 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Debiasing: Remove Stereotypes and Keep Factual Gender for Fair Language Modeling and Translation
Jan 17, 2025Mitigation of biases, such as language models' reliance on gender stereotypes, is a crucial endeavor required for the creation of reliable and useful language technology. The crucial aspect of debiasing is to ensure that the models preserve their versatile capabilities, including their ability to solve language tasks and equitably represent various genders. To address this issue, we introduce a streamlined Dual Dabiasing Algorithm through Model Adaptation (2DAMA). Novel Dual Debiasing enables robust reduction of stereotypical bias while preserving desired factual gender information encoded by language models. We show that 2DAMA effectively reduces gender bias in English and is one of the first approaches facilitating the mitigation of stereotypical tendencies in translation. The proposed method's key advantage is the preservation of factual gender cues, which are useful in a wide range of natural language processing tasks.
Transforming Hidden States into Binary Semantic Features
Sep 29, 2024Large language models follow a lineage of many NLP applications that were directly inspired by distributional semantics, but do not seem to be closely related to it anymore. In this paper, we propose to employ the distributional theory of meaning once again. Using Independent Component Analysis to overcome some of its challenging aspects, we show that large language models represent semantic features in their hidden states.
Teaching LLMs at Charles University: Assignments and Activities
Jul 29, 2024This paper presents teaching materials, particularly assignments and ideas for classroom activities, from a new course on large language models (LLMs) taught at Charles University. The assignments include experiments with LLM inference for weather report generation and machine translation. The classroom activities include class quizzes, focused research on downstream tasks and datasets, and an interactive "best paper" session aimed at reading and comprehension of research papers.
Debiasing Algorithm through Model Adaptation
Oct 29, 2023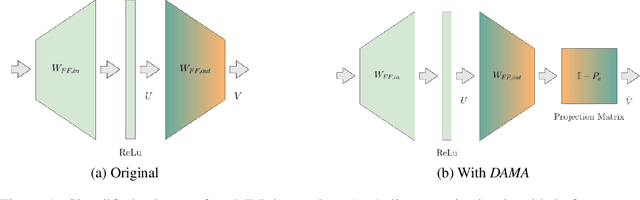
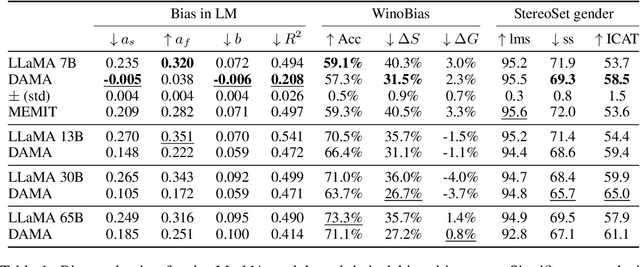
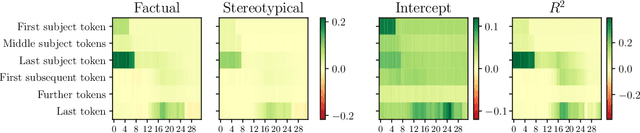
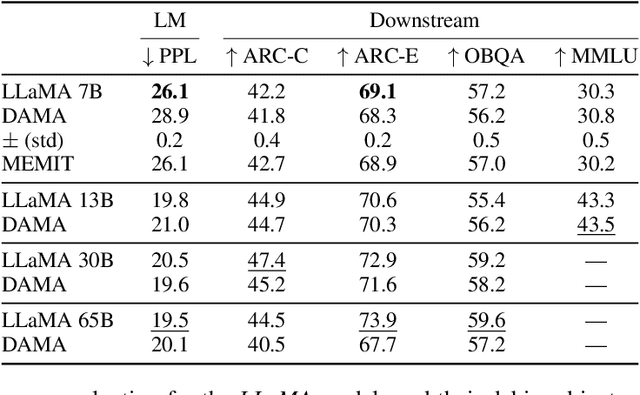
Large language models are becoming the go-to solution for various language tasks. However, with growing capacity, models are prone to rely on spurious correlations stemming from biases and stereotypes present in the training data. This work proposes a novel method for detecting and mitigating gender bias in language models. We perform causal analysis to identify problematic model components and discover that mid-upper feed-forward layers are most prone to convey biases. Based on the analysis results, we adapt the model by multiplying these layers by a linear projection. Our titular method, DAMA, significantly decreases bias as measured by diverse metrics while maintaining the model's performance on downstream tasks. We release code for our method and models, which retrain LLaMA's state-of-the-art performance while being significantly less biased.
SphereMap: Dynamic Multi-Layer Graph Structure for Rapid Safety-Aware UAV Planning
Feb 03, 2023



A flexible topological representation consisting of a two-layer graph structure built on-board an Unmanned Aerial Vehicle (UAV) by continuously filling the free space of an occupancy map with intersecting spheres is proposed in this \paper{}. Most state-of-the-art planning methods find the shortest paths while keeping the UAV at a pre-defined distance from obstacles. Planning over the proposed structure reaches this pre-defined distance only when necessary, maintaining a safer distance otherwise, while also being orders of magnitude faster than other state-of-the-art methods. Furthermore, we demonstrate how this graph representation can be converted into a lightweight shareable topological-volumetric map of the environment, which enables decentralized multi-robot cooperation. The proposed approach was successfully validated in several kilometers of real subterranean environments, such as caves, devastated industrial buildings, and in the harsh and complex setting of the final event of the DARPA SubT Challenge, which aims to mimic the conditions of real search and rescue missions as closely as possible, and where our approach achieved the \nth{2} place in the virtual track.
Independent Components of Word Embeddings Represent Semantic Features
Dec 19, 2022

Independent Component Analysis (ICA) is an algorithm originally developed for finding separate sources in a mixed signal, such as a recording of multiple people in the same room speaking at the same time. It has also been used to find linguistic features in distributional representations. In this paper, we used ICA to analyze words embeddings. We have found that ICA can be used to find semantic features of the words and these features can easily be combined to search for words that satisfy the combination. We show that only some of the independent components represent such features, but those that do are stable with regard to random initialization of the algorithm.
DialogueScript: Using Dialogue Agents to Produce a Script
Jun 16, 2022


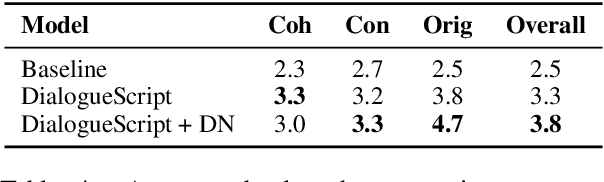
We present a novel approach to generating scripts by using agents with different personality types. To manage character interaction in the script, we employ simulated dramatic networks. Automatic and human evaluation on multiple criteria shows that our approach outperforms a vanilla-GPT2-based baseline. We further introduce a new metric to evaluate dialogue consistency based on natural language inference and demonstrate its validity.
THEaiTRE 1.0: Interactive generation of theatre play scripts
Feb 17, 2021We present the first version of a system for interactive generation of theatre play scripts. The system is based on a vanilla GPT-2 model with several adjustments, targeting specific issues we encountered in practice. We also list other issues we encountered but plan to only solve in a future version of the system. The presented system was used to generate a theatre play script planned for premiere in February 2021.
Measuring Memorization Effect in Word-Level Neural Networks Probing
Jun 29, 2020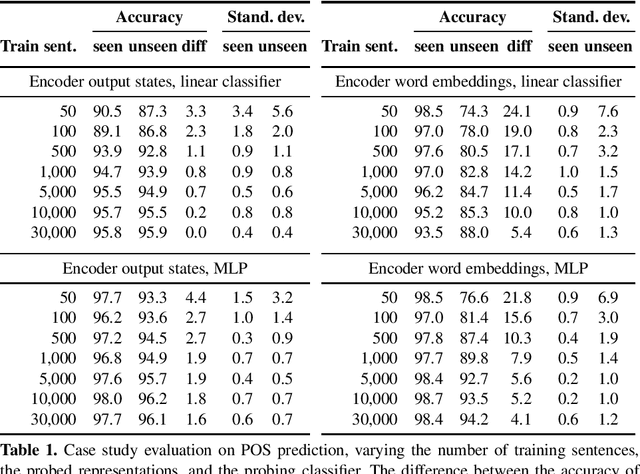
Multiple studies have probed representations emerging in neural networks trained for end-to-end NLP tasks and examined what word-level linguistic information may be encoded in the representations. In classical probing, a classifier is trained on the representations to extract the target linguistic information. However, there is a threat of the classifier simply memorizing the linguistic labels for individual words, instead of extracting the linguistic abstractions from the representations, thus reporting false positive results. While considerable efforts have been made to minimize the memorization problem, the task of actually measuring the amount of memorization happening in the classifier has been understudied so far. In our work, we propose a simple general method for measuring the memorization effect, based on a symmetric selection of comparable sets of test words seen versus unseen in training. Our method can be used to explicitly quantify the amount of memorization happening in a probing setup, so that an adequate setup can be chosen and the results of the probing can be interpreted with a reliability estimate. We exemplify this by showcasing our method on a case study of probing for part of speech in a trained neural machine translation encoder.
THEaiTRE: Artificial Intelligence to Write a Theatre Play
Jun 25, 2020We present THEaiTRE, a starting project aimed at automatic generation of theatre play scripts. This paper reviews related work and drafts an approach we intend to follow. We plan to adopt generative neural language models and hierarchical generation approaches, supported by summarization and machine translation methods, and complemented with a human-in-the-loop approach.