 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Graph Domain Adaptation for Cross-scenario Multi-modal Emotion Recognition
Mar 27, 2026Multimodal Emotion Recognition in Conversations (MERC) aims to predict speakers' emotional states in multi-turn dialogues through text, audio, and visual cues. In real-world settings, conversation scenarios differ significantly in speakers, topics, styles, and noise levels. Existing MERC methods generally neglect these cross-scenario variations, limiting their ability to transfer models trained on a source domain to unseen target domains. To address this issue, we propose a Dual-branch Graph Domain Adaptation framework (DGDA) for multimodal emotion recognition under cross-scenario conditions. We first construct an emotion interaction graph to characterize complex emotional dependencies among utterances. A dual-branch encoder, consisting of a hypergraph neural network (HGNN) and a path neural network (PathNN), is then designed to explicitly model multivariate relationships and implicitly capture global dependencies. To enable out-of-domain generalization, a domain adversarial discriminator is introduced to learn invariant representations across domains. Furthermore, a regularization loss is incorporated to suppress the negative influence of noisy labels. To the best of our knowledge, DGDA is the first MERC framework that jointly addresses domain shift and label noise. Theoretical analysis provides tighter generalization bounds, and extensive experiments on IEMOCAP and MELD demonstrate that DGDA consistently outperforms strong baselines and better adapts to cross-scenario conversations. Our code is available at https://github.com/Xudmm1239439/DGDA-Net.
Dynamic Fusion-Aware Graph Convolutional Neural Network for Multimodal Emotion Recognition in Conversations
Mar 22, 2026Multimodal emotion recognition in conversations (MERC) aims to identify and understand the emotions expressed by speakers during utterance interaction from multiple modalities (e.g., text, audio, images, etc.). Existing studies have shown that GCN can improve the performance of MERC by modeling dependencies between speakers. However, existing methods usually use fixed parameters to process multimodal features for different emotion types, ignoring the dynamics of fusion between different modalities, which forces the model to balance performance between multiple emotion categories, thus limiting the model's performance on some specific emotions. To this end, we propose a dynamic fusion-aware graph convolutional neural network (DF-GCN) for robust recognition of multimodal emotion features in conversations. Specifically, DF-GCN integrates ordinary differential equations into graph convolutional networks (GCNs) to {capture} the dynamic nature of emotional dependencies within utterance interaction networks and leverages the prompts generated by the global information vector (GIV) of the utterance to guide the dynamic fusion of multimodal features. This allows our model to dynamically change parameters when processing each utterance feature, so that different network parameters can be equipped for different emotion categories in the inference stage, thereby achieving more flexible emotion classification and enhancing the generalization ability of the model. Comprehensive experiments conducted on two public multimodal conversational datasets {confirm} that the proposed DF-GCN model delivers superior performance, benefiting significantly from the dynamic fusion mechanism introduced.
Relational graph-driven differential denoising and diffusion attention fusion for multimodal conversation emotion recognition
Mar 22, 2026In real-world scenarios, audio and video signals are often subject to environmental noise and limited acquisition conditions, resulting in extracted features containing excessive noise. Furthermore, there is an imbalance in data quality and information carrying capacity between different modalities. These two issues together lead to information distortion and weight bias during the fusion phase, impairing overall recognition performance. Most existing methods neglect the impact of noisy modalities and rely on implicit weighting to model modality importance, thereby failing to explicitly account for the predominant contribution of the textual modality in emotion understanding. To address these issues, we propose a relation-aware denoising and diffusion attention fusion model for MCER. Specifically, we first design a differential Transformer that explicitly computes the differences between two attention maps, thereby enhancing temporally consistent information while suppressing time-irrelevant noise, which leads to effective denoising in both audio and video modalities. Second, we construct modality-specific and cross-modality relation subgraphs to capture speaker-dependent emotional dependencies, enabling fine-grained modeling of intra- and inter-modal relationships. Finally, we introduce a text-guided cross-modal diffusion mechanism that leverages self-attention to model intra-modal dependencies and adaptively diffuses audiovisual information into the textual stream, ensuring more robust and semantically aligned multimodal fusion.
* 19 pages
The Paradigm Shift: A Comprehensive Survey on Large Vision Language Models for Multimodal Fake News Detection
Jan 16, 2026In recent years, the rapid evolution of large vision-language models (LVLMs) has driven a paradigm shift in multimodal fake news detection (MFND), transforming it from traditional feature-engineering approaches to unified, end-to-end multimodal reasoning frameworks. Early methods primarily relied on shallow fusion techniques to capture correlations between text and images, but they struggled with high-level semantic understanding and complex cross-modal interactions. The emergence of LVLMs has fundamentally changed this landscape by enabling joint modeling of vision and language with powerful representation learning, thereby enhancing the ability to detect misinformation that leverages both textual narratives and visual content. Despite these advances, the field lacks a systematic survey that traces this transition and consolidates recent developments. To address this gap, this paper provides a comprehensive review of MFND through the lens of LVLMs. We first present a historical perspective, mapping the evolution from conventional multimodal detection pipelines to foundation model-driven paradigms. Next, we establish a structured taxonomy covering model architectures, datasets, and performance benchmarks. Furthermore, we analyze the remaining technical challenges, including interpretability, temporal reasoning, and domain generalization. Finally, we outline future research directions to guide the next stage of this paradigm shift. To the best of our knowledge, this is the first comprehensive survey to systematically document and analyze the transformative role of LVLMs in combating multimodal fake news. The summary of existing methods mentioned is in our Github: \href{https://github.com/Tan-YiLong/Overview-of-Fake-News-Detection}{https://github.com/Tan-YiLong/Overview-of-Fake-News-Detection}.
GSDNet: Revisiting Incomplete Multimodal-Diffusion from Graph Spectrum Perspective for Conversation Emotion Recognition
Jun 14, 2025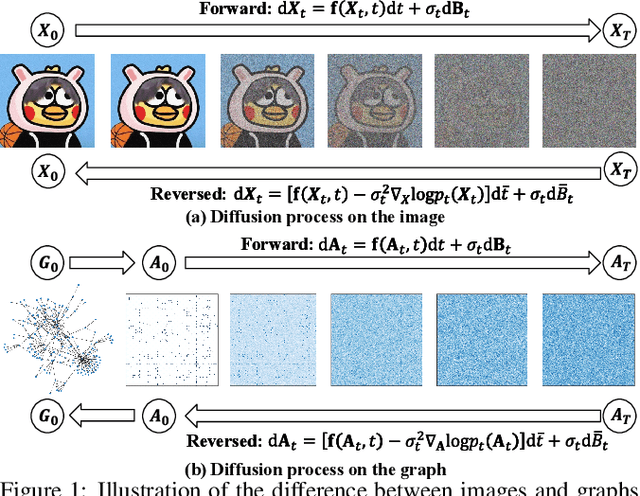
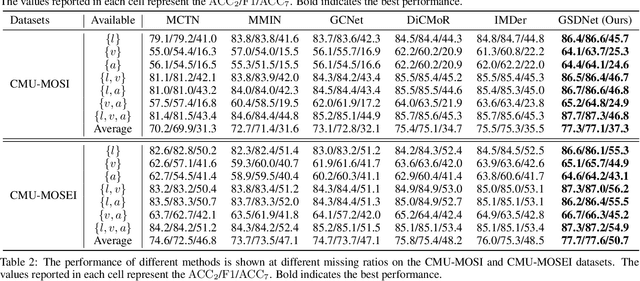
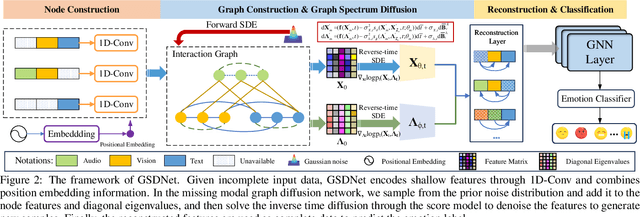
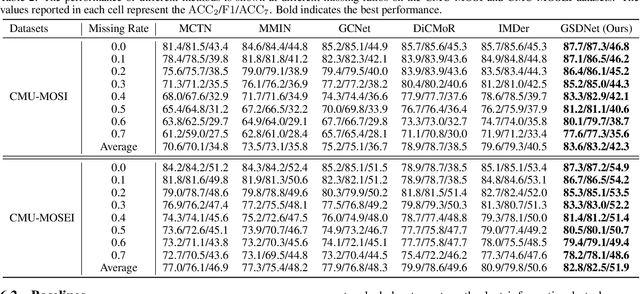
Multimodal emotion recognition in conversations (MERC) aims to infer the speaker's emotional state by analyzing utterance information from multiple sources (i.e., video, audio, and text). Compared with unimodality, a more robust utterance representation can be obtained by fusing complementary semantic information from different modalities. However, the modality missing problem severely limits the performance of MERC in practical scenarios. Recent work has achieved impressive performance on modality completion using graph neural networks and diffusion models, respectively. This inspires us to combine these two dimensions through the graph diffusion model to obtain more powerful modal recovery capabilities. Unfortunately, existing graph diffusion models may destroy the connectivity and local structure of the graph by directly adding Gaussian noise to the adjacency matrix, resulting in the generated graph data being unable to retain the semantic and topological information of the original graph. To this end, we propose a novel Graph Spectral Diffusion Network (GSDNet), which maps Gaussian noise to the graph spectral space of missing modalities and recovers the missing data according to its original distribution. Compared with previous graph diffusion methods, GSDNet only affects the eigenvalues of the adjacency matrix instead of destroying the adjacency matrix directly, which can maintain the global topological information and important spectral features during the diffusion process. Extensive experiments have demonstrated that GSDNet achieves state-of-the-art emotion recognition performance in various modality loss scenarios.
VietMix: A Naturally Occurring Vietnamese-English Code-Mixed Corpus with Iterative Augmentation for Machine Translation
May 30, 2025Machine translation systems fail when processing code-mixed inputs for low-resource languages. We address this challenge by curating VietMix, a parallel corpus of naturally occurring code-mixed Vietnamese text paired with expert English translations. Augmenting this resource, we developed a complementary synthetic data generation pipeline. This pipeline incorporates filtering mechanisms to ensure syntactic plausibility and pragmatic appropriateness in code-mixing patterns. Experimental validation shows our naturalistic and complementary synthetic data boost models' performance, measured by translation quality estimation scores, of up to 71.84 on COMETkiwi and 81.77 on XCOMET. Triangulating positive results with LLM-based assessments, augmented models are favored over seed fine-tuned counterparts in approximately 49% of judgments (54-56% excluding ties). VietMix and our augmentation methodology advance ecological validity in neural MT evaluations and establish a framework for addressing code-mixed translation challenges across other low-resource pairs.
Extracting Research Instruments from Educational Literature Using LLMs
May 28, 2025Large Language Models (LLMs) are transforming information extraction from academic literature, offering new possibilities for knowledge management. This study presents an LLM-based system designed to extract detailed information about research instruments used in the education field, including their names, types, target respondents, measured constructs, and outcomes. Using multi-step prompting and a domain-specific data schema, it generates structured outputs optimized for educational research. Our evaluation shows that this system significantly outperforms other approaches, particularly in identifying instrument names and detailed information. This demonstrates the potential of LLM-powered information extraction in educational contexts, offering a systematic way to organize research instrument information. The ability to aggregate such information at scale enhances accessibility for researchers and education leaders, facilitating informed decision-making in educational research and policy.
DISCO Balances the Scales: Adaptive Domain- and Difficulty-Aware Reinforcement Learning on Imbalanced Data
May 21, 2025Large Language Models (LLMs) are increasingly aligned with human preferences through Reinforcement Learning from Human Feedback (RLHF). Among RLHF methods, Group Relative Policy Optimization (GRPO) has gained attention for its simplicity and strong performance, notably eliminating the need for a learned value function. However, GRPO implicitly assumes a balanced domain distribution and uniform semantic alignment across groups - assumptions that rarely hold in real-world datasets. When applied to multi-domain, imbalanced data, GRPO disproportionately optimizes for dominant domains, neglecting underrepresented ones and resulting in poor generalization and fairness. We propose Domain-Informed Self-Consistency Policy Optimization (DISCO), a principled extension to GRPO that addresses inter-group imbalance with two key innovations. Domain-aware reward scaling counteracts frequency bias by reweighting optimization based on domain prevalence. Difficulty-aware reward scaling leverages prompt-level self-consistency to identify and prioritize uncertain prompts that offer greater learning value. Together, these strategies promote more equitable and effective policy learning across domains. Extensive experiments across multiple LLMs and skewed training distributions show that DISCO improves generalization, outperforms existing GRPO variants by 5% on Qwen3 models, and sets new state-of-the-art results on multi-domain alignment benchmarks.
Skill Discovery for Software Scripting Automation via Offline Simulations with LLMs
Apr 29, 2025Scripting interfaces enable users to automate tasks and customize software workflows, but creating scripts traditionally requires programming expertise and familiarity with specific APIs, posing barriers for many users. While Large Language Models (LLMs) can generate code from natural language queries, runtime code generation is severely limited due to unverified code, security risks, longer response times, and higher computational costs. To bridge the gap, we propose an offline simulation framework to curate a software-specific skillset, a collection of verified scripts, by exploiting LLMs and publicly available scripting guides. Our framework comprises two components: (1) task creation, using top-down functionality guidance and bottom-up API synergy exploration to generate helpful tasks; and (2) skill generation with trials, refining and validating scripts based on execution feedback. To efficiently navigate the extensive API landscape, we introduce a Graph Neural Network (GNN)-based link prediction model to capture API synergy, enabling the generation of skills involving underutilized APIs and expanding the skillset's diversity. Experiments with Adobe Illustrator demonstrate that our framework significantly improves automation success rates, reduces response time, and saves runtime token costs compared to traditional runtime code generation. This is the first attempt to use software scripting interfaces as a testbed for LLM-based systems, highlighting the advantages of leveraging execution feedback in a controlled environment and offering valuable insights into aligning AI capabilities with user needs in specialized software domains.
SE-GNN: Seed Expanded-Aware Graph Neural Network with Iterative Optimization for Semi-supervised Entity Alignment
Mar 24, 2025Entity alignment aims to use pre-aligned seed pairs to find other equivalent entities from different knowledge graphs (KGs) and is widely used in graph fusion-related fields. However, as the scale of KGs increases, manually annotating pre-aligned seed pairs becomes difficult. Existing research utilizes entity embeddings obtained by aggregating single structural information to identify potential seed pairs, thus reducing the reliance on pre-aligned seed pairs. However, due to the structural heterogeneity of KGs, the quality of potential seed pairs obtained using only a single structural information is not ideal. In addition, although existing research improves the quality of potential seed pairs through semi-supervised iteration, they underestimate the impact of embedding distortion produced by noisy seed pairs on the alignment effect. In order to solve the above problems, we propose a seed expanded-aware graph neural network with iterative optimization for semi-supervised entity alignment, named SE-GNN. First, we utilize the semantic attributes and structural features of entities, combined with a conditional filtering mechanism, to obtain high-quality initial potential seed pairs. Next, we designed a local and global awareness mechanism. It introduces initial potential seed pairs and combines local and global information to obtain a more comprehensive entity embedding representation, which alleviates the impact of KGs structural heterogeneity and lays the foundation for the optimization of initial potential seed pairs. Then, we designed the threshold nearest neighbor embedding correction strategy. It combines the similarity threshold and the bidirectional nearest neighbor method as a filtering mechanism to select iterative potential seed pairs and also uses an embedding correction strategy to eliminate the embedding distortion.