 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualizing Variation in Text Style Transfer Datasets
Paper and Code
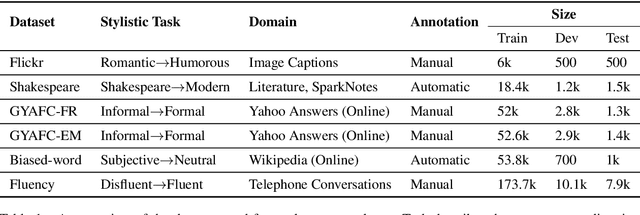

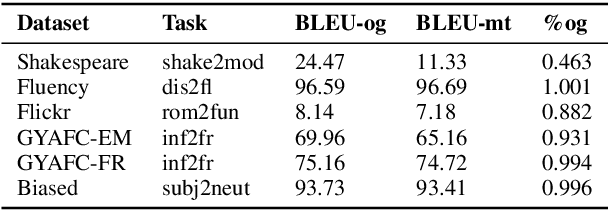
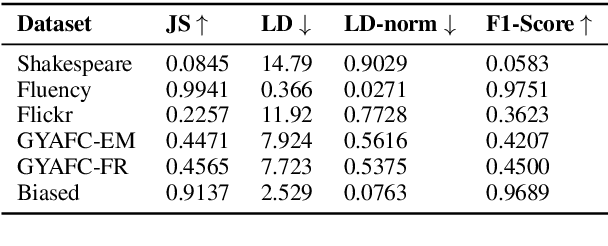
Text style transfer involves rewriting the content of a source sentence in a target style. Despite there being a number of style tasks with available data, there has been limited systematic discussion of how text style datasets relate to each other. This understanding, however, is likely to have implications for selecting multiple data sources for model training. While it is prudent to consider inherent stylistic properties when determining these relationships, we also must consider how a style is realized in a particular dataset. In this paper, we conduct several empirical analyses of existing text style datasets. Based on our results, we propose a categorization of stylistic and dataset properties to consider when utilizing or comparing text style datasets.