 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpeNLGauge: An Explainable Metric for NLG Evaluation with Open-Weights LLMs
Paper and Code
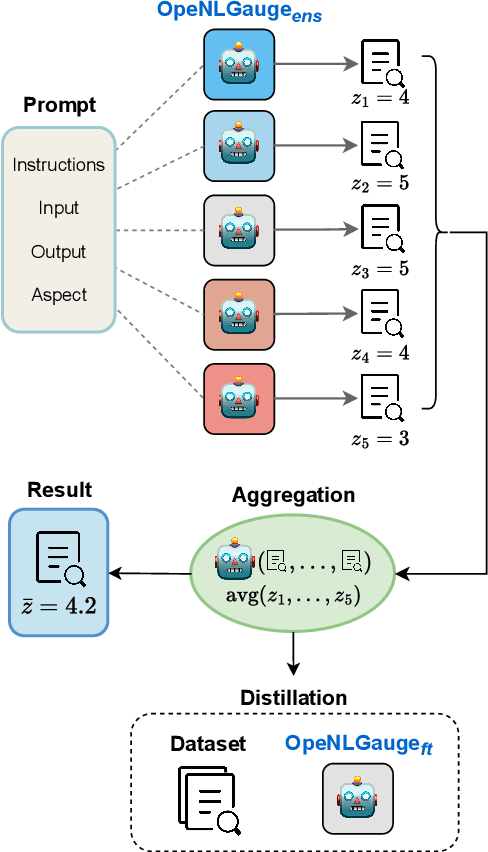


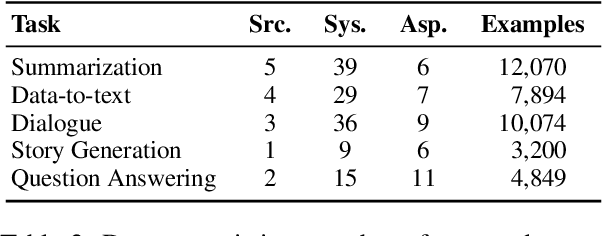
Large Language Models (LLMs) have demonstrated great potential as evaluators of NLG systems, allowing for high-quality, reference-free, and multi-aspect assessments. However, existing LLM-based metrics suffer from two major drawbacks: reliance on proprietary models to generate training data or perform evaluations, and a lack of fine-grained, explanatory feedback. In this paper, we introduce OpeNLGauge, a fully open-source, reference-free NLG evaluation metric that provides accurate explanations based on error spans. OpeNLGauge is available as a two-stage ensemble of larger open-weight LLMs, or as a small fine-tuned evaluation model, with confirmed generalizability to unseen tasks, domains and aspects. Our extensive meta-evaluation shows that OpeNLGauge achieves competitive correlation with human judgments, outperforming state-of-the-art models on certain tasks while maintaining full reproducibility and providing explanations more than twice as accurate.