Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human Evaluation of AMR-to-English Generation Systems
Paper and Code
Apr 14, 2020
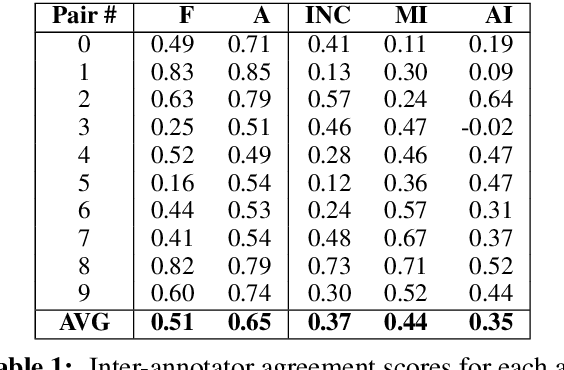
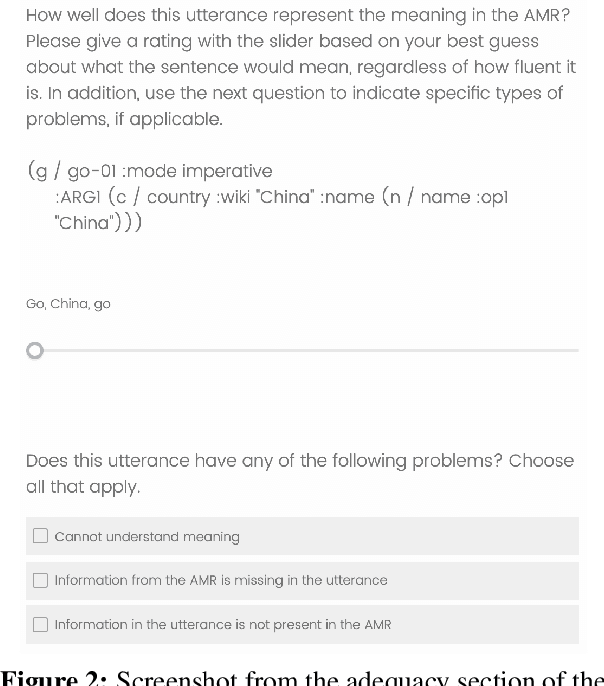
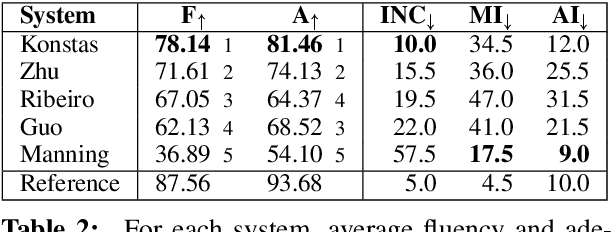
Most current state-of-the art systems for generating English text from Abstract Meaning Representation (AMR) have been evaluated only using automated metrics, such as BLEU, which are known to be problematic for natural language generation. In this work, we present the results of a new human evaluation which collects fluency and adequacy scores, as well as categorization of error types, for several recent AMR generation systems. We discuss the relative quality of these systems and how our results compare to those of automatic metrics, finding that while the metrics are mostly successful in ranking systems overall, collecting human judgments allows for more nuanced comparisons. We also analyze common errors made by these systems.
View paper on