally, existing benchmarks lack the complexity required to rigorously evaluate multi-hop summarization systems, often focusing on single-document queries or limited datasets. To address this, we introduce a synthetic dataset generation pipeline that curates realistic, multi-document question-answer pairs, enabling robust evaluation of multi-hop retrieval systems. Extensive experiments across five datasets demonstrate that our methods outperform naive chunk-based RAG achieving an average relative improvement of 23.1% in retrieval recall and correctness. Open-source Python library is available at https://github.com/awslabs/graphrag-toolkit.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
ICE-Bench: A Unified and Comprehensive Benchmark for Image Creating and Editing
Mar 18, 2025Image generation has witnessed significant advancements in the past few years. However, evaluating the performance of image generation models remains a formidable challenge. In this paper, we propose ICE-Bench, a unified and comprehensive benchmark designed to rigorously assess image generation models. Its comprehensiveness could be summarized in the following key features: (1) Coarse-to-Fine Tasks: We systematically deconstruct image generation into four task categories: No-ref/Ref Image Creating/Editing, based on the presence or absence of source images and reference images. And further decompose them into 31 fine-grained tasks covering a broad spectrum of image generation requirements, culminating in a comprehensive benchmark. (2) Multi-dimensional Metrics: The evaluation framework assesses image generation capabilities across 6 dimensions: aesthetic quality, imaging quality, prompt following, source consistency, reference consistency, and controllability. 11 metrics are introduced to support the multi-dimensional evaluation. Notably, we introduce VLLM-QA, an innovative metric designed to assess the success of image editing by leveraging large models. (3) Hybrid Data: The data comes from real scenes and virtual generation, which effectively improves data diversity and alleviates the bias problem in model evaluation. Through ICE-Bench, we conduct a thorough analysis of existing generation models, revealing both the challenging nature of our benchmark and the gap between current model capabilities and real-world generation requirements. To foster further advancements in the field, we will open-source ICE-Bench, including its dataset, evaluation code, and models, thereby providing a valuable resource for the research community.
VACE: All-in-One Video Creation and Editing
Mar 11, 2025Diffusion Transformer has demonstrated powerful capability and scalability in generating high-quality images and videos. Further pursuing the unification of generation and editing tasks has yielded significant progress in the domain of image content creation. However, due to the intrinsic demands for consistency across both temporal and spatial dynamics, achieving a unified approach for video synthesis remains challenging. We introduce VACE, which enables users to perform Video tasks within an All-in-one framework for Creation and Editing. These tasks include reference-to-video generation, video-to-video editing, and masked video-to-video editing. Specifically, we effectively integrate the requirements of various tasks by organizing video task inputs, such as editing, reference, and masking, into a unified interface referred to as the Video Condition Unit (VCU). Furthermore, by utilizing a Context Adapter structure, we inject different task concepts into the model using formalized representations of temporal and spatial dimensions, allowing it to handle arbitrary video synthesis tasks flexibly. Extensive experiments demonstrate that the unified model of VACE achieves performance on par with task-specific models across various subtasks. Simultaneously, it enables diverse applications through versatile task combinations. Project page: https://ali-vilab.github.io/VACE-Page/.