 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeME: Model Merging Techniques for Homogeneous and Heterogeneous MoEs
Feb 04, 2025



The recent success of specialized Large Language Models (LLMs) in domains such as mathematical reasoning and coding has led to growing interest in methods for merging these expert LLMs into a unified Mixture-of-Experts (MoE) model, with the goal of enhancing performance in each domain while retaining effectiveness on general tasks. However, the effective merging of expert models remains an open challenge, especially for models with highly divergent weight parameters or different architectures. State-of-the-art MoE merging methods only work with homogeneous model architectures and rely on simple unweighted averaging to merge expert layers, which does not address parameter interference and requires extensive fine-tuning of the merged MoE to restore performance. To address these limitations, this paper introduces new MoE merging techniques, including strategies to mitigate parameter interference, routing heuristics to reduce the need for MoE fine-tuning, and a novel method for merging experts with different architectures. Extensive experiments across multiple domains demonstrate the effectiveness of our proposed methods, reducing fine-tuning costs, improving performance over state-of-the-art methods, and expanding the applicability of MoE merging.
MAML-en-LLM: Model Agnostic Meta-Training of LLMs for Improved In-Context Learning
May 19, 2024



Adapting large language models (LLMs) to unseen tasks with in-context training samples without fine-tuning remains an important research problem. To learn a robust LLM that adapts well to unseen tasks, multiple meta-training approaches have been proposed such as MetaICL and MetaICT, which involve meta-training pre-trained LLMs on a wide variety of diverse tasks. These meta-training approaches essentially perform in-context multi-task fine-tuning and evaluate on a disjointed test set of tasks. Even though they achieve impressive performance, their goal is never to compute a truly general set of parameters. In this paper, we propose MAML-en-LLM, a novel method for meta-training LLMs, which can learn truly generalizable parameters that not only perform well on disjointed tasks but also adapts to unseen tasks. We see an average increase of 2% on unseen domains in the performance while a massive 4% improvement on adaptation performance. Furthermore, we demonstrate that MAML-en-LLM outperforms baselines in settings with limited amount of training data on both seen and unseen domains by an average of 2%. Finally, we discuss the effects of type of tasks, optimizers and task complexity, an avenue barely explored in meta-training literature. Exhaustive experiments across 7 task settings along with two data settings demonstrate that models trained with MAML-en-LLM outperform SOTA meta-training approaches.
A Robust Semantic Communication System for Image
Mar 14, 2024Semantic communications have gained significant attention as a promising approach to address the transmission bottleneck, especially with the continuous development of 6G techniques. Distinct from the well investigated physical channel impairments, this paper focuses on semantic impairments in image, particularly those arising from adversarial perturbations. Specifically, we propose a novel metric for quantifying the intensity of semantic impairment and develop a semantic impairment dataset. Furthermore, we introduce a deep learning enabled semantic communication system, termed as DeepSC-RI, to enhance the robustness of image transmission, which incorporates a multi-scale semantic extractor with a dual-branch architecture for extracting semantics with varying granularity, thereby improving the robustness of the system. The fine-grained branch incorporates a semantic importance evaluation module to identify and prioritize crucial semantics, while the coarse-grained branch adopts a hierarchical approach for capturing the robust semantics. These two streams of semantics are seamlessly integrated via an advanced cross-attention-based semantic fusion module. Experimental results demonstrate the superior performance of DeepSC-RI under various levels of semantic impairment intensity.
Towards Semantic Communications: Deep Learning-Based Image Semantic Coding
Aug 08, 2022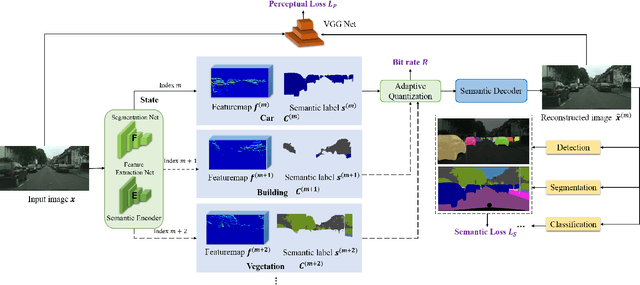

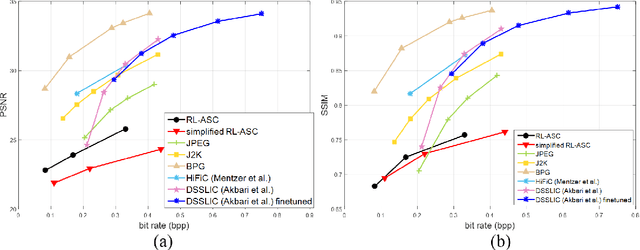
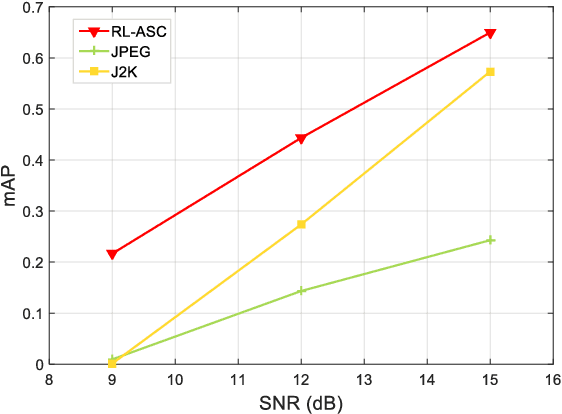
Semantic communications has received growing interest since it can remarkably reduce the amount of data to be transmitted without missing critical information. Most existing works explore the semantic encoding and transmission for text and apply techniques in Natural Language Processing (NLP) to interpret the meaning of the text. In this paper, we conceive the semantic communications for image data that is much more richer in semantics and bandwidth sensitive. We propose an reinforcement learning based adaptive semantic coding (RL-ASC) approach that encodes images beyond pixel level. Firstly, we define the semantic concept of image data that includes the category, spatial arrangement, and visual feature as the representation unit, and propose a convolutional semantic encoder to extract semantic concepts. Secondly, we propose the image reconstruction criterion that evolves from the traditional pixel similarity to semantic similarity and perceptual performance. Thirdly, we design a novel RL-based semantic bit allocation model, whose reward is the increase in rate-semantic-perceptual performance after encoding a certain semantic concept with adaptive quantization level. Thus, the task-related information is preserved and reconstructed properly while less important data is discarded. Finally, we propose the Generative Adversarial Nets (GANs) based semantic decoder that fuses both locally and globally features via an attention module. Experimental results demonstrate that the proposed RL-ASC is noise robust and could reconstruct visually pleasant and semantic consistent image, and saves times of bit cost compared to standard codecs and other deep learning-based image codecs.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022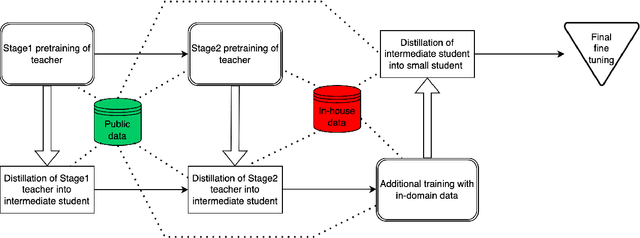
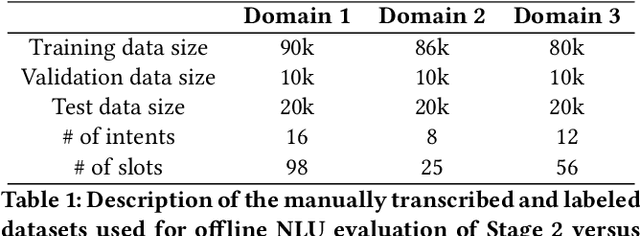
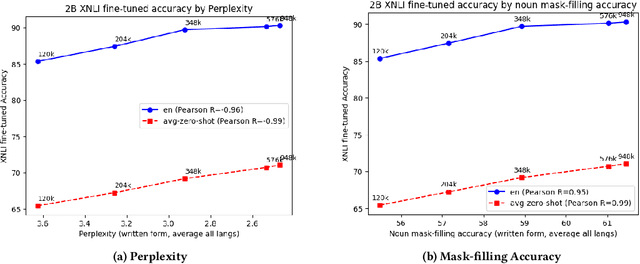
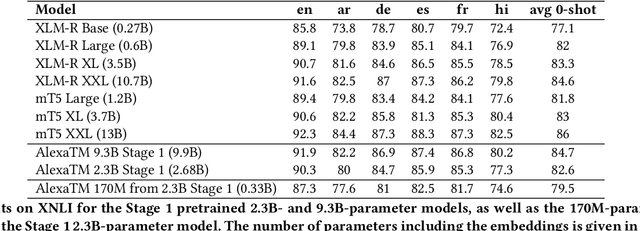
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
A Robust Deep Learning Enabled Semantic Communication System for Text
Jun 06, 2022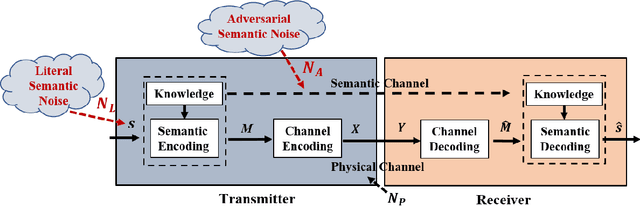
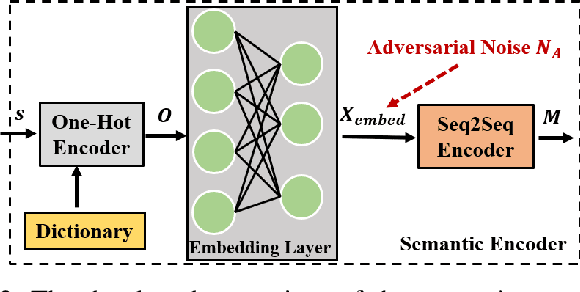
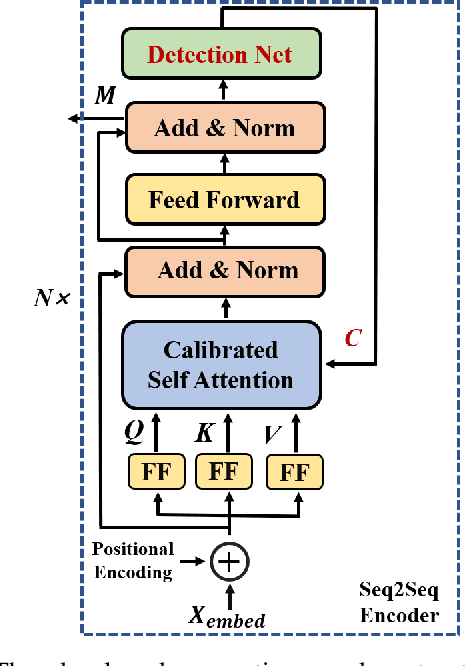

With the advent of the 6G era, the concept of semantic communication has attracted increasing attention. Compared with conventional communication systems, semantic communication systems are not only affected by physical noise existing in the wireless communication environment, e.g., additional white Gaussian noise, but also by semantic noise due to the source and the nature of deep learning-based systems. In this paper, we elaborate on the mechanism of semantic noise. In particular, we categorize semantic noise into two categories: literal semantic noise and adversarial semantic noise. The former is caused by written errors or expression ambiguity, while the latter is caused by perturbations or attacks added to the embedding layer via the semantic channel. To prevent semantic noise from influencing semantic communication systems, we present a robust deep learning enabled semantic communication system (R-DeepSC) that leverages a calibrated self-attention mechanism and adversarial training to tackle semantic noise. Compared with baseline models that only consider physical noise for text transmission, the proposed R-DeepSC achieves remarkable performance in dealing with semantic noise under different signal-to-noise ratios.
Semantic Communications: Principles and Challenges
Jan 06, 2022
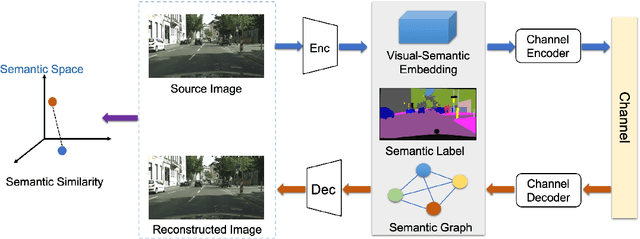
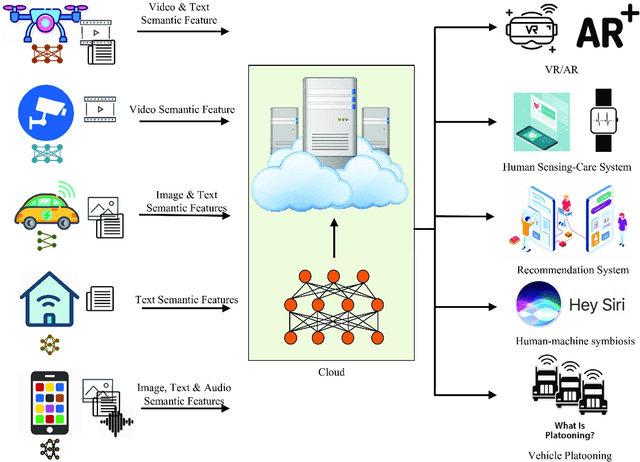
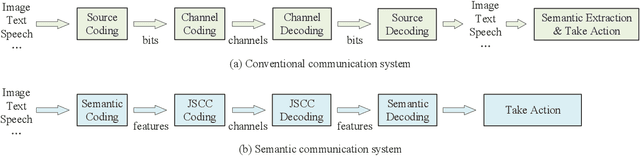
Semantic communication, regarded as the breakthrough beyond Shannon paradigm, aims at the successful transmission of semantic information conveyed by the source rather than the accurate reception of each single symbol or bit regardless of its meaning. This article provides an overview on semantic communications. After a brief review on Shannon information theory, we discuss semantic communications with theory, frameworks, and system design enabled by deep learning. Different from the symbol/bit error rate used for measuring the conventional communication systems, new performance metrics for semantic communications are also discussed. The article is concluded by several open questions.
Edge Artificial Intelligence for 6G: Vision, Enabling Technologies, and Applications
Nov 24, 2021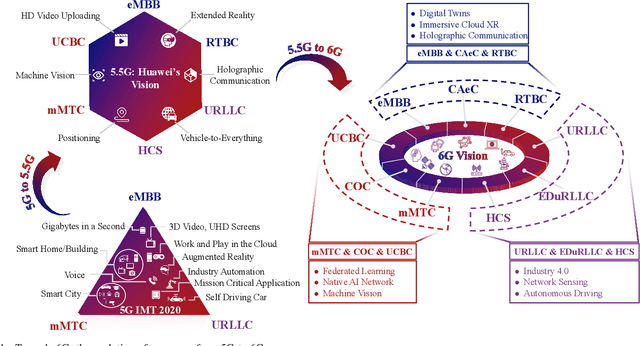
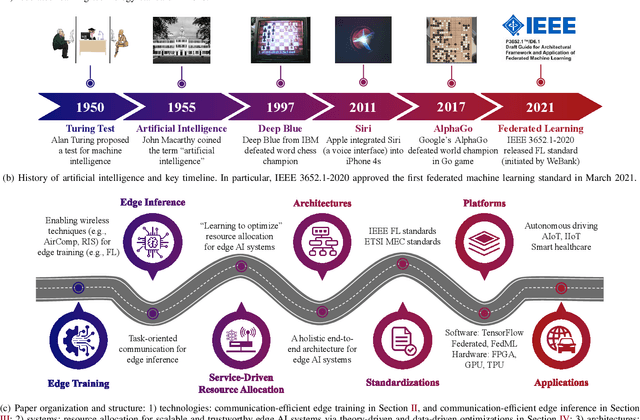
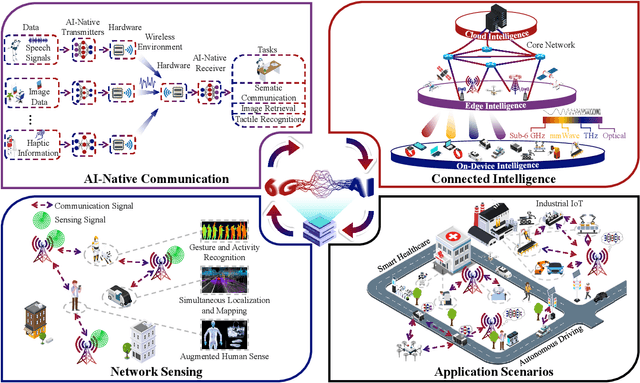
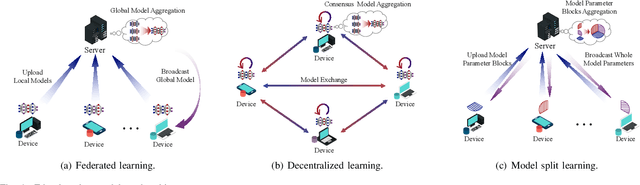
The thriving of artificial intelligence (AI) applications is driving the further evolution of wireless networks. It has been envisioned that 6G will be transformative and will revolutionize the evolution of wireless from "connected things" to "connected intelligence". However, state-of-the-art deep learning and big data analytics based AI systems require tremendous computation and communication resources, causing significant latency, energy consumption, network congestion, and privacy leakage in both of the training and inference processes. By embedding model training and inference capabilities into the network edge, edge AI stands out as a disruptive technology for 6G to seamlessly integrate sensing, communication, computation, and intelligence, thereby improving the efficiency, effectiveness, privacy, and security of 6G networks. In this paper, we shall provide our vision for scalable and trustworthy edge AI systems with integrated design of wireless communication strategies and decentralized machine learning models. New design principles of wireless networks, service-driven resource allocation optimization methods, as well as a holistic end-to-end system architecture to support edge AI will be described. Standardization, software and hardware platforms, and application scenarios are also discussed to facilitate the industrialization and commercialization of edge AI systems.
Industry Scale Semi-Supervised Learning for Natural Language Understanding
Mar 29, 2021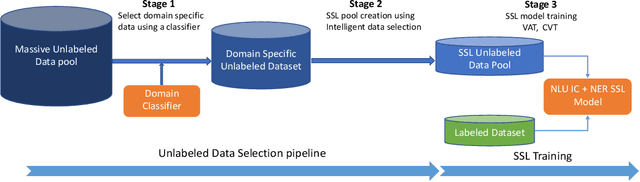

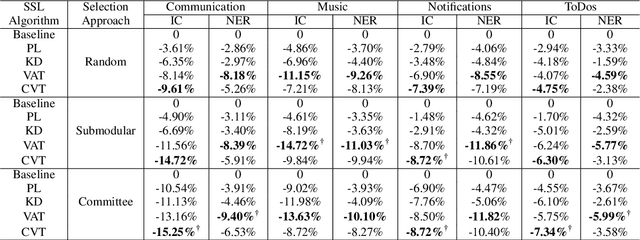
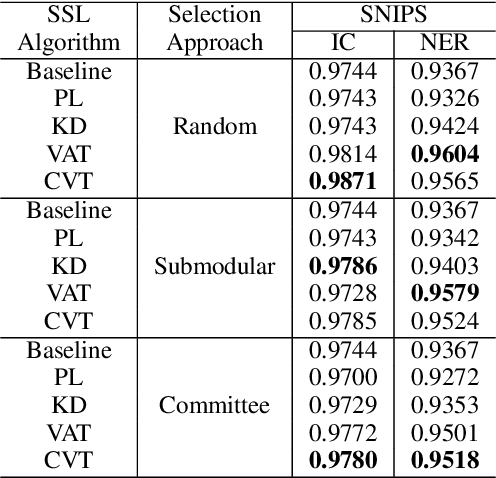
This paper presents a production Semi-Supervised Learning (SSL) pipeline based on the student-teacher framework, which leverages millions of unlabeled examples to improve Natural Language Understanding (NLU) tasks. We investigate two questions related to the use of unlabeled data in production SSL context: 1) how to select samples from a huge unlabeled data pool that are beneficial for SSL training, and 2) how do the selected data affect the performance of different state-of-the-art SSL techniques. We compare four widely used SSL techniques, Pseudo-Label (PL), Knowledge Distillation (KD), Virtual Adversarial Training (VAT) and Cross-View Training (CVT) in conjunction with two data selection methods including committee-based selection and submodular optimization based selection. We further examine the benefits and drawbacks of these techniques when applied to intent classification (IC) and named entity recognition (NER) tasks, and provide guidelines specifying when each of these methods might be beneficial to improve large scale NLU systems.
Get away from Style: Category-Guided Domain Adaptation for Semantic Segmentation
Mar 29, 2021
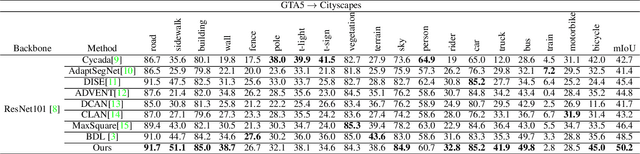
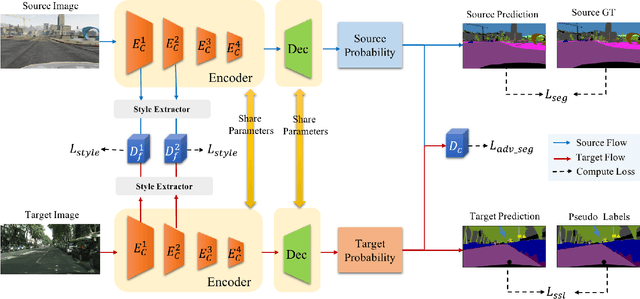

Unsupervised domain adaptation (UDA) becomes more and more popular in tackling real-world problems without ground truth of the target domain. Though a mass of tedious annotation work is not needed, UDA unavoidably faces the problem how to narrow the domain discrepancy to boost the transferring performance. In this paper, we focus on UDA for semantic segmentation task. Firstly, we propose a style-independent content feature extraction mechanism to keep the style information of extracted features in the similar space, since the style information plays a extremely slight role for semantic segmentation compared with the content part. Secondly, to keep the balance of pseudo labels on each category, we propose a category-guided threshold mechanism to choose category-wise pseudo labels for self-supervised learning. The experiments are conducted using GTA5 as the source domain, Cityscapes as the target domain. The results show that our model outperforms the state-of-the-arts with a noticeable gain on cross-domain adaptation tasks.