 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-guided Fine-tuning of Multimodal Large Language Models Improves Chain-of-Thought Reasoning
Jun 01, 2026The effectiveness of Chain-of-Thought (CoT) prompting in Multimodal Large Language Models (MLLMs) remains uncertain: across several visual reasoning benchmarks, CoT prompting often degrades performance compared to direct prompting. In this paper, we provide a systematic analysis of CoT behavior in three modern MLLM families across model scales on datasets requiring step-wise visual evidence. Our analysis identifies two recurring failure modes: premature answer commitment and limited direct visual-token access during rationale generation. We further find that standard CoT-style Supervised Fine-Tuning (CoT-SFT) can mitigate these issues only partially, while often increasing reliance on textual priors and reducing counterfactual visual dependence. Motivated by these findings, we propose Attentive-CoT (Att-CoT), an attention-guided fine-tuning objective that encourages CoT trajectories to delay answer commitment while maintaining sustained visual-token access. Att-CoT can be plugged into any CoT-SFT training run without architectural changes. Experiments on three visual reasoning benchmarks across six MLLMs show that Att-CoT enhances CoT performance over standard fine-tuning.
Rethinking Visual Attribution for Chest X-ray Reasoning in Large Vision Language Models
May 19, 2026Large Vision Language Models (LVLMs) show promise in medical applications, but their inability to faithfully ground responses in visual evidence raises serious concerns about clinical trustworthiness. While visual attribution methods are widely used to explain LVLM predictions, whether these explanations actually reflect the visual evidence underlying the model's decision is largely unverified, since ground-truth annotations for internal model reasoning are typically unavailable. We address this question for chest X-ray (CXR) reasoning by developing a causal evaluation framework that retains only CXR-VQA samples for which the expert-annotated region is verified, via counterfactual editing, to be causally responsible for the model's prediction. Using this framework across 11 attribution methods, six open-source LVLMs, and two output modes (direct answer and step-by-step reasoning), we find that existing attribution methods often fail to identify the evidence used by LVLMs. To address this failure, we propose MedFocus, a concept-based attribution method that localizes clinically meaningful anatomical regions via unbalanced optimal transport and measures their causal effect on model outputs through targeted interventions. MedFocus produces spatial, concept-level, and token-level attributions and substantially outperforms prior methods, taking a step toward more trustworthy attribution for medical LVLMs. Our data and code are available at https://github.com/gzxiong/medfocus/.
Retrieving Counterfactuals Improves Visual In-Context Learning
Mar 17, 2026Vision-language models (VLMs) have achieved impressive performance across a wide range of multimodal reasoning tasks, but they often struggle to disentangle fine-grained visual attributes and reason about underlying causal relationships. In-context learning (ICL) offers a promising avenue for VLMs to adapt to new tasks, but its effectiveness critically depends on the selection of demonstration examples. Existing retrieval-augmented approaches typically rely on passive similarity-based retrieval, which tends to select correlated but non-causal examples, amplifying spurious associations and limiting model robustness. We introduce CIRCLES (Composed Image Retrieval for Causal Learning Example Selection), a novel framework that actively constructs demonstration sets by retrieving counterfactual-style examples through targeted, attribute-guided composed image retrieval. By incorporating counterfactual-style examples, CIRCLES enables VLMs to implicitly reason about the causal relations between attributes and outcomes, moving beyond superficial correlations and fostering more robust and grounded reasoning. Comprehensive experiments on four diverse datasets demonstrate that CIRCLES consistently outperforms existing methods across multiple architectures, especially on small-scale models, with pronounced gains under information scarcity. Furthermore, CIRCLES retrieves more diverse and causally informative examples, providing qualitative insights into how models leverage in-context demonstrations for improved reasoning. Our code is available at https://github.com/gzxiong/CIRCLES.
Neural Additive Experts: Context-Gated Experts for Controllable Model Additivity
Feb 11, 2026The trade-off between interpretability and accuracy remains a core challenge in machine learning. Standard Generalized Additive Models (GAMs) offer clear feature attributions but are often constrained by their strictly additive nature, which can limit predictive performance. Introducing feature interactions can boost accuracy yet may obscure individual feature contributions. To address these issues, we propose Neural Additive Experts (NAEs), a novel framework that seamlessly balances interpretability and accuracy. NAEs employ a mixture of experts framework, learning multiple specialized networks per feature, while a dynamic gating mechanism integrates information across features, thereby relaxing rigid additive constraints. Furthermore, we propose targeted regularization techniques to mitigate variance among expert predictions, facilitating a smooth transition from an exclusively additive model to one that captures intricate feature interactions while maintaining clarity in feature attributions. Our theoretical analysis and experiments on synthetic data illustrate the model's flexibility, and extensive evaluations on real-world datasets confirm that NAEs achieve an optimal balance between predictive accuracy and transparent, feature-level explanations. The code is available at https://github.com/Teddy-XiongGZ/NAE.
CASL: Concept-Aligned Sparse Latents for Interpreting Diffusion Models
Jan 21, 2026Internal activations of diffusion models encode rich semantic information, but interpreting such representations remains challenging. While Sparse Autoencoders (SAEs) have shown promise in disentangling latent representations, existing SAE-based methods for diffusion model understanding rely on unsupervised approaches that fail to align sparse features with human-understandable concepts. This limits their ability to provide reliable semantic control over generated images. We introduce CASL (Concept-Aligned Sparse Latents), a supervised framework that aligns sparse latent dimensions of diffusion models with semantic concepts. CASL first trains an SAE on frozen U-Net activations to obtain disentangled latent representations, and then learns a lightweight linear mapping that associates each concept with a small set of relevant latent dimensions. To validate the semantic meaning of these aligned directions, we propose CASL-Steer, a controlled latent intervention that shifts activations along the learned concept axis. Unlike editing methods, CASL-Steer is used solely as a causal probe to reveal how concept-aligned latents influence generated content. We further introduce the Editing Precision Ratio (EPR), a metric that jointly measures concept specificity and the preservation of unrelated attributes. Experiments show that our method achieves superior editing precision and interpretability compared to existing approaches. To the best of our knowledge, this is the first work to achieve supervised alignment between latent representations and semantic concepts in diffusion models.
Reasoning Beyond Chain-of-Thought: A Latent Computational Mode in Large Language Models
Jan 12, 2026Chain-of-Thought (CoT) prompting has improved the reasoning performance of large language models (LLMs), but it remains unclear why it works and whether it is the unique mechanism for triggering reasoning in large language models. In this work, we study this question by directly analyzing and intervening on the internal representations of LLMs with Sparse Autoencoders (SAEs), identifying a small set of latent features that are causally associated with LLM reasoning behavior. Across multiple model families and reasoning benchmarks, we find that steering a single reasoning-related latent feature can substantially improve accuracy without explicit CoT prompting. For large models, latent steering achieves performance comparable to standard CoT prompting while producing more efficient outputs. We further observe that this reasoning-oriented internal state is triggered early in generation and can override prompt-level instructions that discourage explicit reasoning. Overall, our results suggest that multi-step reasoning in LLMs is supported by latent internal activations that can be externally activated, while CoT prompting is one effective, but not unique, way of activating this mechanism rather than its necessary cause.
Toward Faithful Retrieval-Augmented Generation with Sparse Autoencoders
Dec 09, 2025



Retrieval-Augmented Generation (RAG) improves the factuality of large language models (LLMs) by grounding outputs in retrieved evidence, but faithfulness failures, where generations contradict or extend beyond the provided sources, remain a critical challenge. Existing hallucination detection methods for RAG often rely either on large-scale detector training, which requires substantial annotated data, or on querying external LLM judges, which leads to high inference costs. Although some approaches attempt to leverage internal representations of LLMs for hallucination detection, their accuracy remains limited. Motivated by recent advances in mechanistic interpretability, we employ sparse autoencoders (SAEs) to disentangle internal activations, successfully identifying features that are specifically triggered during RAG hallucinations. Building on a systematic pipeline of information-based feature selection and additive feature modeling, we introduce RAGLens, a lightweight hallucination detector that accurately flags unfaithful RAG outputs using LLM internal representations. RAGLens not only achieves superior detection performance compared to existing methods, but also provides interpretable rationales for its decisions, enabling effective post-hoc mitigation of unfaithful RAG. Finally, we justify our design choices and reveal new insights into the distribution of hallucination-related signals within LLMs. The code is available at https://github.com/Teddy-XiongGZ/RAGLens.
Concept-RuleNet: Grounded Multi-Agent Neurosymbolic Reasoning in Vision Language Models
Nov 13, 2025Modern vision-language models (VLMs) deliver impressive predictive accuracy yet offer little insight into 'why' a decision is reached, frequently hallucinating facts, particularly when encountering out-of-distribution data. Neurosymbolic frameworks address this by pairing black-box perception with interpretable symbolic reasoning, but current methods extract their symbols solely from task labels, leaving them weakly grounded in the underlying visual data. In this paper, we introduce a multi-agent system - Concept-RuleNet that reinstates visual grounding while retaining transparent reasoning. Specifically, a multimodal concept generator first mines discriminative visual concepts directly from a representative subset of training images. Next, these visual concepts are utilized to condition symbol discovery, anchoring the generations in real image statistics and mitigating label bias. Subsequently, symbols are composed into executable first-order rules by a large language model reasoner agent - yielding interpretable neurosymbolic rules. Finally, during inference, a vision verifier agent quantifies the degree of presence of each symbol and triggers rule execution in tandem with outputs of black-box neural models, predictions with explicit reasoning pathways. Experiments on five benchmarks, including two challenging medical-imaging tasks and three underrepresented natural-image datasets, show that our system augments state-of-the-art neurosymbolic baselines by an average of 5% while also reducing the occurrence of hallucinated symbols in rules by up to 50%.
GCAV: A Global Concept Activation Vector Framework for Cross-Layer Consistency in Interpretability
Aug 28, 2025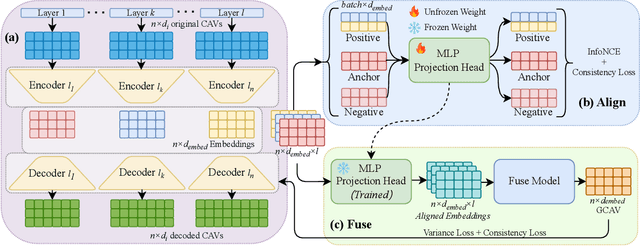
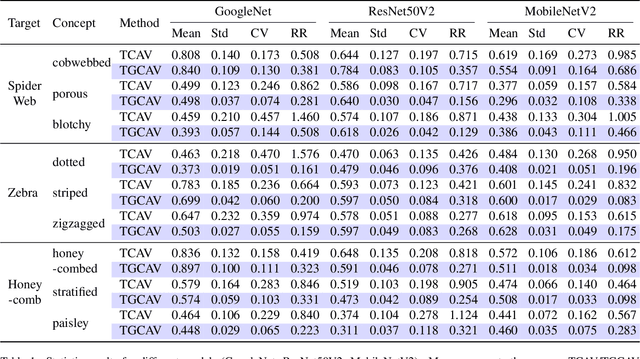
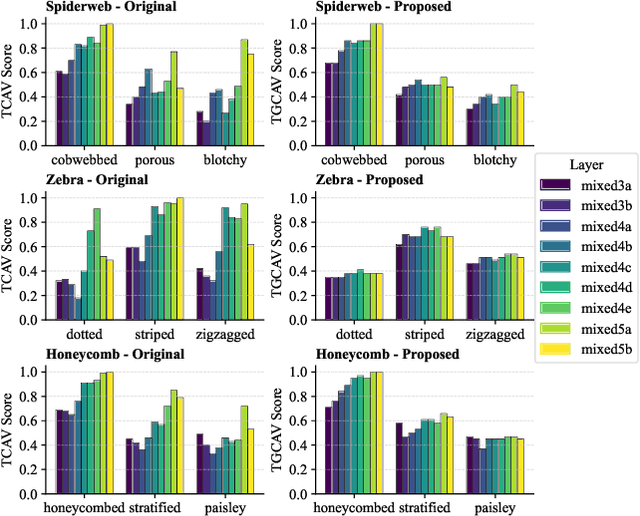

Concept Activation Vectors (CAVs) provide a powerful approach for interpreting deep neural networks by quantifying their sensitivity to human-defined concepts. However, when computed independently at different layers, CAVs often exhibit inconsistencies, making cross-layer comparisons unreliable. To address this issue, we propose the Global Concept Activation Vector (GCAV), a novel framework that unifies CAVs into a single, semantically consistent representation. Our method leverages contrastive learning to align concept representations across layers and employs an attention-based fusion mechanism to construct a globally integrated CAV. By doing so, our method significantly reduces the variance in TCAV scores while preserving concept relevance, ensuring more stable and reliable concept attributions. To evaluate the effectiveness of GCAV, we introduce Testing with Global Concept Activation Vectors (TGCAV) as a method to apply TCAV to GCAV-based representations. We conduct extensive experiments on multiple deep neural networks, demonstrating that our method effectively mitigates concept inconsistency across layers, enhances concept localization, and improves robustness against adversarial perturbations. By integrating cross-layer information into a coherent framework, our method offers a more comprehensive and interpretable understanding of how deep learning models encode human-defined concepts. Code and models are available at https://github.com/Zhenghao-He/GCAV.
Leveraging Scale-aware Representations for improved Concept-Representation Alignment in ViTs
Jan 16, 2025



Vision Transformers (ViTs) are increasingly being adopted in various sensitive vision applications - like medical diagnosis, facial recognition, etc. To improve the interpretability of such models, many approaches attempt to forward-align them with carefully annotated abstract, human-understandable semantic entities - concepts. Concepts provide global rationales to the model predictions and can be quickly understood/intervened on by domain experts. Most current research focuses on designing model-agnostic, plug-and-play generic concept-based explainability modules that do not incorporate the inner workings of foundation models (e.g., inductive biases, scale invariance, etc.) during training. To alleviate this issue for ViTs, in this paper, we propose a novel Concept Representation Alignment Module (CRAM) which learns both scale and position-aware representations from multi-scale feature pyramids and patch representations respectively. CRAM further aligns these representations with concept annotations through an attention matrix. The proposed CRAM module improves the predictive performance of ViT architectures and also provides accurate and robust concept explanations as demonstrated on five datasets - including three widely used benchmarks (CUB, Pascal APY, Concept-MNIST) and 2 real-world datasets (AWA2, KITS).