 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Prompt Routing via Fine-Grained Latent Task Discovery
Mar 23, 2026Prompt routing dynamically selects the most appropriate large language model from a pool of candidates for each query, optimizing performance while managing costs. As model pools scale to include dozens of frontier models with narrow performance gaps, existing approaches face significant challenges: manually defined task taxonomies cannot capture fine-grained capability distinctions, while monolithic routers struggle to differentiate subtle differences across diverse tasks. We propose a two-stage routing architecture that addresses these limitations through automated fine-grained task discovery and task-aware quality estimation. Our first stage employs graph-based clustering to discover latent task types and trains a classifier to assign prompts to discovered tasks. The second stage uses a mixture-of-experts architecture with task-specific prediction heads for specialized quality estimates. At inference, we aggregate predictions from both stages to balance task-level stability with prompt-specific adaptability. Evaluated on 10 benchmarks with 11 frontier models, our method consistently outperforms existing baselines and surpasses the strongest individual model while incurring less than half its cost.
Hierarchical Lexical Graph for Enhanced Multi-Hop Retrieval
Jun 09, 2025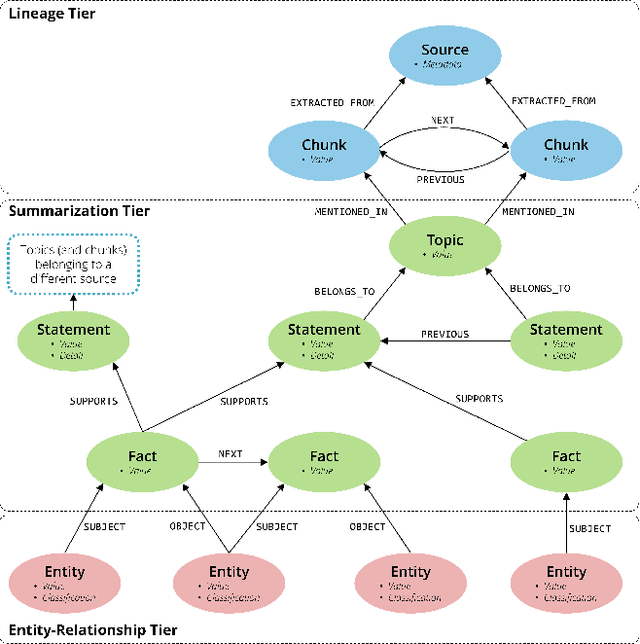

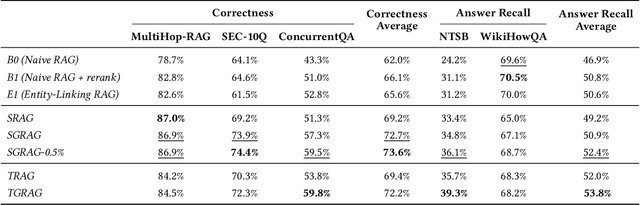
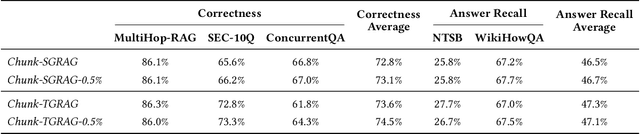
Retrieval-Augmented Generation (RAG) grounds large language models in external evidence, yet it still falters when answers must be pieced together across semantically distant documents. We close this gap with the Hierarchical Lexical Graph (HLG), a three-tier index that (i) traces every atomic proposition to its source, (ii) clusters propositions into latent topics, and (iii) links entities and relations to expose cross-document paths. On top of HLG we build two complementary, plug-and-play retrievers: StatementGraphRAG, which performs fine-grained entity-aware beam search over propositions for high-precision factoid questions, and TopicGraphRAG, which selects coarse topics before expanding along entity links to supply broad yet relevant context for exploratory queries. Additionally, existing benchmarks lack the complexity required to rigorously evaluate multi-hop summarization systems, often focusing on single-document queries or limited datasets. To address this, we introduce a synthetic dataset generation pipeline that curates realistic, multi-document question-answer pairs, enabling robust evaluation of multi-hop retrieval systems. Extensive experiments across five datasets demonstrate that our methods outperform naive chunk-based RAG achieving an average relative improvement of 23.1% in retrieval recall and correctness. Open-source Python library is available at https://github.com/awslabs/graphrag-toolkit.
HybGRAG: Hybrid Retrieval-Augmented Generation on Textual and Relational Knowledge Bases
Dec 20, 2024



Given a semi-structured knowledge base (SKB), where text documents are interconnected by relations, how can we effectively retrieve relevant information to answer user questions? Retrieval-Augmented Generation (RAG) retrieves documents to assist large language models (LLMs) in question answering; while Graph RAG (GRAG) uses structured knowledge bases as its knowledge source. However, many questions require both textual and relational information from SKB - referred to as "hybrid" questions - which complicates the retrieval process and underscores the need for a hybrid retrieval method that leverages both information. In this paper, through our empirical analysis, we identify key insights that show why existing methods may struggle with hybrid question answering (HQA) over SKB. Based on these insights, we propose HybGRAG for HQA consisting of a retriever bank and a critic module, with the following advantages: (1) Agentic, it automatically refines the output by incorporating feedback from the critic module, (2) Adaptive, it solves hybrid questions requiring both textual and relational information with the retriever bank, (3) Interpretable, it justifies decision making with intuitive refinement path, and (4) Effective, it surpasses all baselines on HQA benchmarks. In experiments on the STaRK benchmark, HybGRAG achieves significant performance gains, with an average relative improvement in Hit@1 of 51%.
AvaTaR: Optimizing LLM Agents for Tool-Assisted Knowledge Retrieval
Jun 18, 2024



Large language model (LLM) agents have demonstrated impressive capability in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing the prompting techniques that make LLM agents able to effectively use external tools and knowledge is a heuristic and laborious task. Here, we introduce AvaTaR, a novel and automatic framework that optimizes an LLM agent to effectively use the provided tools and improve its performance on a given task/domain. During optimization, we design a comparator module to iteratively provide insightful and holistic prompts to the LLM agent via reasoning between positive and negative examples sampled from training data. We demonstrate AvaTaR on four complex multimodal retrieval datasets featuring textual, visual, and relational information. We find AvaTaR consistently outperforms state-of-the-art approaches across all four challenging tasks and exhibits strong generalization ability when applied to novel cases, achieving an average relative improvement of 14% on the Hit@1 metric. Code and dataset are available at https://github.com/zou-group/avatar.
Context-Aware Clustering using Large Language Models
May 02, 2024Despite the remarkable success of Large Language Models (LLMs) in text understanding and generation, their potential for text clustering tasks remains underexplored. We observed that powerful closed-source LLMs provide good quality clusterings of entity sets but are not scalable due to the massive compute power required and the associated costs. Thus, we propose CACTUS (Context-Aware ClusTering with aUgmented triplet losS), a systematic approach that leverages open-source LLMs for efficient and effective supervised clustering of entity subsets, particularly focusing on text-based entities. Existing text clustering methods fail to effectively capture the context provided by the entity subset. Moreover, though there are several language modeling based approaches for clustering, very few are designed for the task of supervised clustering. This paper introduces a novel approach towards clustering entity subsets using LLMs by capturing context via a scalable inter-entity attention mechanism. We propose a novel augmented triplet loss function tailored for supervised clustering, which addresses the inherent challenges of directly applying the triplet loss to this problem. Furthermore, we introduce a self-supervised clustering task based on text augmentation techniques to improve the generalization of our model. For evaluation, we collect ground truth clusterings from a closed-source LLM and transfer this knowledge to an open-source LLM under the supervised clustering framework, allowing a faster and cheaper open-source model to perform the same task. Experiments on various e-commerce query and product clustering datasets demonstrate that our proposed approach significantly outperforms existing unsupervised and supervised baselines under various external clustering evaluation metrics.
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases
Apr 19, 2024



Answering real-world user queries, such as product search, often requires accurate retrieval of information from semi-structured knowledge bases or databases that involve blend of unstructured (e.g., textual descriptions of products) and structured (e.g., entity relations of products) information. However, previous works have mostly studied textual and relational retrieval tasks as separate topics. To address the gap, we develop STARK, a large-scale Semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. We design a novel pipeline to synthesize natural and realistic user queries that integrate diverse relational information and complex textual properties, as well as their ground-truth answers. Moreover, we rigorously conduct human evaluation to validate the quality of our benchmark, which covers a variety of practical applications, including product recommendations, academic paper searches, and precision medicine inquiries. Our benchmark serves as a comprehensive testbed for evaluating the performance of retrieval systems, with an emphasis on retrieval approaches driven by large language models (LLMs). Our experiments suggest that the STARK datasets present significant challenges to the current retrieval and LLM systems, indicating the demand for building more capable retrieval systems that can handle both textual and relational aspects.
NetInfoF Framework: Measuring and Exploiting Network Usable Information
Feb 12, 2024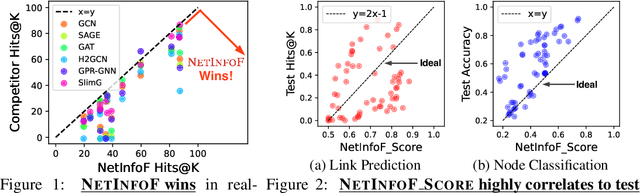
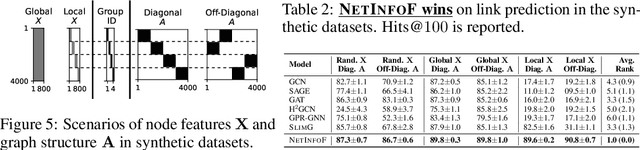
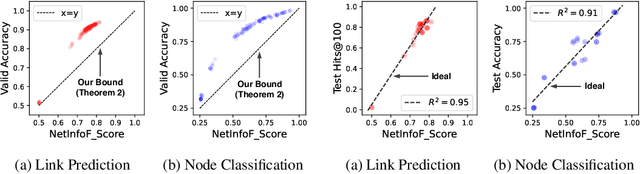

Given a node-attributed graph, and a graph task (link prediction or node classification), can we tell if a graph neural network (GNN) will perform well? More specifically, do the graph structure and the node features carry enough usable information for the task? Our goals are (1) to develop a fast tool to measure how much information is in the graph structure and in the node features, and (2) to exploit the information to solve the task, if there is enough. We propose NetInfoF, a framework including NetInfoF_Probe and NetInfoF_Act, for the measurement and the exploitation of network usable information (NUI), respectively. Given a graph data, NetInfoF_Probe measures NUI without any model training, and NetInfoF_Act solves link prediction and node classification, while two modules share the same backbone. In summary, NetInfoF has following notable advantages: (a) General, handling both link prediction and node classification; (b) Principled, with theoretical guarantee and closed-form solution; (c) Effective, thanks to the proposed adjustment to node similarity; (d) Scalable, scaling linearly with the input size. In our carefully designed synthetic datasets, NetInfoF correctly identifies the ground truth of NUI and is the only method being robust to all graph scenarios. Applied on real-world datasets, NetInfoF wins in 11 out of 12 times on link prediction compared to general GNN baselines.
BioBridge: Bridging Biomedical Foundation Models via Knowledge Graph
Oct 12, 2023Foundation models (FMs) are able to leverage large volumes of unlabeled data to demonstrate superior performance across a wide range of tasks. However, FMs developed for biomedical domains have largely remained unimodal, i.e., independently trained and used for tasks on protein sequences alone, small molecule structures alone, or clinical data alone. To overcome this limitation of biomedical FMs, we present BioBridge, a novel parameter-efficient learning framework, to bridge independently trained unimodal FMs to establish multimodal behavior. BioBridge achieves it by utilizing Knowledge Graphs (KG) to learn transformations between one unimodal FM and another without fine-tuning any underlying unimodal FMs. Our empirical results demonstrate that BioBridge can beat the best baseline KG embedding methods (on average by around 76.3%) in cross-modal retrieval tasks. We also identify BioBridge demonstrates out-of-domain generalization ability by extrapolating to unseen modalities or relations. Additionally, we also show that BioBridge presents itself as a general purpose retriever that can aid biomedical multimodal question answering as well as enhance the guided generation of novel drugs.
TouchUp-G: Improving Feature Representation through Graph-Centric Finetuning
Sep 25, 2023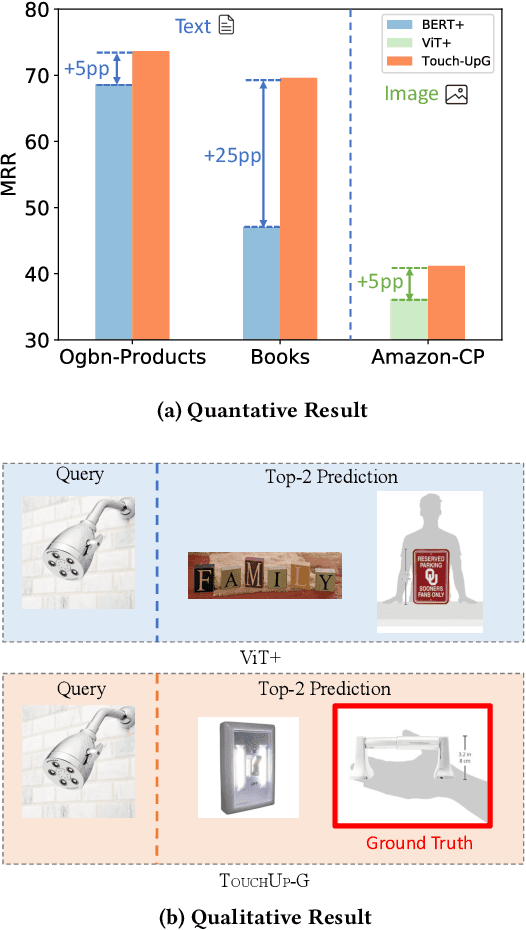
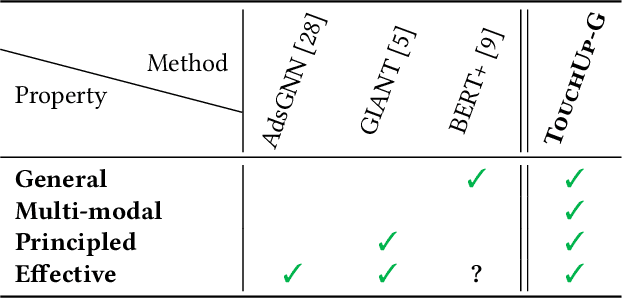

How can we enhance the node features acquired from Pretrained Models (PMs) to better suit downstream graph learning tasks? Graph Neural Networks (GNNs) have become the state-of-the-art approach for many high-impact, real-world graph applications. For feature-rich graphs, a prevalent practice involves utilizing a PM directly to generate features, without incorporating any domain adaptation techniques. Nevertheless, this practice is suboptimal because the node features extracted from PM are graph-agnostic and prevent GNNs from fully utilizing the potential correlations between the graph structure and node features, leading to a decline in GNNs performance. In this work, we seek to improve the node features obtained from a PM for downstream graph tasks and introduce TOUCHUP-G, which has several advantages. It is (a) General: applicable to any downstream graph task, including link prediction which is often employed in recommender systems; (b) Multi-modal: able to improve raw features of any modality (e.g. images, texts, audio); (c) Principled: it is closely related to a novel metric, feature homophily, which we propose to quantify the potential correlations between the graph structure and node features and we show that TOUCHUP-G can effectively shrink the discrepancy between the graph structure and node features; (d) Effective: achieving state-of-the-art results on four real-world datasets spanning different tasks and modalities.
Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
Jun 05, 2023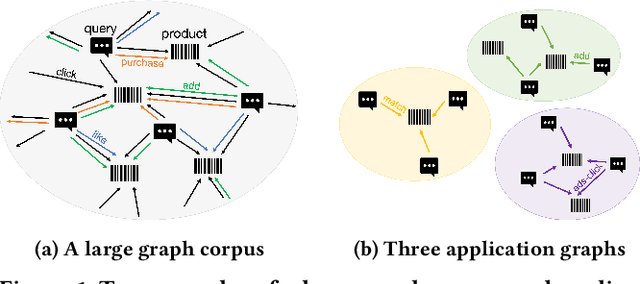
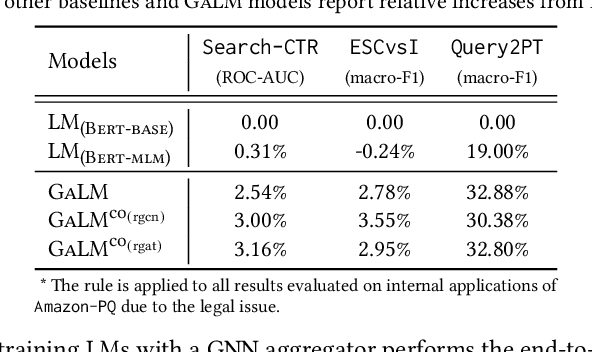
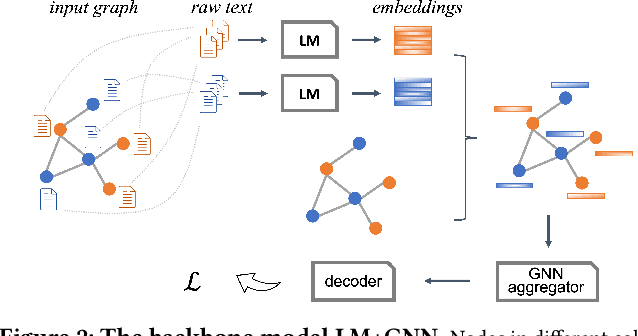
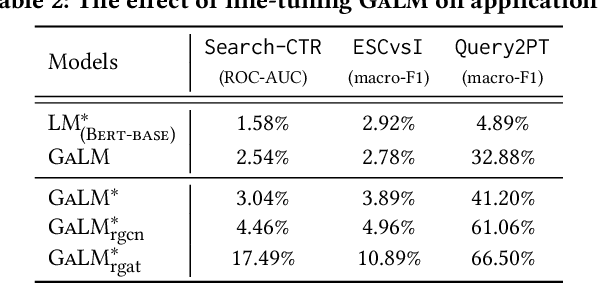
Model pre-training on large text corpora has been demonstrated effective for various downstream applications in the NLP domain. In the graph mining domain, a similar analogy can be drawn for pre-training graph models on large graphs in the hope of benefiting downstream graph applications, which has also been explored by several recent studies. However, no existing study has ever investigated the pre-training of text plus graph models on large heterogeneous graphs with abundant textual information (a.k.a. large graph corpora) and then fine-tuning the model on different related downstream applications with different graph schemas. To address this problem, we propose a framework of graph-aware language model pre-training (GALM) on a large graph corpus, which incorporates large language models and graph neural networks, and a variety of fine-tuning methods on downstream applications. We conduct extensive experiments on Amazon's real internal datasets and large public datasets. Comprehensive empirical results and in-depth analysis demonstrate the effectiveness of our proposed methods along with lessons learned.