 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASTRIE: A Corpus of Prepositions Annotated with Supersense Tags in Reddit International English
Oct 23, 2021
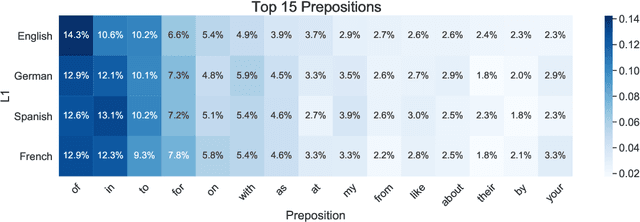


We present the Prepositions Annotated with Supersense Tags in Reddit International English ("PASTRIE") corpus, a new dataset containing manually annotated preposition supersenses of English data from presumed speakers of four L1s: English, French, German, and Spanish. The annotations are comprehensive, covering all preposition types and tokens in the sample. Along with the corpus, we provide analysis of distributional patterns across the included L1s and a discussion of the influence of L1s on L2 preposition choice.
Underreporting of errors in NLG output, and what to do about it
Aug 08, 2021
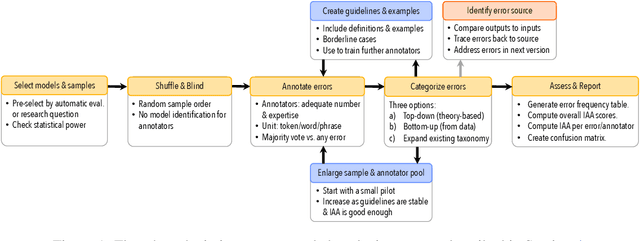
We observe a severe under-reporting of the different kinds of errors that Natural Language Generation systems make. This is a problem, because mistakes are an important indicator of where systems should still be improved. If authors only report overall performance metrics, the research community is left in the dark about the specific weaknesses that are exhibited by `state-of-the-art' research. Next to quantifying the extent of error under-reporting, this position paper provides recommendations for error identification, analysis and reporting.
A Human Evaluation of AMR-to-English Generation Systems
Apr 14, 2020
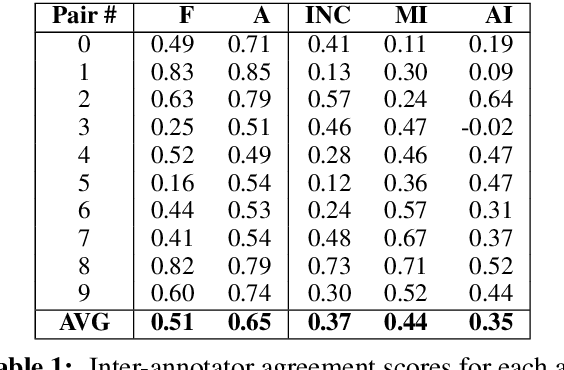
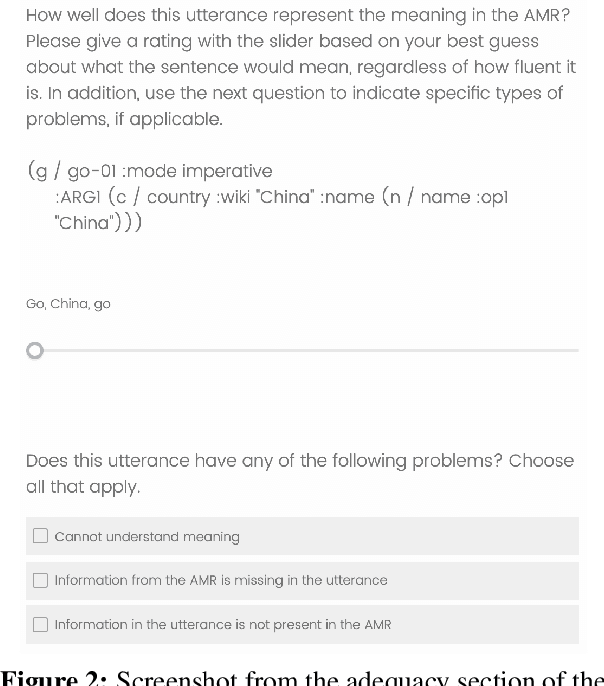
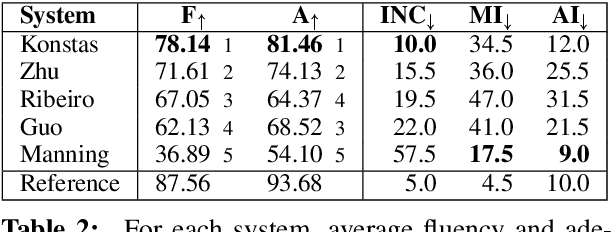
Most current state-of-the art systems for generating English text from Abstract Meaning Representation (AMR) have been evaluated only using automated metrics, such as BLEU, which are known to be problematic for natural language generation. In this work, we present the results of a new human evaluation which collects fluency and adequacy scores, as well as categorization of error types, for several recent AMR generation systems. We discuss the relative quality of these systems and how our results compare to those of automatic metrics, finding that while the metrics are mostly successful in ranking systems overall, collecting human judgments allows for more nuanced comparisons. We also analyze common errors made by these systems.