 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Paper and Code
Jun 06, 2024
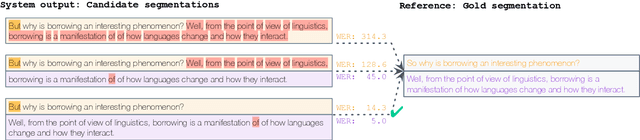

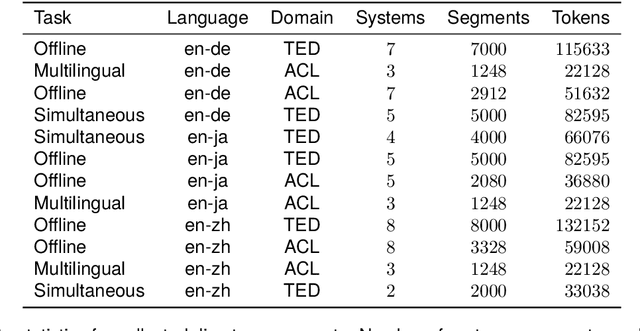
Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.