 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Sampling for Analyzing In-Context Examples
Mar 27, 2025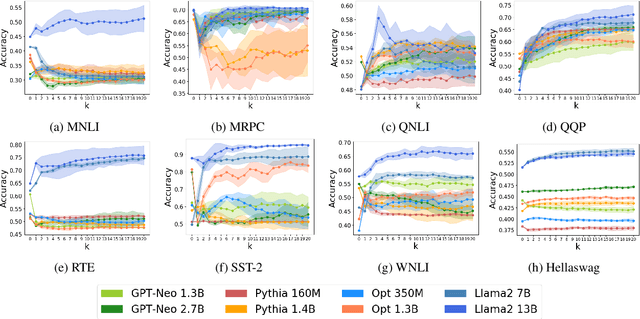
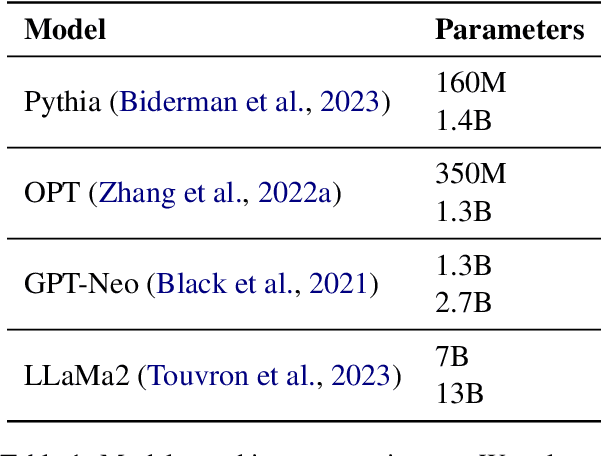
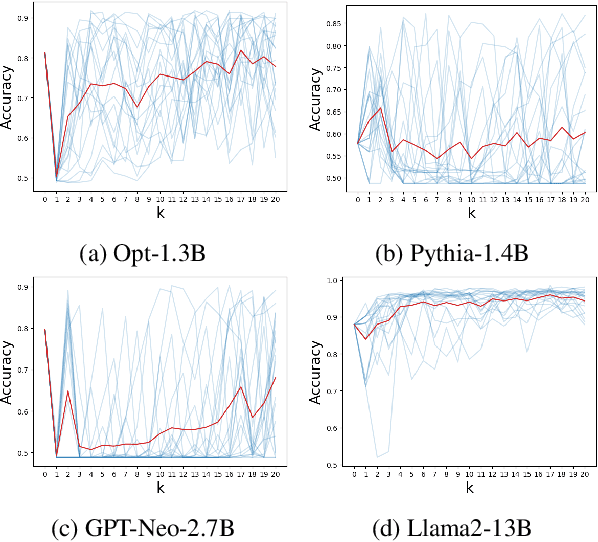
Prior works have shown that in-context learning is brittle to presentation factors such as the order, number, and choice of selected examples. However, ablation-based guidance on selecting the number of examples may ignore the interplay between different presentation factors. In this work we develop a Monte Carlo sampling-based method to study the impact of number of examples while explicitly accounting for effects from order and selected examples. We find that previous guidance on how many in-context examples to select does not always generalize across different sets of selected examples and orderings, and whether one-shot settings outperform zero-shot settings is highly dependent on the selected example. Additionally, inspired by data valuation, we apply our sampling method to in-context example selection to select examples that perform well across different orderings. We find a negative result, that while performance is robust to ordering and number of examples, there is an unexpected performance degradation compared to random sampling.
In-Context Learning (and Unlearning) of Length Biases
Feb 10, 2025



Large language models have demonstrated strong capabilities to learn in-context, where exemplar input-output pairings are appended to the prompt for demonstration. However, existing work has demonstrated the ability of models to learn lexical and label biases in-context, which negatively impacts both performance and robustness of models. The impact of other statistical data biases remains under-explored, which this work aims to address. We specifically investigate the impact of length biases on in-context learning. We demonstrate that models do learn length biases in the context window for their predictions, and further empirically analyze the factors that modulate the level of bias exhibited by the model. In addition, we show that learning length information in-context can be used to counter the length bias that has been encoded in models (e.g., via fine-tuning). This reveals the power of in-context learning in debiasing model prediction behaviors without the need for costly parameter updates.
Data Selection for Fine-tuning Large Language Models Using Transferred Shapley Values
Jun 16, 2023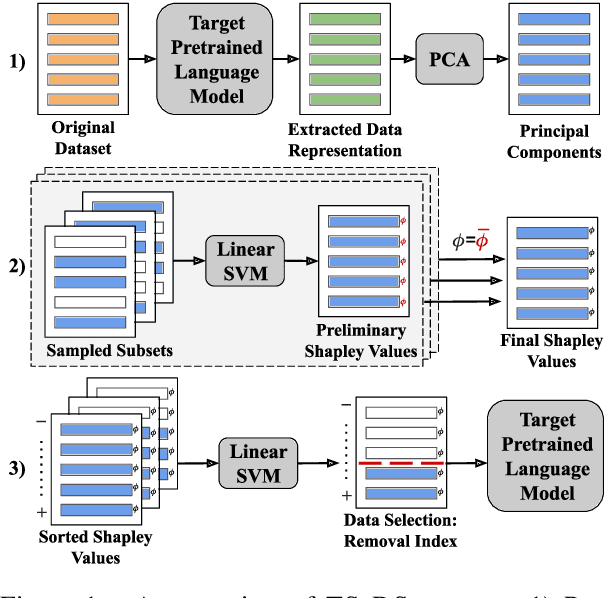
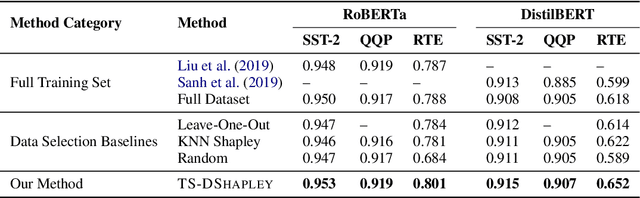
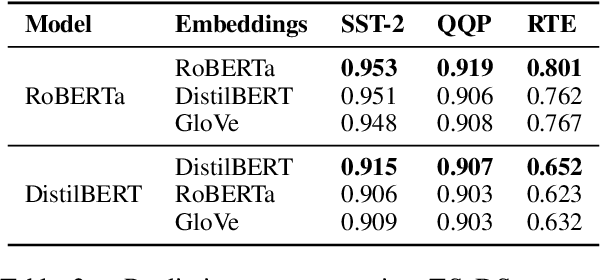
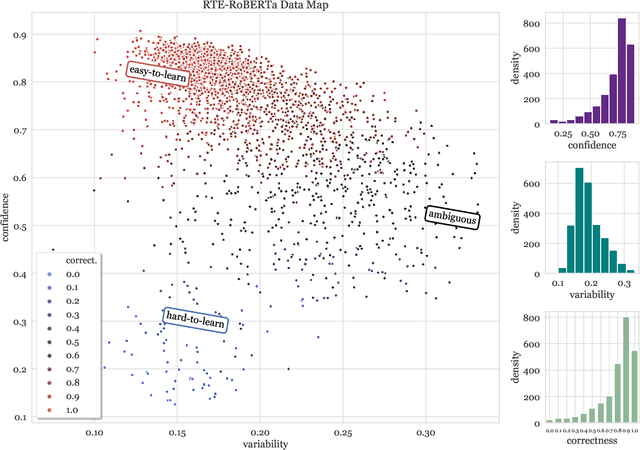
Although Shapley values have been shown to be highly effective for identifying harmful training instances, dataset size and model complexity constraints limit the ability to apply Shapley-based data valuation to fine-tuning large pre-trained language models. To address this, we propose TS-DShapley, an algorithm that reduces computational cost of Shapley-based data valuation through: 1) an efficient sampling-based method that aggregates Shapley values computed from subsets for valuation of the entire training set, and 2) a value transfer method that leverages value information extracted from a simple classifier trained using representations from the target language model. Our experiments applying TS-DShapley to select data for fine-tuning BERT-based language models on benchmark natural language understanding (NLU) datasets show that TS-DShapley outperforms existing data selection methods. Further, TS-DShapley can filter fine-tuning data to increase language model performance compared to training with the full fine-tuning dataset.
CS-Shapley: Class-wise Shapley Values for Data Valuation in Classification
Nov 13, 2022



Data valuation, or the valuation of individual datum contributions, has seen growing interest in machine learning due to its demonstrable efficacy for tasks such as noisy label detection. In particular, due to the desirable axiomatic properties, several Shapley value approximation methods have been proposed. In these methods, the value function is typically defined as the predictive accuracy over the entire development set. However, this limits the ability to differentiate between training instances that are helpful or harmful to their own classes. Intuitively, instances that harm their own classes may be noisy or mislabeled and should receive a lower valuation than helpful instances. In this work, we propose CS-Shapley, a Shapley value with a new value function that discriminates between training instances' in-class and out-of-class contributions. Our theoretical analysis shows the proposed value function is (essentially) the unique function that satisfies two desirable properties for evaluating data values in classification. Further, our experiments on two benchmark evaluation tasks (data removal and noisy label detection) and four classifiers demonstrate the effectiveness of CS-Shapley over existing methods. Lastly, we evaluate the "transferability" of data values estimated from one classifier to others, and our results suggest Shapley-based data valuation is transferable for application across different models.
Contextualizing Variation in Text Style Transfer Datasets
Aug 17, 2021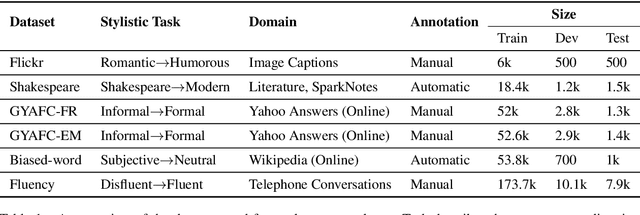

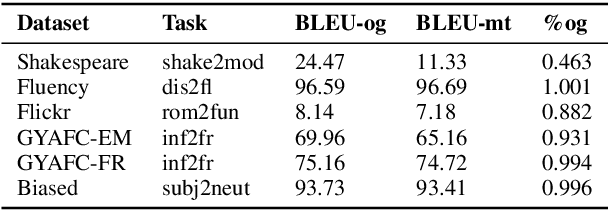
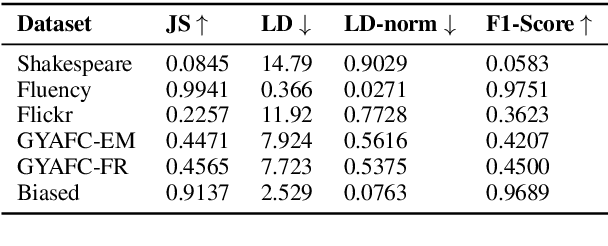
Text style transfer involves rewriting the content of a source sentence in a target style. Despite there being a number of style tasks with available data, there has been limited systematic discussion of how text style datasets relate to each other. This understanding, however, is likely to have implications for selecting multiple data sources for model training. While it is prudent to consider inherent stylistic properties when determining these relationships, we also must consider how a style is realized in a particular dataset. In this paper, we conduct several empirical analyses of existing text style datasets. Based on our results, we propose a categorization of stylistic and dataset properties to consider when utilizing or comparing text style datasets.
Underreporting of errors in NLG output, and what to do about it
Aug 08, 2021
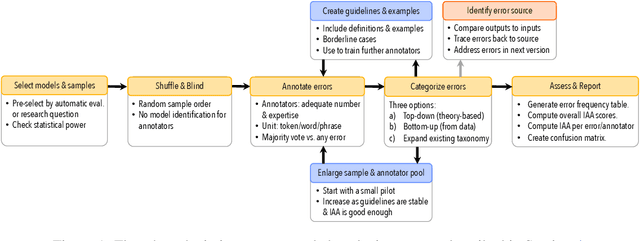
We observe a severe under-reporting of the different kinds of errors that Natural Language Generation systems make. This is a problem, because mistakes are an important indicator of where systems should still be improved. If authors only report overall performance metrics, the research community is left in the dark about the specific weaknesses that are exhibited by `state-of-the-art' research. Next to quantifying the extent of error under-reporting, this position paper provides recommendations for error identification, analysis and reporting.