 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite-Box Sensitivity Auditing with Steering Vectors
Jan 23, 2026Algorithmic audits are essential tools for examining systems for properties required by regulators or desired by operators. Current audits of large language models (LLMs) primarily rely on black-box evaluations that assess model behavior only through input-output testing. These methods are limited to tests constructed in the input space, often generated by heuristics. In addition, many socially relevant model properties (e.g., gender bias) are abstract and difficult to measure through text-based inputs alone. To address these limitations, we propose a white-box sensitivity auditing framework for LLMs that leverages activation steering to conduct more rigorous assessments through model internals. Our auditing method conducts internal sensitivity tests by manipulating key concepts relevant to the model's intended function for the task. We demonstrate its application to bias audits in four simulated high-stakes LLM decision tasks. Our method consistently reveals substantial dependence on protected attributes in model predictions, even in settings where standard black-box evaluations suggest little or no bias. Our code is openly available at https://github.com/hannahxchen/llm-steering-audit
Syntactic Blind Spots: How Misalignment Leads to LLMs Mathematical Errors
Oct 02, 2025Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities but frequently fail on problems that deviate syntactically from their training distribution. We identify a systematic failure mode, syntactic blind spots, in which models misapply familiar reasoning strategies to problems that are semantically straightforward but phrased in unfamiliar ways. These errors are not due to gaps in mathematical competence, but rather reflect a brittle coupling between surface form and internal representation. To test this, we rephrase incorrectly answered questions using syntactic templates drawn from correct examples. These rephrasings, which preserve semantics while reducing structural complexity, often lead to correct answers. We quantify syntactic complexity using a metric based on Dependency Locality Theory (DLT), and show that higher DLT scores are associated with increased failure rates across multiple datasets. Our findings suggest that many reasoning errors stem from structural misalignment rather than conceptual difficulty, and that syntax-aware interventions can reveal and mitigate these inductive failures.
Optimizing Latent Dimension Allocation in Hierarchical VAEs: Balancing Attenuation and Information Retention for OOD Detection
Jun 11, 2025Out-of-distribution (OOD) detection is a critical task in machine learning, particularly for safety-critical applications where unexpected inputs must be reliably flagged. While hierarchical variational autoencoders (HVAEs) offer improved representational capacity over traditional VAEs, their performance is highly sensitive to how latent dimensions are distributed across layers. Existing approaches often allocate latent capacity arbitrarily, leading to ineffective representations or posterior collapse. In this work, we introduce a theoretically grounded framework for optimizing latent dimension allocation in HVAEs, drawing on principles from information theory to formalize the trade-off between information loss and representational attenuation. We prove the existence of an optimal allocation ratio $r^{\ast}$ under a fixed latent budget, and empirically show that tuning this ratio consistently improves OOD detection performance across datasets and architectures. Our approach outperforms baseline HVAE configurations and provides practical guidance for principled latent structure design, leading to more robust OOD detection with deep generative models.
"CASE: Contrastive Activation for Saliency Estimation
Jun 08, 2025

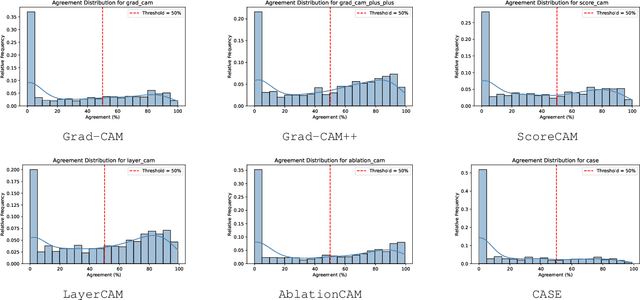
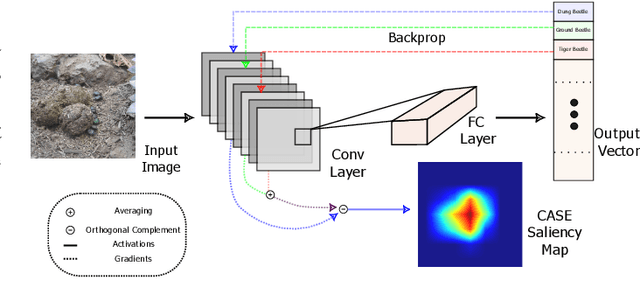
Saliency methods are widely used to visualize which input features are deemed relevant to a model's prediction. However, their visual plausibility can obscure critical limitations. In this work, we propose a diagnostic test for class sensitivity: a method's ability to distinguish between competing class labels on the same input. Through extensive experiments, we show that many widely used saliency methods produce nearly identical explanations regardless of the class label, calling into question their reliability. We find that class-insensitive behavior persists across architectures and datasets, suggesting the failure mode is structural rather than model-specific. Motivated by these findings, we introduce CASE, a contrastive explanation method that isolates features uniquely discriminative for the predicted class. We evaluate CASE using the proposed diagnostic and a perturbation-based fidelity test, and show that it produces faithful and more class-specific explanations than existing methods.
IrrMap: A Large-Scale Comprehensive Dataset for Irrigation Method Mapping
May 13, 2025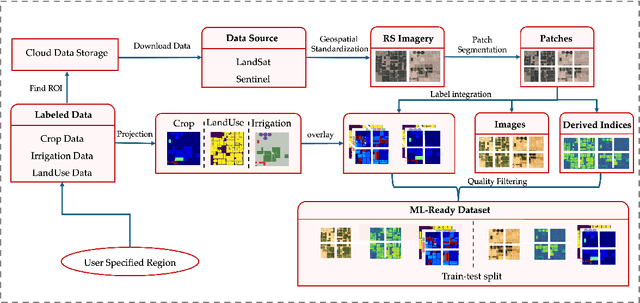
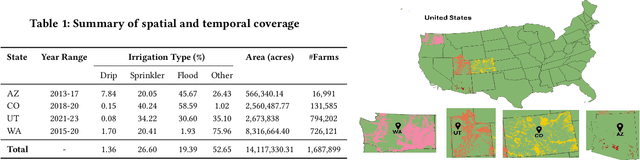

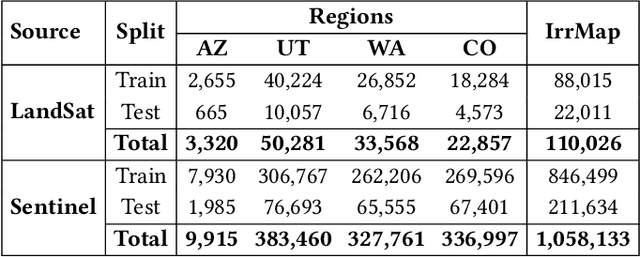
We introduce IrrMap, the first large-scale dataset (1.1 million patches) for irrigation method mapping across regions. IrrMap consists of multi-resolution satellite imagery from LandSat and Sentinel, along with key auxiliary data such as crop type, land use, and vegetation indices. The dataset spans 1,687,899 farms and 14,117,330 acres across multiple western U.S. states from 2013 to 2023, providing a rich and diverse foundation for irrigation analysis and ensuring geospatial alignment and quality control. The dataset is ML-ready, with standardized 224x224 GeoTIFF patches, the multiple input modalities, carefully chosen train-test-split data, and accompanying dataloaders for seamless deep learning model training andbenchmarking in irrigation mapping. The dataset is also accompanied by a complete pipeline for dataset generation, enabling researchers to extend IrrMap to new regions for irrigation data collection or adapt it with minimal effort for other similar applications in agricultural and geospatial analysis. We also analyze the irrigation method distribution across crop groups, spatial irrigation patterns (using Shannon diversity indices), and irrigated area variations for both LandSat and Sentinel, providing insights into regional and resolution-based differences. To promote further exploration, we openly release IrrMap, along with the derived datasets, benchmark models, and pipeline code, through a GitHub repository: https://github.com/Nibir088/IrrMap and Data repository: https://huggingface.co/Nibir/IrrMap, providing comprehensive documentation and implementation details.
Monte Carlo Sampling for Analyzing In-Context Examples
Mar 27, 2025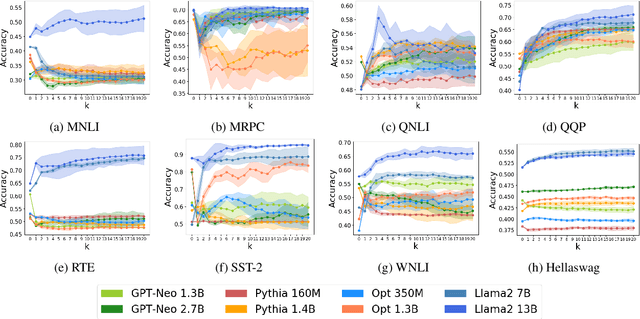
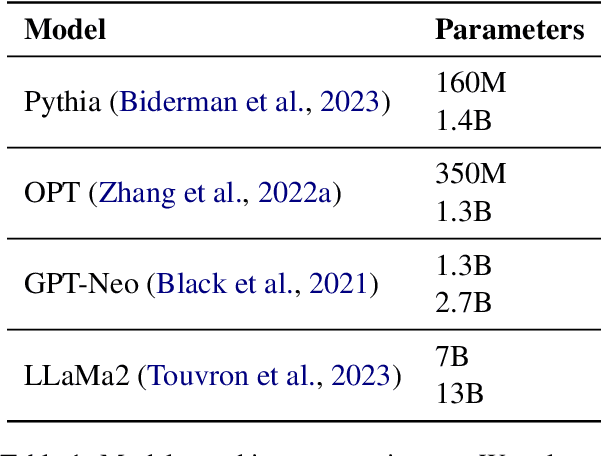
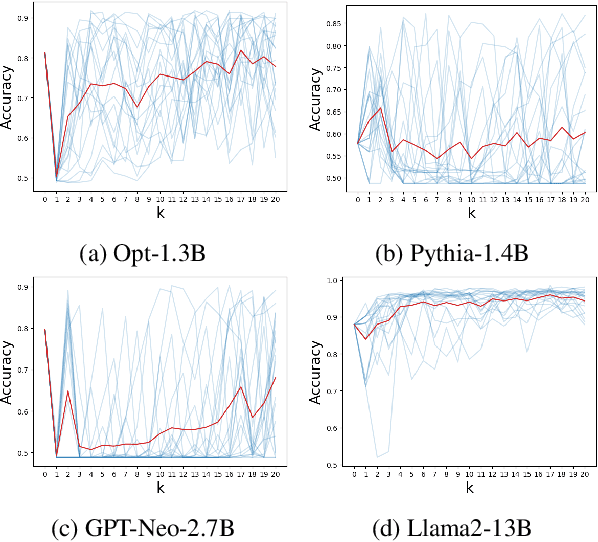
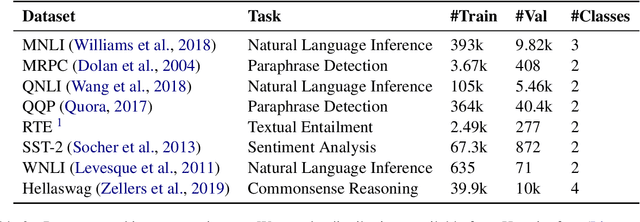
Prior works have shown that in-context learning is brittle to presentation factors such as the order, number, and choice of selected examples. However, ablation-based guidance on selecting the number of examples may ignore the interplay between different presentation factors. In this work we develop a Monte Carlo sampling-based method to study the impact of number of examples while explicitly accounting for effects from order and selected examples. We find that previous guidance on how many in-context examples to select does not always generalize across different sets of selected examples and orderings, and whether one-shot settings outperform zero-shot settings is highly dependent on the selected example. Additionally, inspired by data valuation, we apply our sampling method to in-context example selection to select examples that perform well across different orderings. We find a negative result, that while performance is robust to ordering and number of examples, there is an unexpected performance degradation compared to random sampling.
Sensing and Steering Stereotypes: Extracting and Applying Gender Representation Vectors in LLMs
Feb 27, 2025Large language models (LLMs) are known to perpetuate stereotypes and exhibit biases. Various strategies have been proposed to mitigate potential harms that may result from these biases, but most work studies biases in LLMs as a black-box problem without considering how concepts are represented within the model. We adapt techniques from representation engineering to study how the concept of "gender" is represented within LLMs. We introduce a new method that extracts concept representations via probability weighting without labeled data and efficiently selects a steering vector for measuring and manipulating the model's representation. We also present a projection-based method that enables precise steering of model predictions and demonstrate its effectiveness in mitigating gender bias in LLMs.
In-Context Learning (and Unlearning) of Length Biases
Feb 10, 2025



Large language models have demonstrated strong capabilities to learn in-context, where exemplar input-output pairings are appended to the prompt for demonstration. However, existing work has demonstrated the ability of models to learn lexical and label biases in-context, which negatively impacts both performance and robustness of models. The impact of other statistical data biases remains under-explored, which this work aims to address. We specifically investigate the impact of length biases on in-context learning. We demonstrate that models do learn length biases in the context window for their predictions, and further empirically analyze the factors that modulate the level of bias exhibited by the model. In addition, we show that learning length information in-context can be used to counter the length bias that has been encoded in models (e.g., via fine-tuning). This reveals the power of in-context learning in debiasing model prediction behaviors without the need for costly parameter updates.
RWKV-edge: Deeply Compressed RWKV for Resource-Constrained Devices
Dec 14, 2024To deploy LLMs on resource-contained platforms such as mobile robotics and wearables, non-transformers LLMs have achieved major breakthroughs. Recently, a novel RNN-based LLM family, Repentance Weighted Key Value (RWKV) models have shown promising results in text generation on resource-constrained devices thanks to their computational efficiency. However, these models remain too large to be deployed on embedded devices due to their high parameter count. In this paper, we propose an efficient suite of compression techniques, tailored to the RWKV architecture. These techniques include low-rank approximation, sparsity predictors, and clustering head, designed to align with the model size. Our methods compress the RWKV models by 4.95--3.8x with only 2.95pp loss in accuracy.
A Comparative Study of Learning Paradigms in Large Language Models via Intrinsic Dimension
Dec 09, 2024The performance of Large Language Models (LLMs) on natural language tasks can be improved through both supervised fine-tuning (SFT) and in-context learning (ICL), which operate via distinct mechanisms. Supervised fine-tuning updates the model's weights by minimizing loss on training data, whereas in-context learning leverages task demonstrations embedded in the prompt, without changing the model's parameters. This study investigates the effects of these learning paradigms on the hidden representations of LLMs using Intrinsic Dimension (ID). We use ID to estimate the number of degrees of freedom between representations extracted from LLMs as they perform specific natural language tasks. We first explore how the ID of LLM representations evolves during SFT and how it varies due to the number of demonstrations in ICL. We then compare the IDs induced by SFT and ICL and find that ICL consistently induces a higher ID compared to SFT, suggesting that representations generated during ICL reside in higher dimensional manifolds in the embedding space.