 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Less, Learn More: Adaptive Efficient Rollout Optimization for Group-Based Reinforcement Learning
Feb 15, 2026Reinforcement learning (RL) plays a central role in large language model (LLM) post-training. Among existing approaches, Group Relative Policy Optimization (GRPO) is widely used, especially for RL with verifiable rewards (RLVR) fine-tuning. In GRPO, each query prompts the LLM to generate a group of rollouts with a fixed group size $N$. When all rollouts in a group share the same outcome, either all correct or all incorrect, the group-normalized advantages become zero, yielding no gradient signal and wasting fine-tuning compute. We introduce Adaptive Efficient Rollout Optimization (AERO), an enhancement of GRPO. AERO uses an adaptive rollout strategy, applies selective rejection to strategically prune rollouts, and maintains a Bayesian posterior to prevent zero-advantage dead zones. Across three model configurations (Qwen2.5-Math-1.5B, Qwen2.5-7B, and Qwen2.5-7B-Instruct), AERO improves compute efficiency without sacrificing performance. Under the same total rollout budget, AERO reduces total training compute by about 48% while shortening wall-clock time per step by about 45% on average. Despite the substantial reduction in compute, AERO matches or improves Pass@8 and Avg@8 over GRPO, demonstrating a practical, scalable, and compute-efficient strategy for RL-based LLM alignment.
HybGRAG: Hybrid Retrieval-Augmented Generation on Textual and Relational Knowledge Bases
Dec 20, 2024



Given a semi-structured knowledge base (SKB), where text documents are interconnected by relations, how can we effectively retrieve relevant information to answer user questions? Retrieval-Augmented Generation (RAG) retrieves documents to assist large language models (LLMs) in question answering; while Graph RAG (GRAG) uses structured knowledge bases as its knowledge source. However, many questions require both textual and relational information from SKB - referred to as "hybrid" questions - which complicates the retrieval process and underscores the need for a hybrid retrieval method that leverages both information. In this paper, through our empirical analysis, we identify key insights that show why existing methods may struggle with hybrid question answering (HQA) over SKB. Based on these insights, we propose HybGRAG for HQA consisting of a retriever bank and a critic module, with the following advantages: (1) Agentic, it automatically refines the output by incorporating feedback from the critic module, (2) Adaptive, it solves hybrid questions requiring both textual and relational information with the retriever bank, (3) Interpretable, it justifies decision making with intuitive refinement path, and (4) Effective, it surpasses all baselines on HQA benchmarks. In experiments on the STaRK benchmark, HybGRAG achieves significant performance gains, with an average relative improvement in Hit@1 of 51%.
GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning
May 30, 2024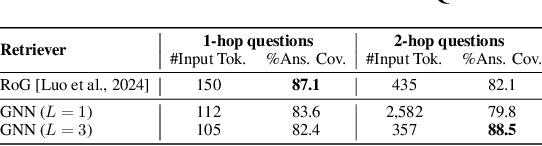
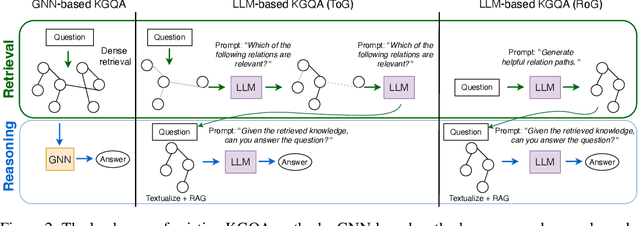
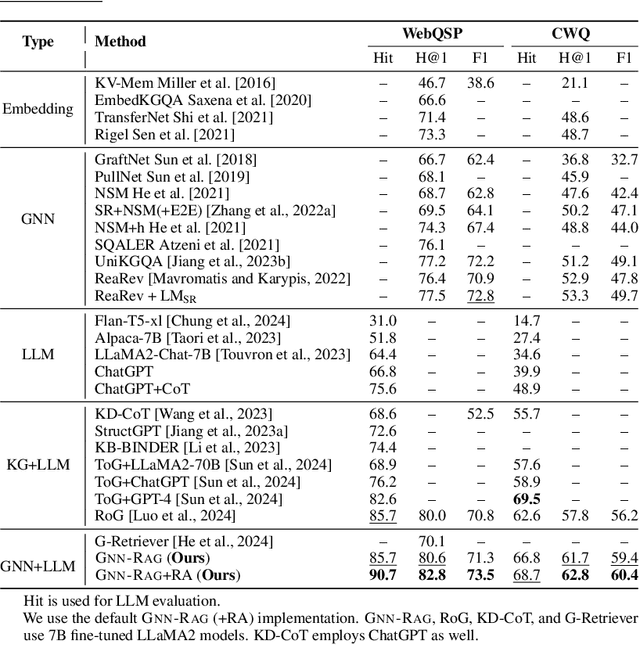

Knowledge Graphs (KGs) represent human-crafted factual knowledge in the form of triplets (head, relation, tail), which collectively form a graph. Question Answering over KGs (KGQA) is the task of answering natural questions grounding the reasoning to the information provided by the KG. Large Language Models (LLMs) are the state-of-the-art models for QA tasks due to their remarkable ability to understand natural language. On the other hand, Graph Neural Networks (GNNs) have been widely used for KGQA as they can handle the complex graph information stored in the KG. In this work, we introduce GNN-RAG, a novel method for combining language understanding abilities of LLMs with the reasoning abilities of GNNs in a retrieval-augmented generation (RAG) style. First, a GNN reasons over a dense KG subgraph to retrieve answer candidates for a given question. Second, the shortest paths in the KG that connect question entities and answer candidates are extracted to represent KG reasoning paths. The extracted paths are verbalized and given as input for LLM reasoning with RAG. In our GNN-RAG framework, the GNN acts as a dense subgraph reasoner to extract useful graph information, while the LLM leverages its natural language processing ability for ultimate KGQA. Furthermore, we develop a retrieval augmentation (RA) technique to further boost KGQA performance with GNN-RAG. Experimental results show that GNN-RAG achieves state-of-the-art performance in two widely used KGQA benchmarks (WebQSP and CWQ), outperforming or matching GPT-4 performance with a 7B tuned LLM. In addition, GNN-RAG excels on multi-hop and multi-entity questions outperforming competing approaches by 8.9--15.5% points at answer F1.
Pack of LLMs: Model Fusion at Test-Time via Perplexity Optimization
Apr 17, 2024Fusing knowledge from multiple Large Language Models (LLMs) can combine their diverse strengths to achieve improved performance on a given task. However, current fusion approaches either rely on learning-based fusers that do not generalize to new LLMs, or do not take into account how well each LLM understands the input. In this work, we study LLM fusion at test-time, which enables leveraging knowledge from arbitrary user-specified LLMs during inference. We introduce Pack of LLMs (PackLLM), an effective method for test-time fusion that leverages each LLM's expertise, given an input prompt. PackLLM performs model fusion by solving an optimization problem for determining each LLM's importance, so that perplexity over the input prompt is minimized. First, our simple PackLLM-sim variant validates that perplexity is a good indicator for measuring each LLM's expertise. Second, our PackLLM-opt variant approximately solves the perplexity minimization problem via a greedy algorithm. The derived importance weights are used to combine the LLMs during inference. We conduct experiments with over 100 total LLMs on a diverse set of tasks. Experimental results show that (i) perplexity is a reliable measure for LLM fusion, (ii) PackLLM outperforms test-time fusion baselines by 1.89% accuracy points, and (iii) PackLLM can leverage new LLMs to improve performance over learning-based fusion approaches by 3.92-11.94% accuracy points.
SemPool: Simple, robust, and interpretable KG pooling for enhancing language models
Feb 03, 2024Knowledge Graph (KG) powered question answering (QA) performs complex reasoning over language semantics as well as knowledge facts. Graph Neural Networks (GNNs) learn to aggregate information from the underlying KG, which is combined with Language Models (LMs) for effective reasoning with the given question. However, GNN-based methods for QA rely on the graph information of the candidate answer nodes, which limits their effectiveness in more challenging settings where critical answer information is not included in the KG. We propose a simple graph pooling approach that learns useful semantics of the KG that can aid the LM's reasoning and that its effectiveness is robust under graph perturbations. Our method, termed SemPool, represents KG facts with pre-trained LMs, learns to aggregate their semantic information, and fuses it at different layers of the LM. Our experimental results show that SemPool outperforms state-of-the-art GNN-based methods by 2.27% accuracy points on average when answer information is missing from the KG. In addition, SemPool offers interpretability on what type of graph information is fused at different LM layers.
Which Examples to Annotate for In-Context Learning? Towards Effective and Efficient Selection
Oct 30, 2023Large Language Models (LLMs) can adapt to new tasks via in-context learning (ICL). ICL is efficient as it does not require any parameter updates to the trained LLM, but only few annotated examples as input for the LLM. In this work, we investigate an active learning approach for ICL, where there is a limited budget for annotating examples. We propose a model-adaptive optimization-free algorithm, termed AdaICL, which identifies examples that the model is uncertain about, and performs semantic diversity-based example selection. Diversity-based sampling improves overall effectiveness, while uncertainty sampling improves budget efficiency and helps the LLM learn new information. Moreover, AdaICL poses its sampling strategy as a Maximum Coverage problem, that dynamically adapts based on the model's feedback and can be approximately solved via greedy algorithms. Extensive experiments on nine datasets and seven LLMs show that AdaICL improves performance by 4.4% accuracy points over SOTA (7.7% relative improvement), is up to 3x more budget-efficient than performing annotations uniformly at random, while it outperforms SOTA with 2x fewer ICL examples.
Train Your Own GNN Teacher: Graph-Aware Distillation on Textual Graphs
Apr 20, 2023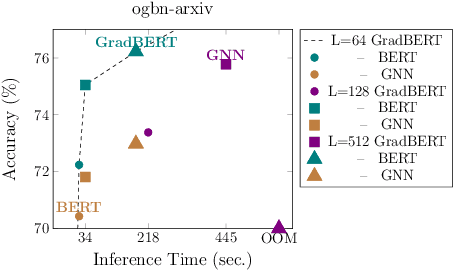
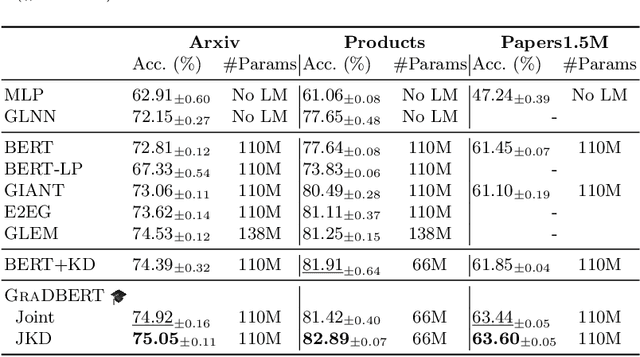
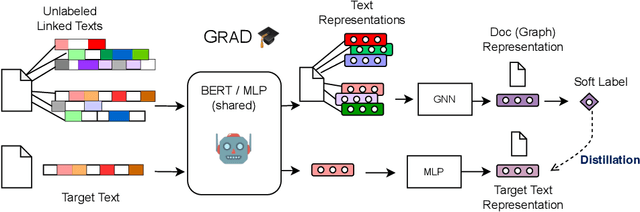

How can we learn effective node representations on textual graphs? Graph Neural Networks (GNNs) that use Language Models (LMs) to encode textual information of graphs achieve state-of-the-art performance in many node classification tasks. Yet, combining GNNs with LMs has not been widely explored for practical deployments due to its scalability issues. In this work, we tackle this challenge by developing a Graph-Aware Distillation framework (GRAD) to encode graph structures into an LM for graph-free, fast inference. Different from conventional knowledge distillation, GRAD jointly optimizes a GNN teacher and a graph-free student over the graph's nodes via a shared LM. This encourages the graph-free student to exploit graph information encoded by the GNN teacher while at the same time, enables the GNN teacher to better leverage textual information from unlabeled nodes. As a result, the teacher and the student models learn from each other to improve their overall performance. Experiments in eight node classification benchmarks in both transductive and inductive settings showcase GRAD's superiority over existing distillation approaches for textual graphs.
ReaRev: Adaptive Reasoning for Question Answering over Knowledge Graphs
Oct 24, 2022Knowledge Graph Question Answering (KGQA) involves retrieving entities as answers from a Knowledge Graph (KG) using natural language queries. The challenge is to learn to reason over question-relevant KG facts that traverse KG entities and lead to the question answers. To facilitate reasoning, the question is decoded into instructions, which are dense question representations used to guide the KG traversals. However, if the derived instructions do not exactly match the underlying KG information, they may lead to reasoning under irrelevant context. Our method, termed ReaRev, introduces a new way to KGQA reasoning with respect to both instruction decoding and execution. To improve instruction decoding, we perform reasoning in an adaptive manner, where KG-aware information is used to iteratively update the initial instructions. To improve instruction execution, we emulate breadth-first search (BFS) with graph neural networks (GNNs). The BFS strategy treats the instructions as a set and allows our method to decide on their execution order on the fly. Experimental results on three KGQA benchmarks demonstrate the ReaRev's effectiveness compared with previous state-of-the-art, especially when the KG is incomplete or when we tackle complex questions. Our code is publicly available at https://github.com/cmavro/ReaRev_KGQA.
TempoQR: Temporal Question Reasoning over Knowledge Graphs
Dec 10, 2021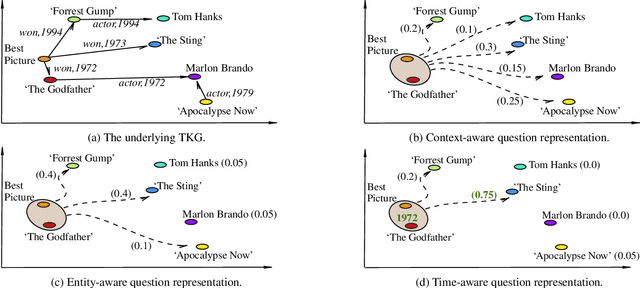

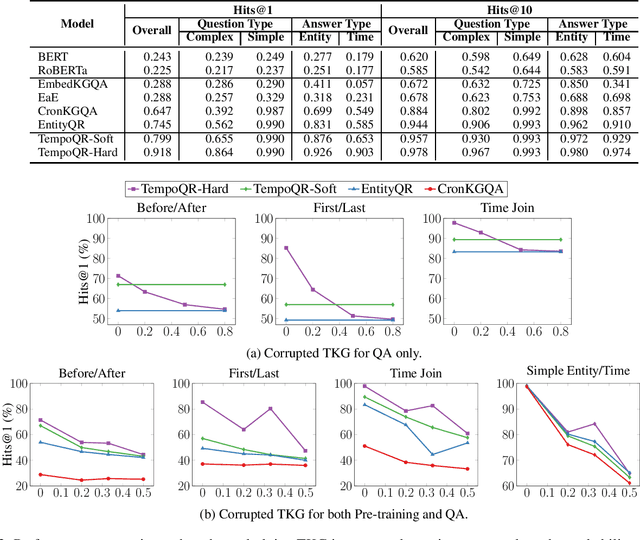
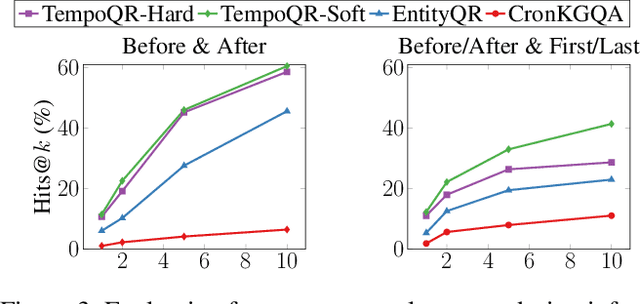
Knowledge Graph Question Answering (KGQA) involves retrieving facts from a Knowledge Graph (KG) using natural language queries. A KG is a curated set of facts consisting of entities linked by relations. Certain facts include also temporal information forming a Temporal KG (TKG). Although many natural questions involve explicit or implicit time constraints, question answering (QA) over TKGs has been a relatively unexplored area. Existing solutions are mainly designed for simple temporal questions that can be answered directly by a single TKG fact. This paper puts forth a comprehensive embedding-based framework for answering complex questions over TKGs. Our method termed temporal question reasoning (TempoQR) exploits TKG embeddings to ground the question to the specific entities and time scope it refers to. It does so by augmenting the question embeddings with context, entity and time-aware information by employing three specialized modules. The first computes a textual representation of a given question, the second combines it with the entity embeddings for entities involved in the question, and the third generates question-specific time embeddings. Finally, a transformer-based encoder learns to fuse the generated temporal information with the question representation, which is used for answer predictions. Extensive experiments show that TempoQR improves accuracy by 25--45 percentage points on complex temporal questions over state-of-the-art approaches and it generalizes better to unseen question types.
HeMI: Multi-view Embedding in Heterogeneous Graphs
Sep 14, 2021
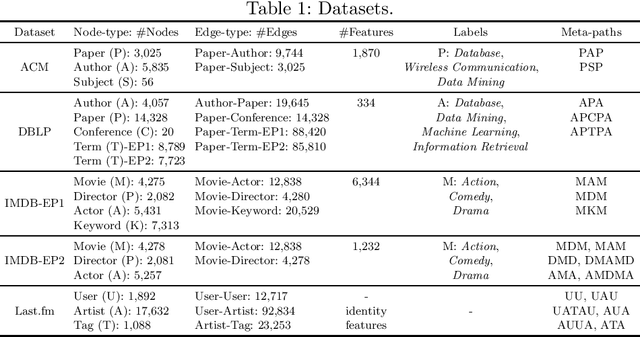
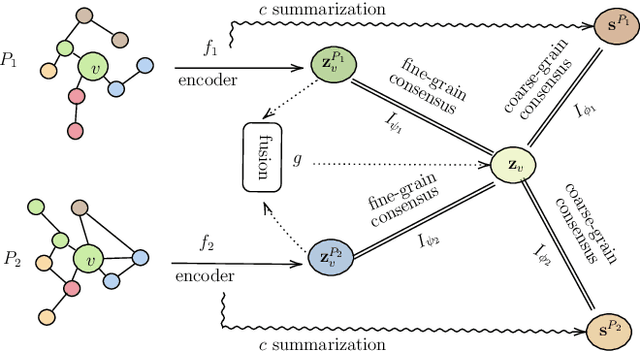
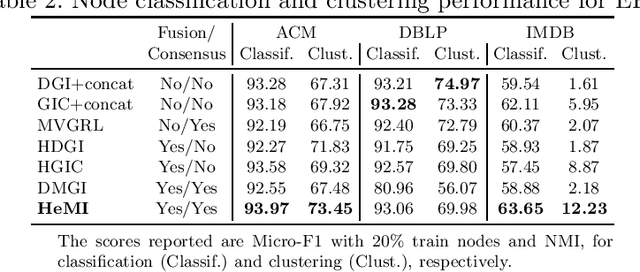
Many real-world graphs involve different types of nodes and relations between nodes, being heterogeneous by nature. The representation learning of heterogeneous graphs (HGs) embeds the rich structure and semantics of such graphs into a low-dimensional space and facilitates various data mining tasks, such as node classification, node clustering, and link prediction. In this paper, we propose a self-supervised method that learns HG representations by relying on knowledge exchange and discovery among different HG structural semantics (meta-paths). Specifically, by maximizing the mutual information of meta-path representations, we promote meta-path information fusion and consensus, and ensure that globally shared semantics are encoded. By extensive experiments on node classification, node clustering, and link prediction tasks, we show that the proposed self-supervision both outperforms and improves competing methods by 1% and up to 10% for all tasks.