 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Span Annotators
Apr 11, 2025For high-quality texts, single-score metrics seldom provide actionable feedback. In contrast, span annotation - pointing out issues in the text by annotating their spans - can guide improvements and provide insights. Until recently, span annotation was limited to human annotators or fine-tuned encoder models. In this study, we automate span annotation with large language models (LLMs). We compare expert or skilled crowdworker annotators with open and proprietary LLMs on three tasks: data-to-text generation evaluation, machine translation evaluation, and propaganda detection in human-written texts. In our experiments, we show that LLMs as span annotators are straightforward to implement and notably more cost-efficient than human annotators. The LLMs achieve moderate agreement with skilled human annotators, in some scenarios comparable to the average agreement among the annotators themselves. Qualitative analysis shows that reasoning models outperform their instruction-tuned counterparts and provide more valid explanations for annotations. We release the dataset of more than 40k model and human annotations for further research.
Automatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
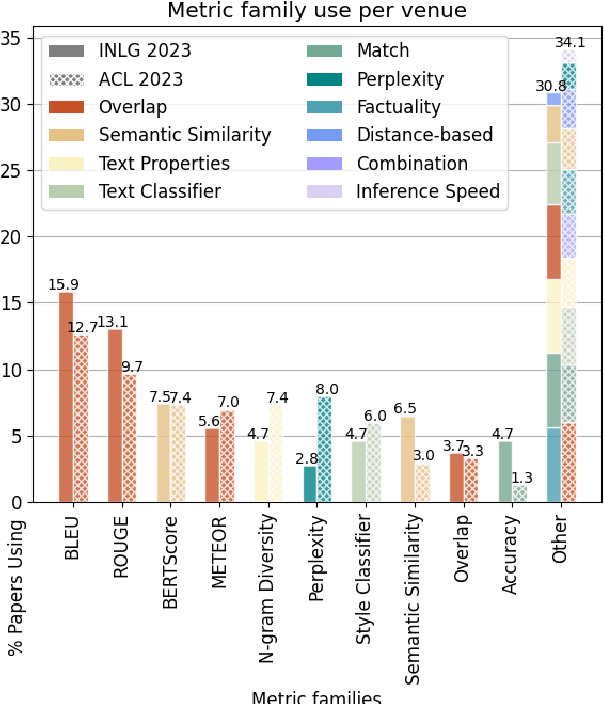
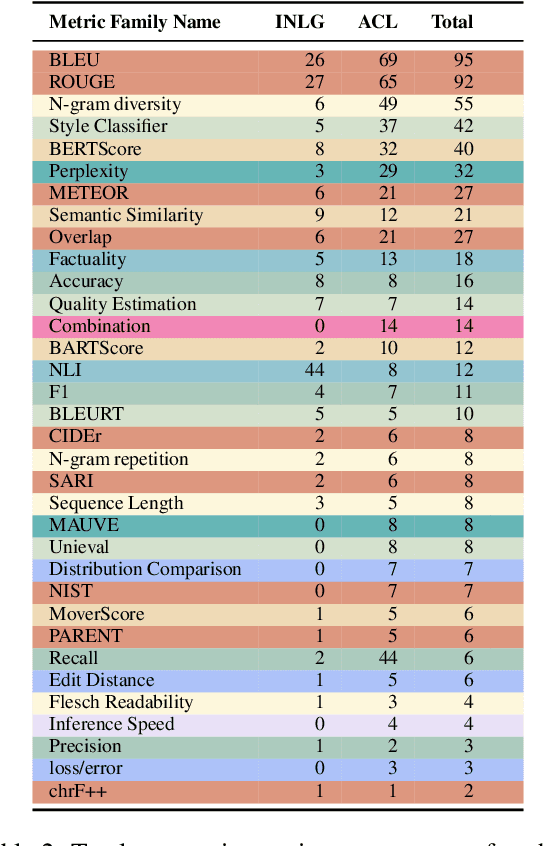
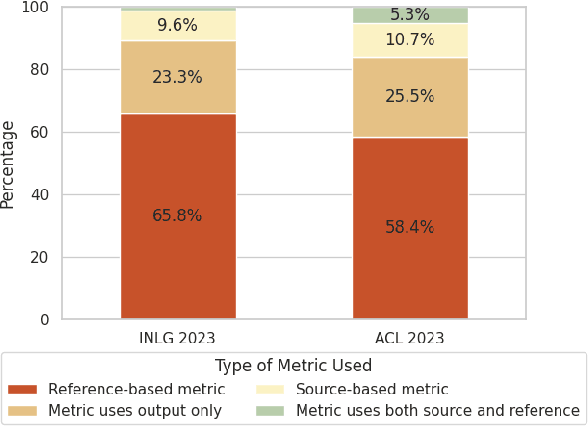
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023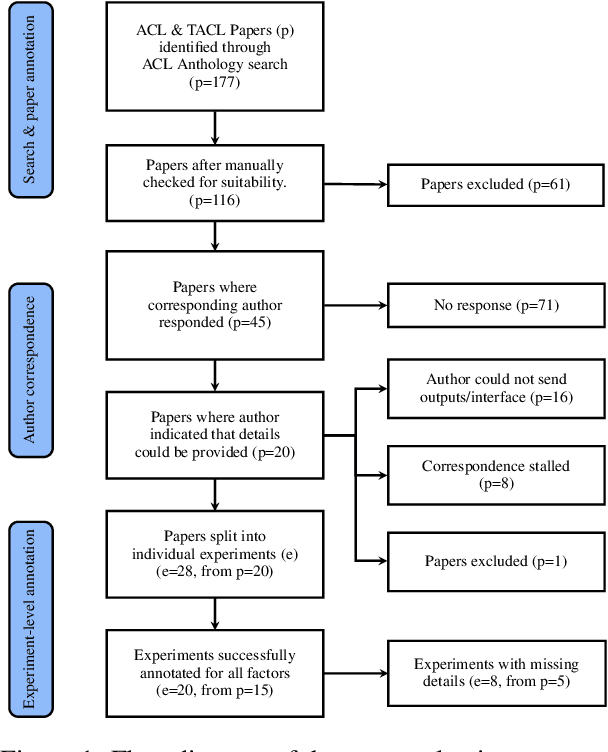
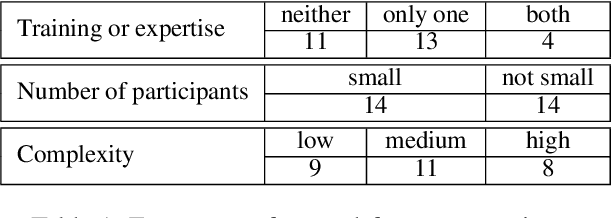


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
You Are What You Write: Preserving Privacy in the Era of Large Language Models
Apr 20, 2022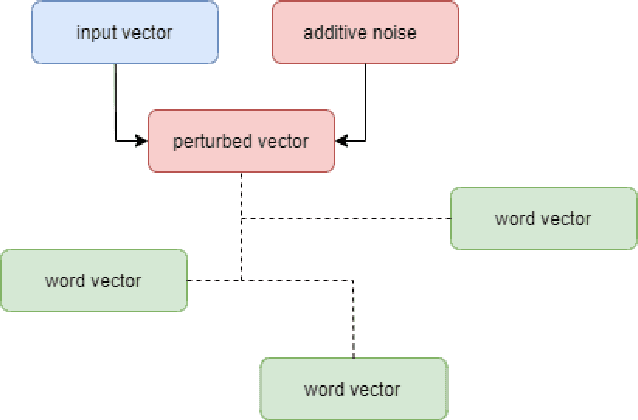

Large scale adoption of large language models has introduced a new era of convenient knowledge transfer for a slew of natural language processing tasks. However, these models also run the risk of undermining user trust by exposing unwanted information about the data subjects, which may be extracted by a malicious party, e.g. through adversarial attacks. We present an empirical investigation into the extent of the personal information encoded into pre-trained representations by a range of popular models, and we show a positive correlation between the complexity of a model, the amount of data used in pre-training, and data leakage. In this paper, we present the first wide coverage evaluation and comparison of some of the most popular privacy-preserving algorithms, on a large, multi-lingual dataset on sentiment analysis annotated with demographic information (location, age and gender). The results show since larger and more complex models are more prone to leaking private information, use of privacy-preserving methods is highly desirable. We also find that highly privacy-preserving technologies like differential privacy (DP) can have serious model utility effects, which can be ameliorated using hybrid or metric-DP techniques.
Task2Dial: A Novel Task and Dataset for Commonsense enhanced Task-based Dialogue Grounded in Documents
Apr 03, 2022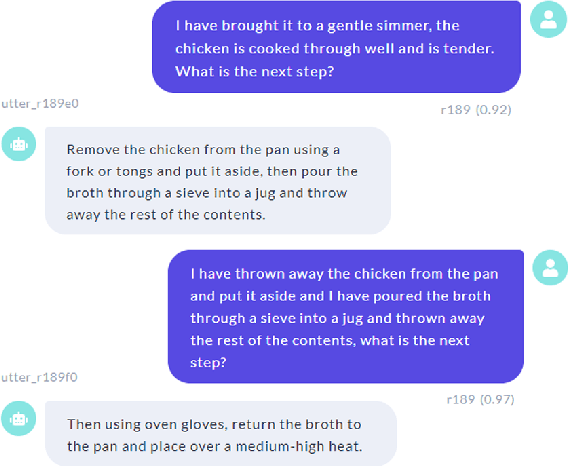

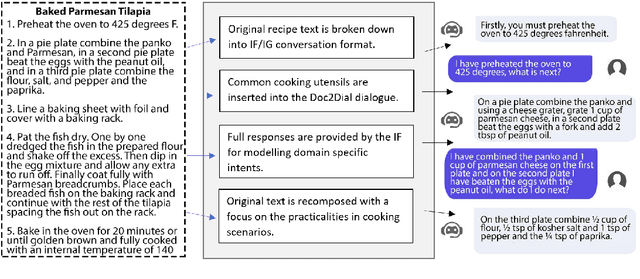

This paper proposes a novel task on commonsense-enhanced task-based dialogue grounded in documents and describes the Task2Dial dataset, a novel dataset of document-grounded task-based dialogues, where an Information Giver (IG) provides instructions (by consulting a document) to an Information Follower (IF), so that the latter can successfully complete the task. In this unique setting, the IF can ask clarification questions which may not be grounded in the underlying document and require commonsense knowledge to be answered. The Task2Dial dataset poses new challenges: (1) its human reference texts show more lexical richness and variation than other document-grounded dialogue datasets; (2) generating from this set requires paraphrasing as instructional responses might have been modified from the underlying document; (3) requires commonsense knowledge, since questions might not necessarily be grounded in the document; (4) generating requires planning based on context, as task steps need to be provided in order. The Task2Dial dataset contains dialogues with an average $18.15$ number of turns and 19.79 tokens per turn, as compared to 12.94 and 12 respectively in existing datasets. As such, learning from this dataset promises more natural, varied and less template-like system utterances.
CAPE: Context-Aware Private Embeddings for Private Language Learning
Aug 27, 2021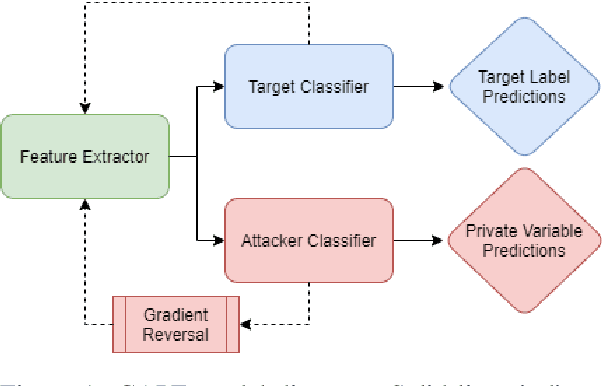
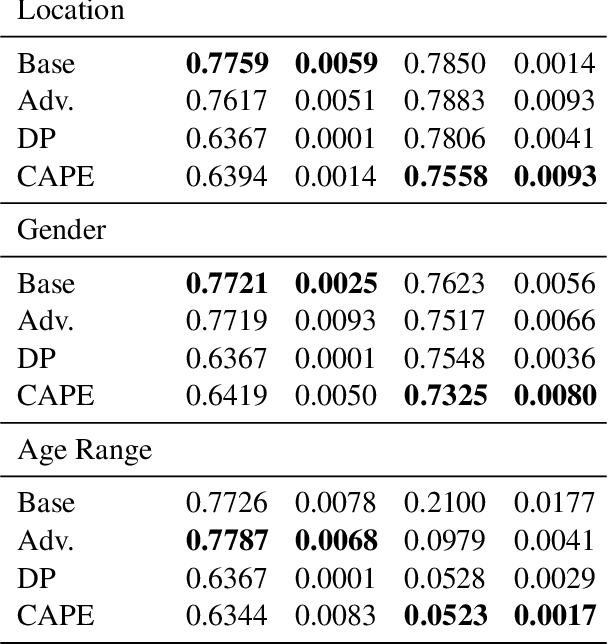
Deep learning-based language models have achieved state-of-the-art results in a number of applications including sentiment analysis, topic labelling, intent classification and others. Obtaining text representations or embeddings using these models presents the possibility of encoding personally identifiable information learned from language and context cues that may present a risk to reputation or privacy. To ameliorate these issues, we propose Context-Aware Private Embeddings (CAPE), a novel approach which preserves privacy during training of embeddings. To maintain the privacy of text representations, CAPE applies calibrated noise through differential privacy, preserving the encoded semantic links while obscuring sensitive information. In addition, CAPE employs an adversarial training regime that obscures identified private variables. Experimental results demonstrate that the proposed approach reduces private information leakage better than either single intervention.
Underreporting of errors in NLG output, and what to do about it
Aug 08, 2021
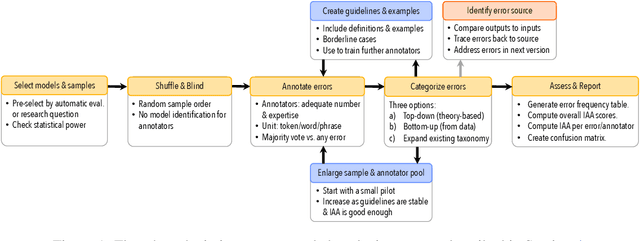
We observe a severe under-reporting of the different kinds of errors that Natural Language Generation systems make. This is a problem, because mistakes are an important indicator of where systems should still be improved. If authors only report overall performance metrics, the research community is left in the dark about the specific weaknesses that are exhibited by `state-of-the-art' research. Next to quantifying the extent of error under-reporting, this position paper provides recommendations for error identification, analysis and reporting.
Content Selection in Data-to-Text Systems: A Survey
Oct 26, 2016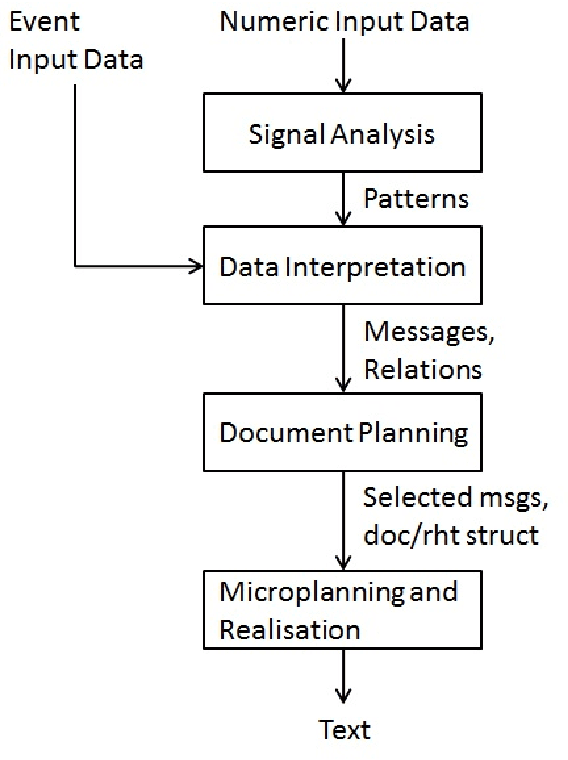

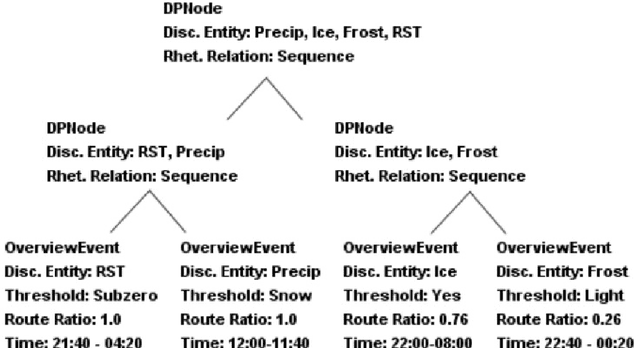

Data-to-text systems are powerful in generating reports from data automatically and thus they simplify the presentation of complex data. Rather than presenting data using visualisation techniques, data-to-text systems use natural (human) language, which is the most common way for human-human communication. In addition, data-to-text systems can adapt their output content to users' preferences, background or interests and therefore they can be pleasant for users to interact with. Content selection is an important part of every data-to-text system, because it is the module that determines which from the available information should be conveyed to the user. This survey initially introduces the field of data-to-text generation, describes the general data-to-text system architecture and then it reviews the state-of-the-art content selection methods. Finally, it provides recommendations for choosing an approach and discusses opportunities for future research.
Natural Language Generation enhances human decision-making with uncertain information
Aug 15, 2016
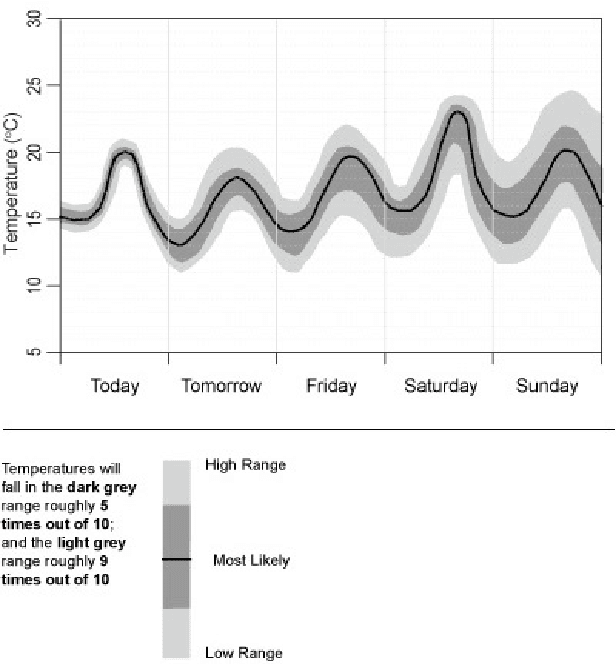

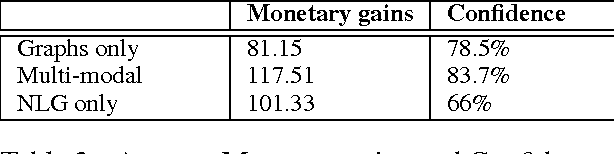
Decision-making is often dependent on uncertain data, e.g. data associated with confidence scores or probabilities. We present a comparison of different information presentations for uncertain data and, for the first time, measure their effects on human decision-making. We show that the use of Natural Language Generation (NLG) improves decision-making under uncertainty, compared to state-of-the-art graphical-based representation methods. In a task-based study with 442 adults, we found that presentations using NLG lead to 24% better decision-making on average than the graphical presentations, and to 44% better decision-making when NLG is combined with graphics. We also show that women achieve significantly better results when presented with NLG output (an 87% increase on average compared to graphical presentations).