 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting LLMs: Length Control for Isometric Machine Translation
Jun 05, 2025



In this study, we explore the effectiveness of isometric machine translation across multiple language pairs (En$\to$De, En$\to$Fr, and En$\to$Es) under the conditions of the IWSLT Isometric Shared Task 2022. Using eight open-source large language models (LLMs) of varying sizes, we investigate how different prompting strategies, varying numbers of few-shot examples, and demonstration selection influence translation quality and length control. We discover that the phrasing of instructions, when aligned with the properties of the provided demonstrations, plays a crucial role in controlling the output length. Our experiments show that LLMs tend to produce shorter translations only when presented with extreme examples, while isometric demonstrations often lead to the models disregarding length constraints. While few-shot prompting generally enhances translation quality, further improvements are marginal across 5, 10, and 20-shot settings. Finally, considering multiple outputs allows to notably improve overall tradeoff between the length and quality, yielding state-of-the-art performance for some language pairs.
MockConf: A Student Interpretation Dataset: Analysis, Word- and Span-level Alignment and Baselines
Jun 05, 2025



In simultaneous interpreting, an interpreter renders a source speech into another language with a very short lag, much sooner than sentences are finished. In order to understand and later reproduce this dynamic and complex task automatically, we need dedicated datasets and tools for analysis, monitoring, and evaluation, such as parallel speech corpora, and tools for their automatic annotation. Existing parallel corpora of translated texts and associated alignment algorithms hardly fill this gap, as they fail to model long-range interactions between speech segments or specific types of divergences (e.g., shortening, simplification, functional generalization) between the original and interpreted speeches. In this work, we introduce MockConf, a student interpreting dataset that was collected from Mock Conferences run as part of the students' curriculum. This dataset contains 7 hours of recordings in 5 European languages, transcribed and aligned at the level of spans and words. We further implement and release InterAlign, a modern web-based annotation tool for parallel word and span annotations on long inputs, suitable for aligning simultaneous interpreting. We propose metrics for the evaluation and a baseline for automatic alignment. Dataset and tools are released to the community.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Jun 06, 2024
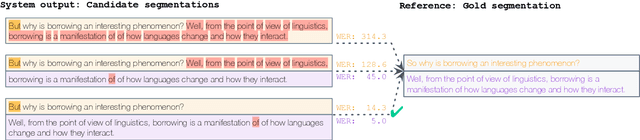

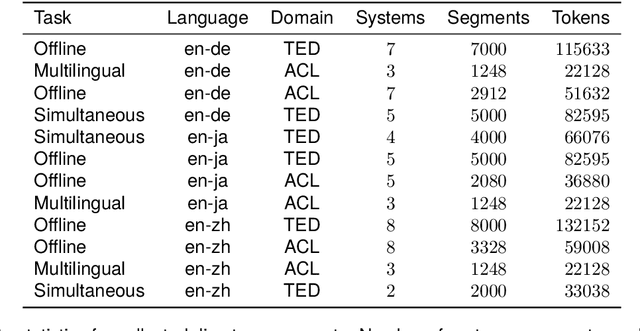
Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
* LREC-COLING2024 publication (with corrections for Table 3)
Assessing Word Importance Using Models Trained for Semantic Tasks
May 31, 2023



Many NLP tasks require to automatically identify the most significant words in a text. In this work, we derive word significance from models trained to solve semantic task: Natural Language Inference and Paraphrase Identification. Using an attribution method aimed to explain the predictions of these models, we derive importance scores for each input token. We evaluate their relevance using a so-called cross-task evaluation: Analyzing the performance of one model on an input masked according to the other model's weight, we show that our method is robust with respect to the choice of the initial task. Additionally, we investigate the scores from the syntax point of view and observe interesting patterns, e.g. words closer to the root of a syntactic tree receive higher importance scores. Altogether, these observations suggest that our method can be used to identify important words in sentences without any explicit word importance labeling in training.
DialogueScript: Using Dialogue Agents to Produce a Script
Jun 16, 2022


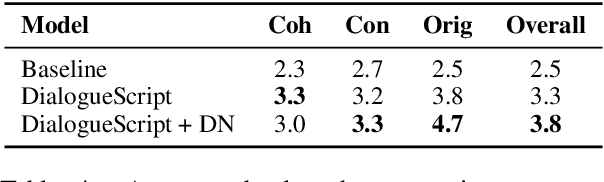
We present a novel approach to generating scripts by using agents with different personality types. To manage character interaction in the script, we employ simulated dramatic networks. Automatic and human evaluation on multiple criteria shows that our approach outperforms a vanilla-GPT2-based baseline. We further introduce a new metric to evaluate dialogue consistency based on natural language inference and demonstrate its validity.
Comprehension of Subtitles from Re-Translating Simultaneous Speech Translation
Mar 04, 2022

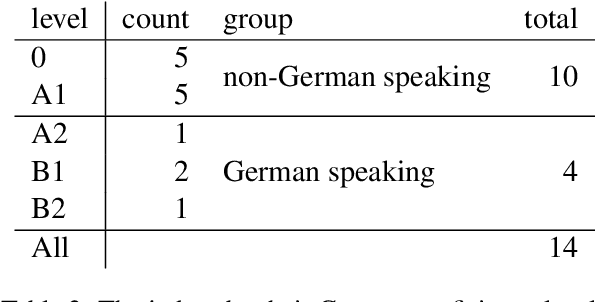
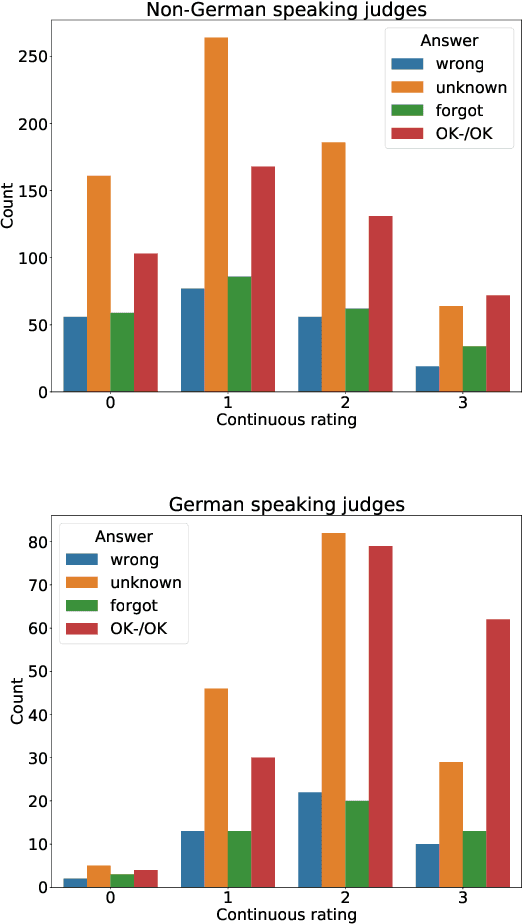
In simultaneous speech translation, one can vary the size of the output window, system latency and sometimes the allowed level of rewriting. The effect of these properties on readability and comprehensibility has not been tested with modern neural translation systems. In this work, we propose an evaluation method and investigate the effects on comprehension and user preferences. It is a pilot study with 14 users on 2 hours of German documentaries or speeches with online translations into Czech. We collect continuous feedback and answers on factual questions. Our results show that the subtitling layout or flicker have a little effect on comprehension, in contrast to machine translation itself and individual competence. Other results show that users with a limited knowledge of the source language have different preferences to stability and latency than the users with zero knowledge. The results are statistically insignificant, however, we show that our method works and can be reproduced in larger volume.