 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotTarget: Rethinking the Effect of Target Edges for Link Prediction in Graph Neural Networks
Paper and Code
Jun 01, 2023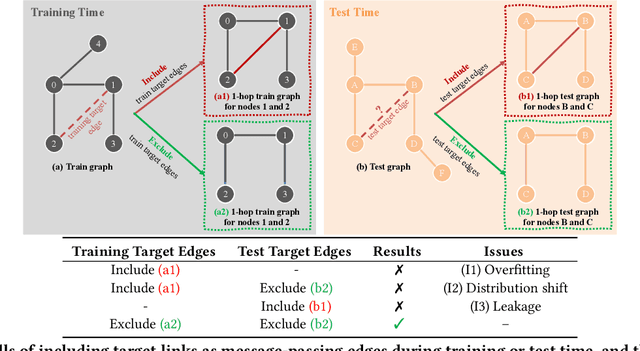

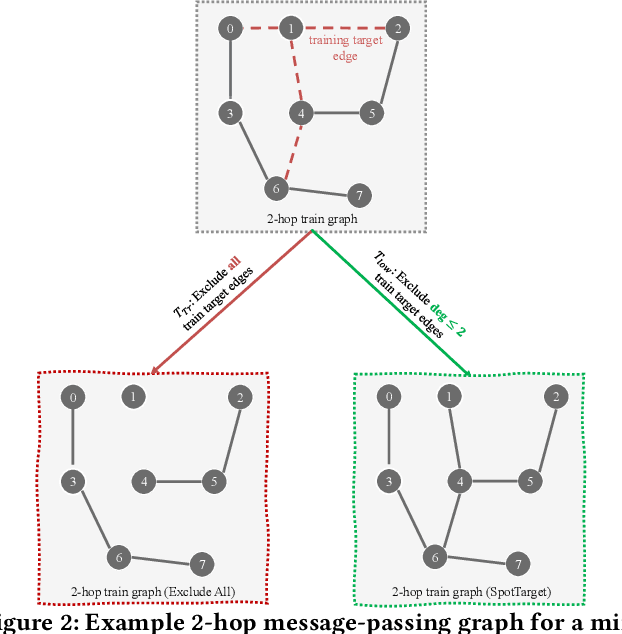
Graph Neural Networks (GNNs) have demonstrated promising outcomes across various tasks, including node classification and link prediction. Despite their remarkable success in various high-impact applications, we have identified three common pitfalls in message passing for link prediction. Particularly, in prevalent GNN frameworks (e.g., DGL and PyTorch-Geometric), the target edges (i.e., the edges being predicted) consistently exist as message passing edges in the graph during training. Consequently, this results in overfitting and distribution shift, both of which adversely impact the generalizability to test the target edges. Additionally, during test time, the failure to exclude the test target edges leads to implicit test leakage caused by neighborhood aggregation. In this paper, we analyze these three pitfalls and investigate the impact of including or excluding target edges on the performance of nodes with varying degrees during training and test phases. Our theoretical and empirical analysis demonstrates that low-degree nodes are more susceptible to these pitfalls. These pitfalls can have detrimental consequences when GNNs are implemented in production systems. To systematically address these pitfalls, we propose SpotTarget, an effective and efficient GNN training framework. During training, SpotTarget leverages our insight regarding low-degree nodes and excludes train target edges connected to at least one low-degree node. During test time, it emulates real-world scenarios of GNN usage in production and excludes all test target edges. Our experiments conducted on diverse real-world datasets, demonstrate that SpotTarget significantly enhances GNNs, achieving up to a 15x increase in accuracy in sparse graphs. Furthermore, SpotTarget consistently and dramatically improves the performance for low-degree nodes in dense graphs.