 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe QCET Taxonomy of Standard Quality Criterion Names and Definitions for the Evaluation of NLP Systems
Sep 26, 2025



Prior work has shown that two NLP evaluation experiments that report results for the same quality criterion name (e.g. Fluency) do not necessarily evaluate the same aspect of quality, and the comparability implied by the name can be misleading. Not knowing when two evaluations are comparable in this sense means we currently lack the ability to draw reliable conclusions about system quality on the basis of multiple, independently conducted evaluations. This in turn hampers the ability of the field to progress scientifically as a whole, a pervasive issue in NLP since its beginning (Sparck Jones, 1981). It is hard to see how the issue of unclear comparability can be fully addressed other than by the creation of a standard set of quality criterion names and definitions that the several hundred quality criterion names actually in use in the field can be mapped to, and grounded in. Taking a strictly descriptive approach, the QCET Quality Criteria for Evaluation Taxonomy derives a standard set of quality criterion names and definitions from three surveys of evaluations reported in NLP, and structures them into a hierarchy where each parent node captures common aspects of its child nodes. We present QCET and the resources it consists of, and discuss its three main uses in (i) establishing comparability of existing evaluations, (ii) guiding the design of new evaluations, and (iii) assessing regulatory compliance.
HEDS 3.0: The Human Evaluation Data Sheet Version 3.0
Dec 10, 2024This paper presents version 3.0 of the Human Evaluation Datasheet (HEDS). This update is the result of our experience using HEDS in the context of numerous recent human evaluation experiments, including reproduction studies, and of feedback received. Our main overall goal was to improve clarity, and to enable users to complete the datasheet more consistently and comparably. The HEDS 3.0 package consists of the digital data sheet, documentation, and code for exporting completed data sheets as latex files, all available from the HEDS GitHub.
AI-based traffic analysis in digital twin networks
Nov 01, 2024In today's networked world, Digital Twin Networks (DTNs) are revolutionizing how we understand and optimize physical networks. These networks, also known as 'Digital Twin Networks (DTNs)' or 'Networks Digital Twins (NDTs),' encompass many physical networks, from cellular and wireless to optical and satellite. They leverage computational power and AI capabilities to provide virtual representations, leading to highly refined recommendations for real-world network challenges. Within DTNs, tasks include network performance enhancement, latency optimization, energy efficiency, and more. To achieve these goals, DTNs utilize AI tools such as Machine Learning (ML), Deep Learning (DL), Reinforcement Learning (RL), Federated Learning (FL), and graph-based approaches. However, data quality, scalability, interpretability, and security challenges necessitate strategies prioritizing transparency, fairness, privacy, and accountability. This chapter delves into the world of AI-driven traffic analysis within DTNs. It explores DTNs' development efforts, tasks, AI models, and challenges while offering insights into how AI can enhance these dynamic networks. Through this journey, readers will gain a deeper understanding of the pivotal role AI plays in the ever-evolving landscape of networked systems.
AI in Energy Digital Twining: A Reinforcement Learning-based Adaptive Digital Twin Model for Green Cities
Jan 28, 2024Digital Twins (DT) have become crucial to achieve sustainable and effective smart urban solutions. However, current DT modelling techniques cannot support the dynamicity of these smart city environments. This is caused by the lack of right-time data capturing in traditional approaches, resulting in inaccurate modelling and high resource and energy consumption challenges. To fill this gap, we explore spatiotemporal graphs and propose the Reinforcement Learning-based Adaptive Twining (RL-AT) mechanism with Deep Q Networks (DQN). By doing so, our study contributes to advancing Green Cities and showcases tangible benefits in accuracy, synchronisation, resource optimization, and energy efficiency. As a result, we note the spatiotemporal graphs are able to offer a consistent accuracy and 55% higher querying performance when implemented using graph databases. In addition, our model demonstrates right-time data capturing with 20% lower overhead and 25% lower energy consumption.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023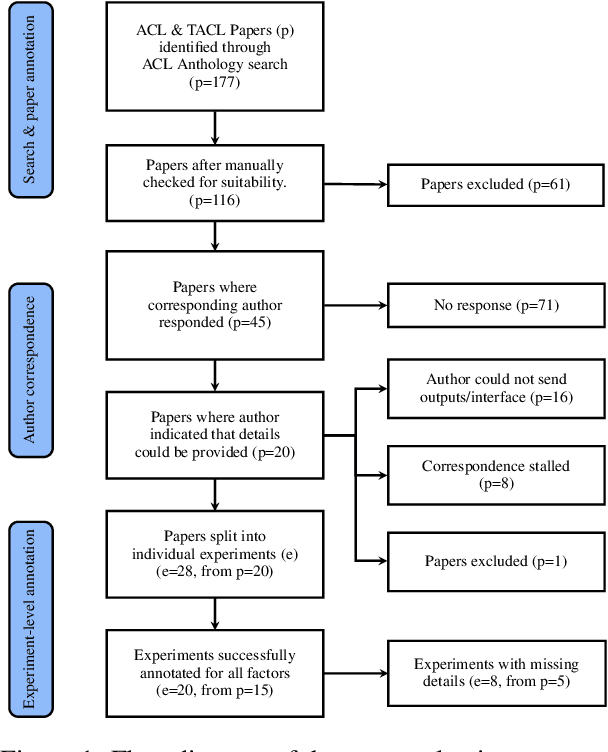
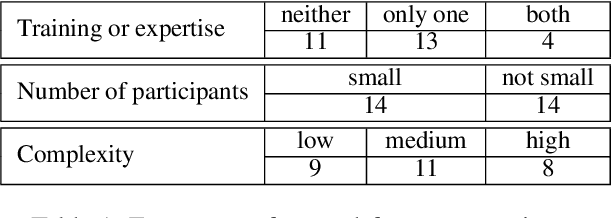


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Generation Challenges: Results of the Accuracy Evaluation Shared Task
Aug 15, 2021


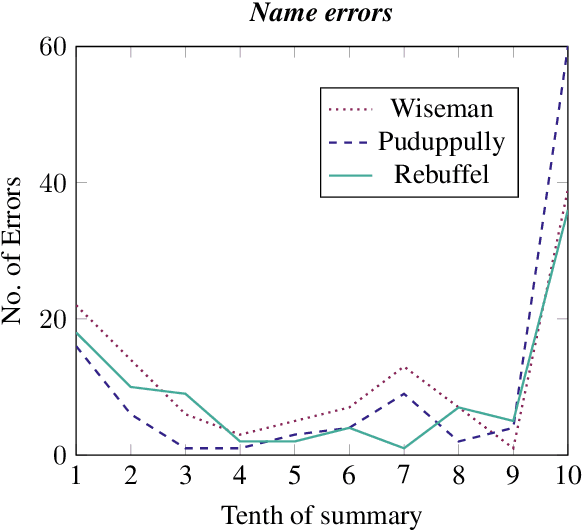
The Shared Task on Evaluating Accuracy focused on techniques (both manual and automatic) for evaluating the factual accuracy of texts produced by neural NLG systems, in a sports-reporting domain. Four teams submitted evaluation techniques for this task, using very different approaches and techniques. The best-performing submissions did encouragingly well at this difficult task. However, all automatic submissions struggled to detect factual errors which are semantically or pragmatically complex (for example, based on incorrect computation or inference).
Underreporting of errors in NLG output, and what to do about it
Aug 08, 2021
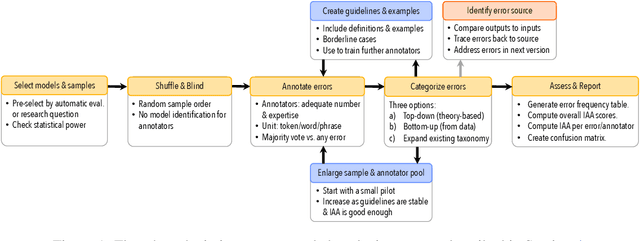
We observe a severe under-reporting of the different kinds of errors that Natural Language Generation systems make. This is a problem, because mistakes are an important indicator of where systems should still be improved. If authors only report overall performance metrics, the research community is left in the dark about the specific weaknesses that are exhibited by `state-of-the-art' research. Next to quantifying the extent of error under-reporting, this position paper provides recommendations for error identification, analysis and reporting.
A Gold Standard Methodology for Evaluating Accuracy in Data-To-Text Systems
Nov 08, 2020



Most Natural Language Generation systems need to produce accurate texts. We propose a methodology for high-quality human evaluation of the accuracy of generated texts, which is intended to serve as a gold-standard for accuracy evaluations of data-to-text systems. We use our methodology to evaluate the accuracy of computer generated basketball summaries. We then show how our gold standard evaluation can be used to validate automated metrics
Shared Task on Evaluating Accuracy in Natural Language Generation
Jun 22, 2020We propose a shared task on methodologies and algorithms for evaluating the accuracy of generated texts. Participants will measure the accuracy of basketball game summaries produced by NLG systems from basketball box score data.