 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Forget About Pronouns: Removing Gender Bias in Language Models Without Losing Factual Gender Information
Paper and Code
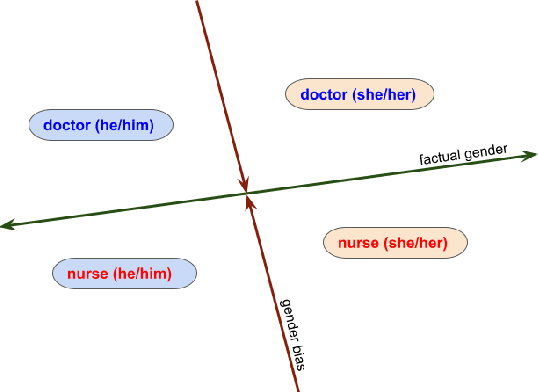

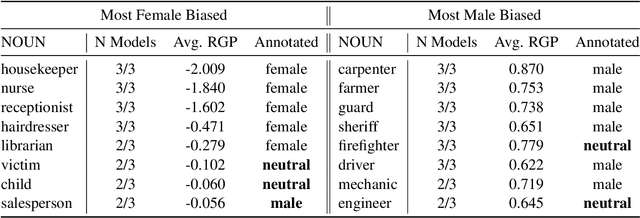

The representations in large language models contain multiple types of gender information. We focus on two types of such signals in English texts: factual gender information, which is a grammatical or semantic property, and gender bias, which is the correlation between a word and specific gender. We can disentangle the model's embeddings and identify components encoding both types of information with probing. We aim to diminish the stereotypical bias in the representations while preserving the factual gender signal. Our filtering method shows that it is possible to decrease the bias of gender-neutral profession names without significant deterioration of language modeling capabilities. The findings can be applied to language generation to mitigate reliance on stereotypes while preserving gender agreement in coreferences.