 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Span Annotators
Apr 11, 2025For high-quality texts, single-score metrics seldom provide actionable feedback. In contrast, span annotation - pointing out issues in the text by annotating their spans - can guide improvements and provide insights. Until recently, span annotation was limited to human annotators or fine-tuned encoder models. In this study, we automate span annotation with large language models (LLMs). We compare expert or skilled crowdworker annotators with open and proprietary LLMs on three tasks: data-to-text generation evaluation, machine translation evaluation, and propaganda detection in human-written texts. In our experiments, we show that LLMs as span annotators are straightforward to implement and notably more cost-efficient than human annotators. The LLMs achieve moderate agreement with skilled human annotators, in some scenarios comparable to the average agreement among the annotators themselves. Qualitative analysis shows that reasoning models outperform their instruction-tuned counterparts and provide more valid explanations for annotations. We release the dataset of more than 40k model and human annotations for further research.
OpeNLGauge: An Explainable Metric for NLG Evaluation with Open-Weights LLMs
Mar 14, 2025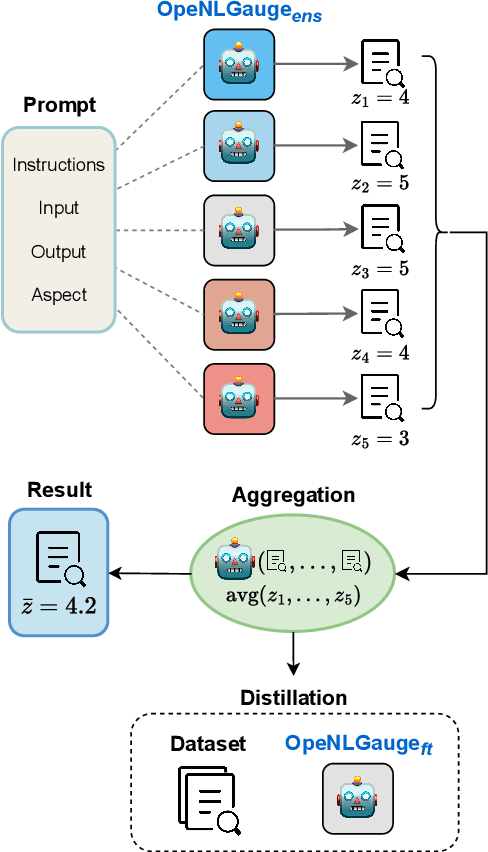


Large Language Models (LLMs) have demonstrated great potential as evaluators of NLG systems, allowing for high-quality, reference-free, and multi-aspect assessments. However, existing LLM-based metrics suffer from two major drawbacks: reliance on proprietary models to generate training data or perform evaluations, and a lack of fine-grained, explanatory feedback. In this paper, we introduce OpeNLGauge, a fully open-source, reference-free NLG evaluation metric that provides accurate explanations based on error spans. OpeNLGauge is available as a two-stage ensemble of larger open-weight LLMs, or as a small fine-tuned evaluation model, with confirmed generalizability to unseen tasks, domains and aspects. Our extensive meta-evaluation shows that OpeNLGauge achieves competitive correlation with human judgments, outperforming state-of-the-art models on certain tasks while maintaining full reproducibility and providing explanations more than twice as accurate.