 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Summarization: When Evaluation Reaches Its Limits
Jul 15, 2025We examine evaluation of faithfulness to input data in the context of hotel highlights: brief LLM-generated summaries that capture unique features of accommodations. Through human evaluation campaigns involving categorical error assessment and span-level annotation, we compare traditional metrics, trainable methods, and LLM-as-a-judge approaches. Our findings reveal that simpler metrics like word overlap correlate surprisingly well with human judgments (Spearman correlation rank of 0.63), often outperforming more complex methods when applied to out-of-domain data. We further demonstrate that while LLMs can generate high-quality highlights, they prove unreliable for evaluation as they tend to severely under- or over-annotate. Our analysis of real-world business impacts shows incorrect and non-checkable information pose the greatest risks. We also highlight challenges in crowdsourced evaluations.
Large Language Models as Span Annotators
Apr 11, 2025For high-quality texts, single-score metrics seldom provide actionable feedback. In contrast, span annotation - pointing out issues in the text by annotating their spans - can guide improvements and provide insights. Until recently, span annotation was limited to human annotators or fine-tuned encoder models. In this study, we automate span annotation with large language models (LLMs). We compare expert or skilled crowdworker annotators with open and proprietary LLMs on three tasks: data-to-text generation evaluation, machine translation evaluation, and propaganda detection in human-written texts. In our experiments, we show that LLMs as span annotators are straightforward to implement and notably more cost-efficient than human annotators. The LLMs achieve moderate agreement with skilled human annotators, in some scenarios comparable to the average agreement among the annotators themselves. Qualitative analysis shows that reasoning models outperform their instruction-tuned counterparts and provide more valid explanations for annotations. We release the dataset of more than 40k model and human annotations for further research.
Automatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
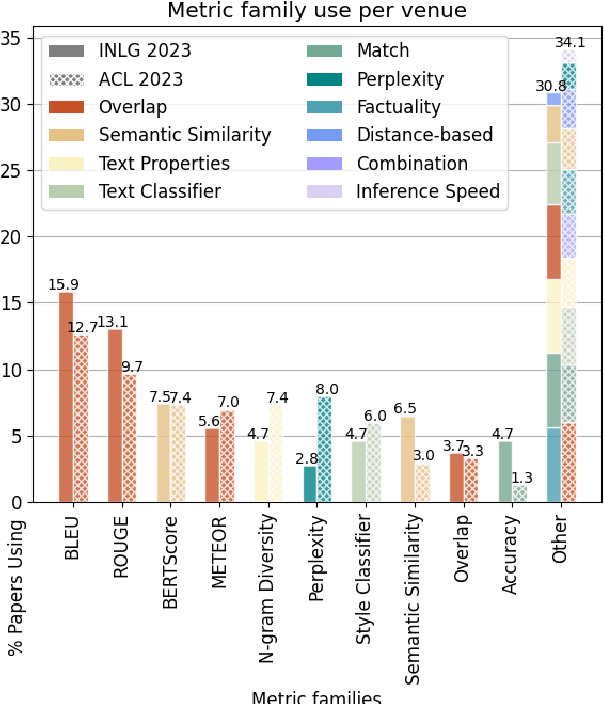
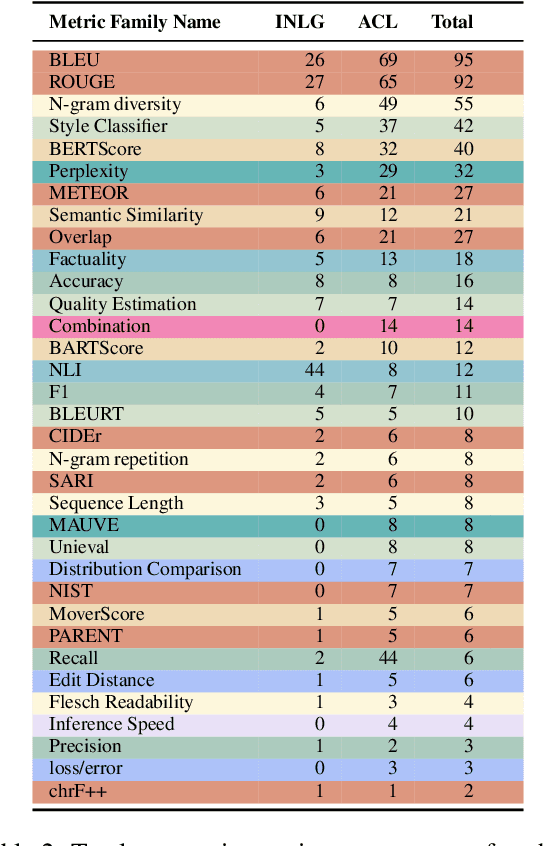
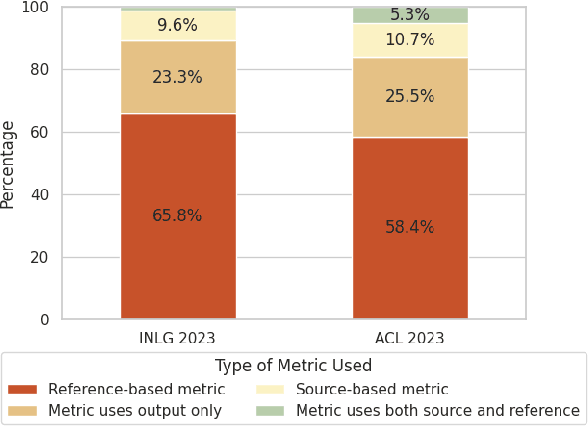
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
factgenie: A Framework for Span-based Evaluation of Generated Texts
Jul 25, 2024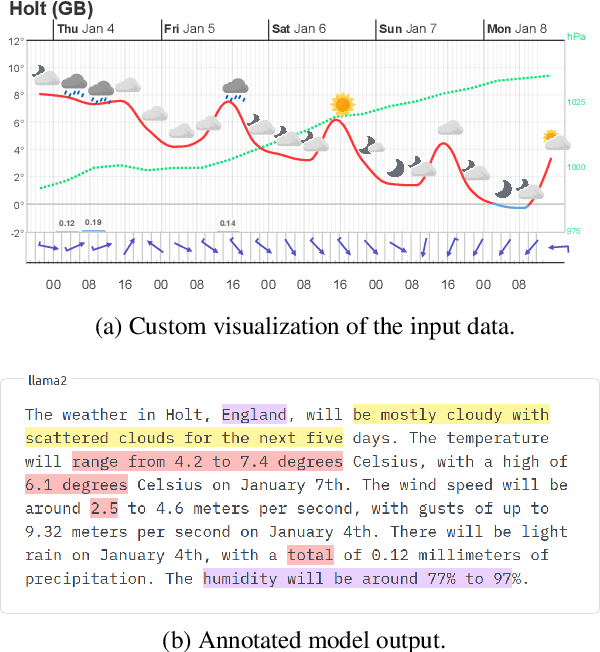
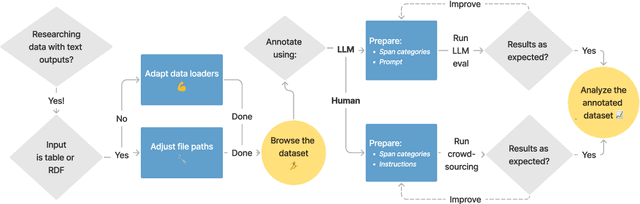
We present factgenie: a framework for annotating and visualizing word spans in textual model outputs. Annotations can capture various span-based phenomena such as semantic inaccuracies or irrelevant text. With factgenie, the annotations can be collected both from human crowdworkers and large language models. Our framework consists of a web interface for data visualization and gathering text annotations, powered by an easily extensible codebase.
Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs
Feb 06, 2024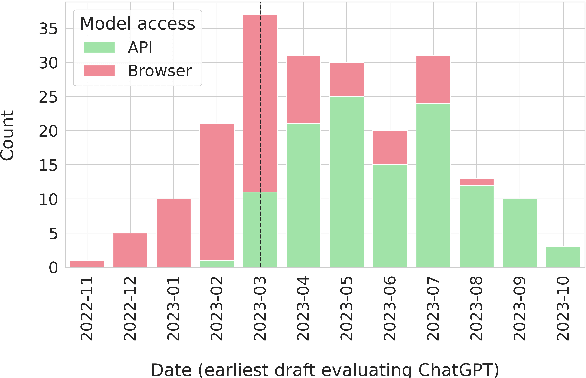
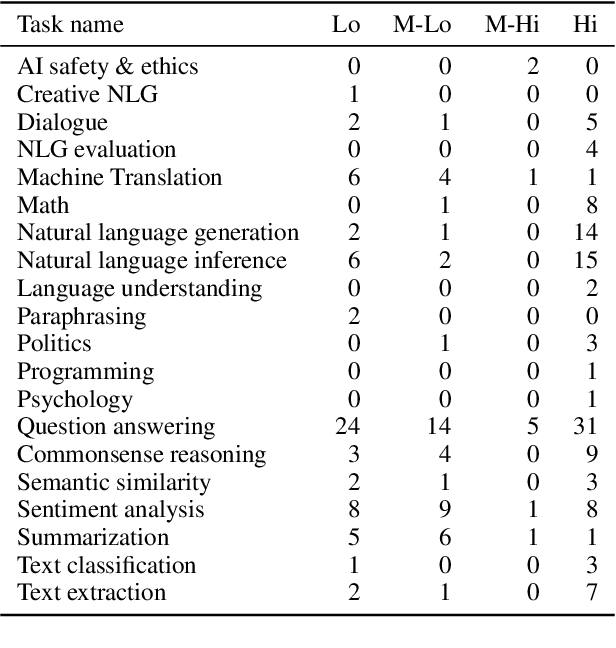
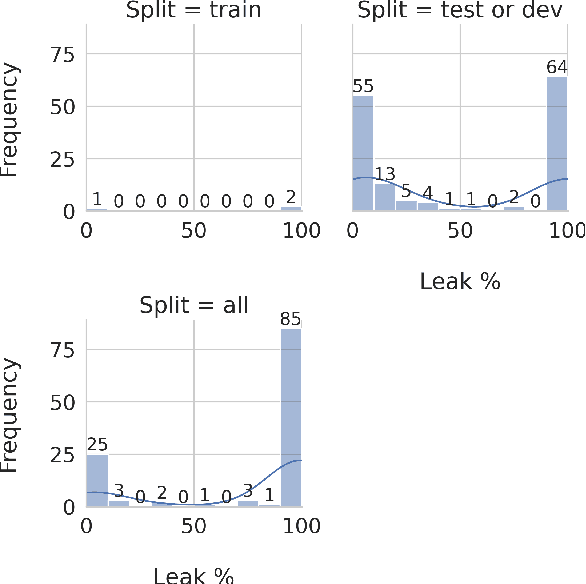
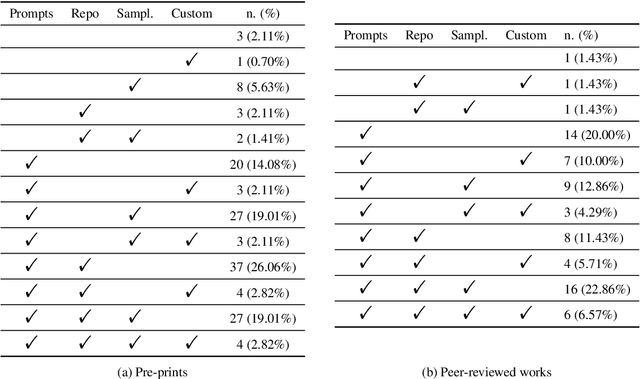
Natural Language Processing (NLP) research is increasingly focusing on the use of Large Language Models (LLMs), with some of the most popular ones being either fully or partially closed-source. The lack of access to model details, especially regarding training data, has repeatedly raised concerns about data contamination among researchers. Several attempts have been made to address this issue, but they are limited to anecdotal evidence and trial and error. Additionally, they overlook the problem of \emph{indirect} data leaking, where models are iteratively improved by using data coming from users. In this work, we conduct the first systematic analysis of work using OpenAI's GPT-3.5 and GPT-4, the most prominently used LLMs today, in the context of data contamination. By analysing 255 papers and considering OpenAI's data usage policy, we extensively document the amount of data leaked to these models during the first year after the model's release. We report that these models have been globally exposed to $\sim$4.7M samples from 263 benchmarks. At the same time, we document a number of evaluation malpractices emerging in the reviewed papers, such as unfair or missing baseline comparisons and reproducibility issues. We release our results as a collaborative project on https://leak-llm.github.io/, where other researchers can contribute to our efforts.
DialogueScript: Using Dialogue Agents to Produce a Script
Jun 16, 2022


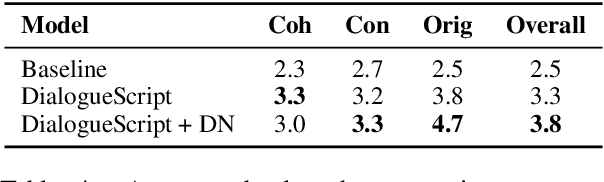
We present a novel approach to generating scripts by using agents with different personality types. To manage character interaction in the script, we employ simulated dramatic networks. Automatic and human evaluation on multiple criteria shows that our approach outperforms a vanilla-GPT2-based baseline. We further introduce a new metric to evaluate dialogue consistency based on natural language inference and demonstrate its validity.
THEaiTRE 1.0: Interactive generation of theatre play scripts
Feb 17, 2021We present the first version of a system for interactive generation of theatre play scripts. The system is based on a vanilla GPT-2 model with several adjustments, targeting specific issues we encountered in practice. We also list other issues we encountered but plan to only solve in a future version of the system. The presented system was used to generate a theatre play script planned for premiere in February 2021.
THEaiTRE: Artificial Intelligence to Write a Theatre Play
Jun 25, 2020We present THEaiTRE, a starting project aimed at automatic generation of theatre play scripts. This paper reviews related work and drafts an approach we intend to follow. We plan to adopt generative neural language models and hierarchical generation approaches, supported by summarization and machine translation methods, and complemented with a human-in-the-loop approach.