 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Debiasing: Remove Stereotypes and Keep Factual Gender for Fair Language Modeling and Translation
Jan 17, 2025Mitigation of biases, such as language models' reliance on gender stereotypes, is a crucial endeavor required for the creation of reliable and useful language technology. The crucial aspect of debiasing is to ensure that the models preserve their versatile capabilities, including their ability to solve language tasks and equitably represent various genders. To address this issue, we introduce a streamlined Dual Dabiasing Algorithm through Model Adaptation (2DAMA). Novel Dual Debiasing enables robust reduction of stereotypical bias while preserving desired factual gender information encoded by language models. We show that 2DAMA effectively reduces gender bias in English and is one of the first approaches facilitating the mitigation of stereotypical tendencies in translation. The proposed method's key advantage is the preservation of factual gender cues, which are useful in a wide range of natural language processing tasks.
Transforming Hidden States into Binary Semantic Features
Sep 29, 2024Large language models follow a lineage of many NLP applications that were directly inspired by distributional semantics, but do not seem to be closely related to it anymore. In this paper, we propose to employ the distributional theory of meaning once again. Using Independent Component Analysis to overcome some of its challenging aspects, we show that large language models represent semantic features in their hidden states.
Debiasing Algorithm through Model Adaptation
Oct 29, 2023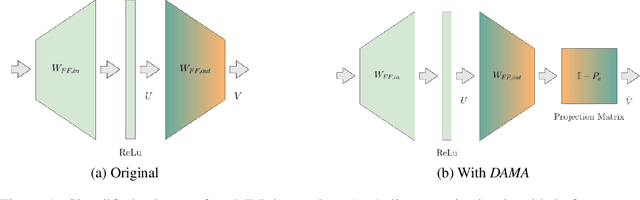
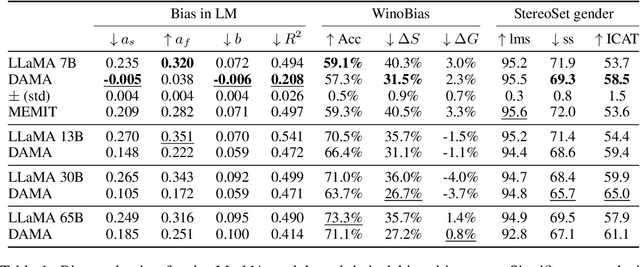
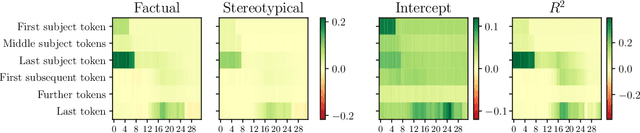
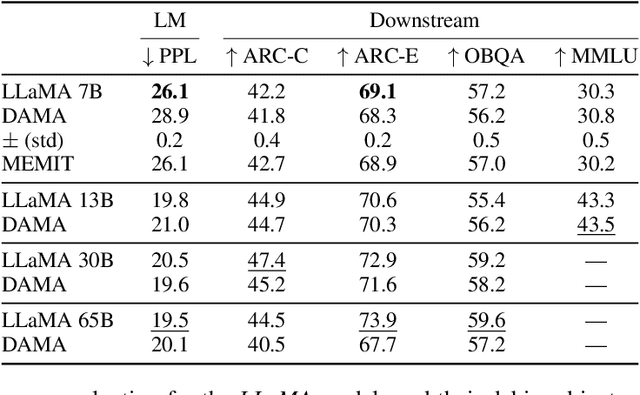
Large language models are becoming the go-to solution for various language tasks. However, with growing capacity, models are prone to rely on spurious correlations stemming from biases and stereotypes present in the training data. This work proposes a novel method for detecting and mitigating gender bias in language models. We perform causal analysis to identify problematic model components and discover that mid-upper feed-forward layers are most prone to convey biases. Based on the analysis results, we adapt the model by multiplying these layers by a linear projection. Our titular method, DAMA, significantly decreases bias as measured by diverse metrics while maintaining the model's performance on downstream tasks. We release code for our method and models, which retrain LLaMA's state-of-the-art performance while being significantly less biased.
Exploring the Impact of Training Data Distribution and Subword Tokenization on Gender Bias in Machine Translation
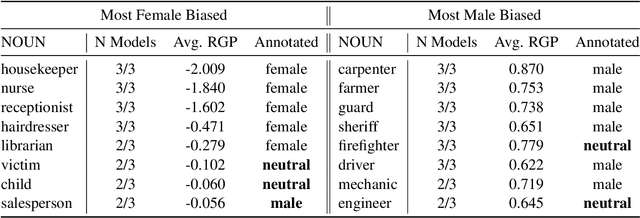
Sep 30, 2023We study the effect of tokenization on gender bias in machine translation, an aspect that has been largely overlooked in previous works. Specifically, we focus on the interactions between the frequency of gendered profession names in training data, their representation in the subword tokenizer's vocabulary, and gender bias. We observe that female and non-stereotypical gender inflections of profession names (e.g., Spanish "doctora" for "female doctor") tend to be split into multiple subword tokens. Our results indicate that the imbalance of gender forms in the model's training corpus is a major factor contributing to gender bias and has a greater impact than subword splitting. We show that analyzing subword splits provides good estimates of gender-form imbalance in the training data and can be used even when the corpus is not publicly available. We also demonstrate that fine-tuning just the token embedding layer can decrease the gap in gender prediction accuracy between female and male forms without impairing the translation quality.
Closing the loop: Autonomous experiments enabled by machine-learning-based online data analysis in synchrotron beamline environments
Jun 20, 2023



Recently, there has been significant interest in applying machine learning (ML) techniques to X-ray scattering experiments, which proves to be a valuable tool for enhancing research that involves large or rapidly generated datasets. ML allows for the automated interpretation of experimental results, particularly those obtained from synchrotron or neutron facilities. The speed at which ML models can process data presents an important opportunity to establish a closed-loop feedback system, enabling real-time decision-making based on online data analysis. In this study, we describe the incorporation of ML into a closed-loop workflow for X-ray reflectometry (XRR), using the growth of organic thin films as an example. Our focus lies on the beamline integration of ML-based online data analysis and closed-loop feedback. We present solutions that provide an elementary data analysis in real time during the experiment without introducing the additional software dependencies in the beamline control software environment. Our data demonstrates the accuracy and robustness of ML methods for analyzing XRR curves and Bragg reflections and its autonomous control over a vacuum deposition setup.
Tokenization Impacts Multilingual Language Modeling: Assessing Vocabulary Allocation and Overlap Across Languages
May 26, 2023



Multilingual language models have recently gained attention as a promising solution for representing multiple languages in a single model. In this paper, we propose new criteria to evaluate the quality of lexical representation and vocabulary overlap observed in sub-word tokenizers. Our findings show that the overlap of vocabulary across languages can be actually detrimental to certain downstream tasks (POS, dependency tree labeling). In contrast, NER and sentence-level tasks (cross-lingual retrieval, NLI) benefit from sharing vocabulary. We also observe that the coverage of the language-specific tokens in the multilingual vocabulary significantly impacts the word-level tasks. Our study offers a deeper understanding of the role of tokenizers in multilingual language models and guidelines for future model developers to choose the most suitable tokenizer for their specific application before undertaking costly model pre-training
Independent Components of Word Embeddings Represent Semantic Features
Dec 19, 2022

Independent Component Analysis (ICA) is an algorithm originally developed for finding separate sources in a mixed signal, such as a recording of multiple people in the same room speaking at the same time. It has also been used to find linguistic features in distributional representations. In this paper, we used ICA to analyze words embeddings. We have found that ICA can be used to find semantic features of the words and these features can easily be combined to search for words that satisfy the combination. We show that only some of the independent components represent such features, but those that do are stable with regard to random initialization of the algorithm.
Don't Forget About Pronouns: Removing Gender Bias in Language Models Without Losing Factual Gender Information
Jun 21, 2022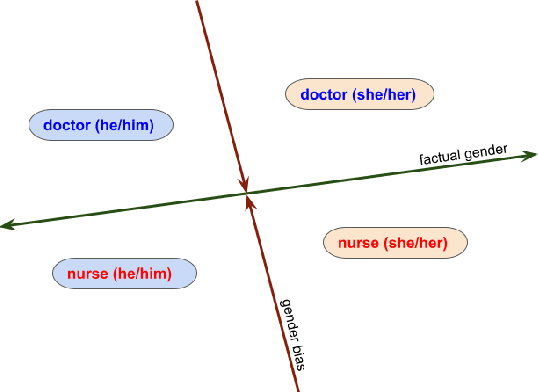


The representations in large language models contain multiple types of gender information. We focus on two types of such signals in English texts: factual gender information, which is a grammatical or semantic property, and gender bias, which is the correlation between a word and specific gender. We can disentangle the model's embeddings and identify components encoding both types of information with probing. We aim to diminish the stereotypical bias in the representations while preserving the factual gender signal. Our filtering method shows that it is possible to decrease the bias of gender-neutral profession names without significant deterioration of language modeling capabilities. The findings can be applied to language generation to mitigate reliance on stereotypes while preserving gender agreement in coreferences.
Examining Cross-lingual Contextual Embeddings with Orthogonal Structural Probes
Sep 10, 2021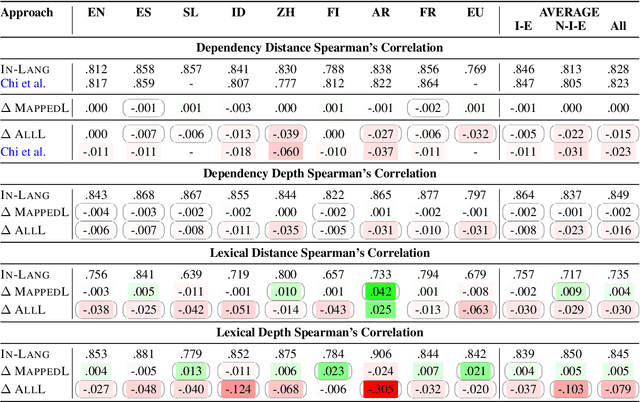
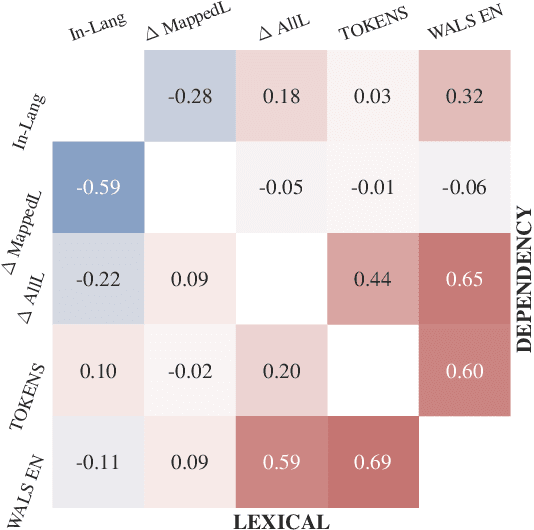
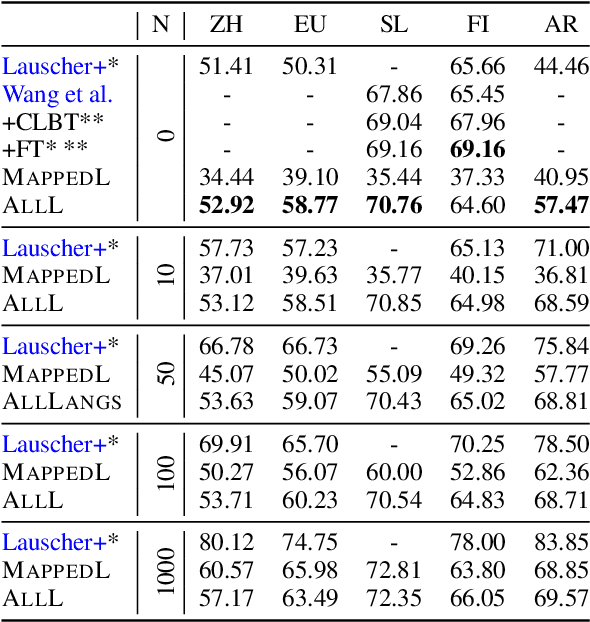
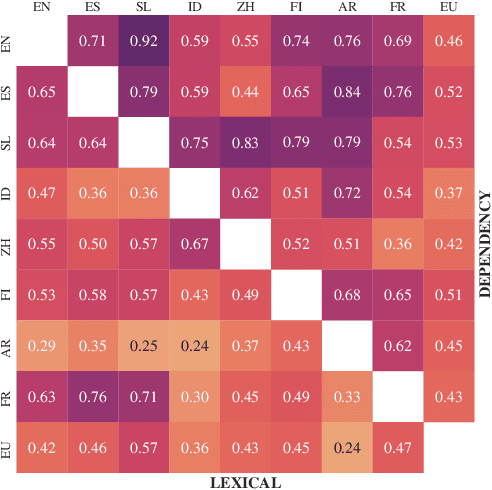
State-of-the-art contextual embeddings are obtained from large language models available only for a few languages. For others, we need to learn representations using a multilingual model. There is an ongoing debate on whether multilingual embeddings can be aligned in a space shared across many languages. The novel Orthogonal Structural Probe (Limisiewicz and Mare\v{c}ek, 2021) allows us to answer this question for specific linguistic features and learn a projection based only on mono-lingual annotated datasets. We evaluate syntactic (UD) and lexical (WordNet) structural information encoded inmBERT's contextual representations for nine diverse languages. We observe that for languages closely related to English, no transformation is needed. The evaluated information is encoded in a shared cross-lingual embedding space. For other languages, it is beneficial to apply orthogonal transformation learned separately for each language. We successfully apply our findings to zero-shot and few-shot cross-lingual parsing.
THEaiTRE 1.0: Interactive generation of theatre play scripts
Feb 17, 2021We present the first version of a system for interactive generation of theatre play scripts. The system is based on a vanilla GPT-2 model with several adjustments, targeting specific issues we encountered in practice. We also list other issues we encountered but plan to only solve in a future version of the system. The presented system was used to generate a theatre play script planned for premiere in February 2021.