 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulstream: Open-Source Toolkit for Evaluation and Demonstration of Streaming Speech-to-Text Translation Systems
Dec 19, 2025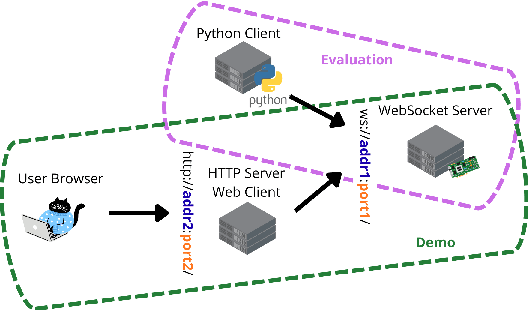
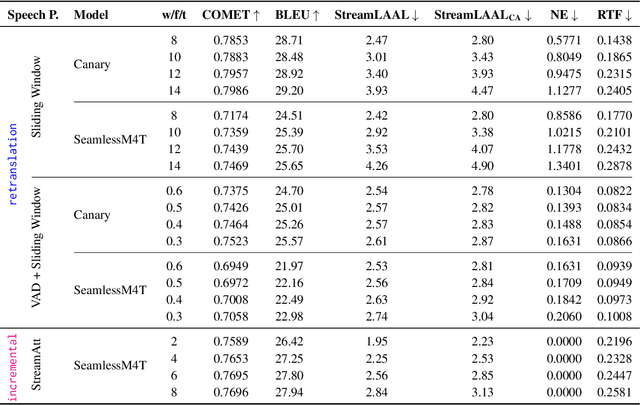
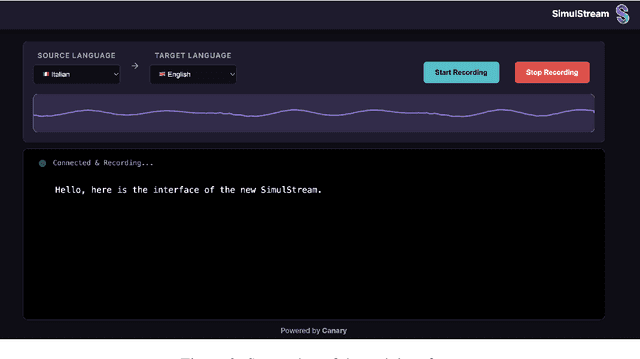
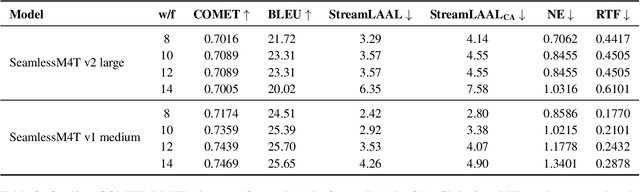
Streaming Speech-to-Text Translation (StreamST) requires producing translations concurrently with incoming speech, imposing strict latency constraints and demanding models that balance partial-information decision-making with high translation quality. Research efforts on the topic have so far relied on the SimulEval repository, which is no longer maintained and does not support systems that revise their outputs. In addition, it has been designed for simulating the processing of short segments, rather than long-form audio streams, and it does not provide an easy method to showcase systems in a demo. As a solution, we introduce simulstream, the first open-source framework dedicated to unified evaluation and demonstration of StreamST systems. Designed for long-form speech processing, it supports not only incremental decoding approaches, but also re-translation methods, enabling for their comparison within the same framework both in terms of quality and latency. In addition, it also offers an interactive web interface to demo any system built within the tool.
The Unheard Alternative: Contrastive Explanations for Speech-to-Text Models
Sep 30, 2025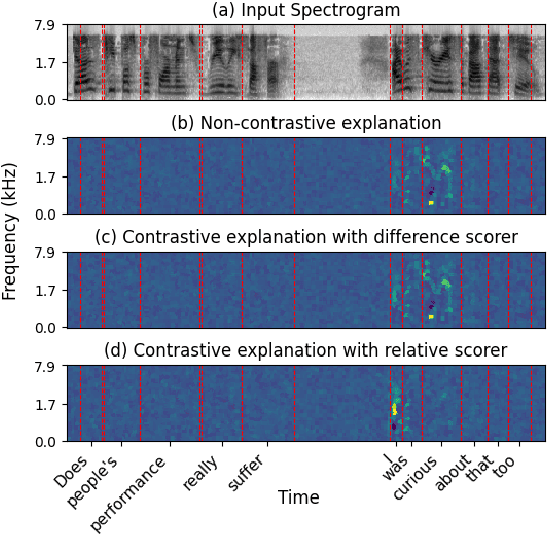
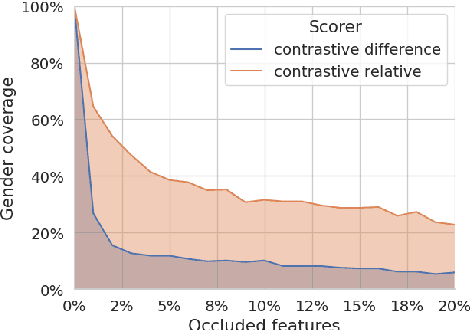

Contrastive explanations, which indicate why an AI system produced one output (the target) instead of another (the foil), are widely regarded in explainable AI as more informative and interpretable than standard explanations. However, obtaining such explanations for speech-to-text (S2T) generative models remains an open challenge. Drawing from feature attribution techniques, we propose the first method to obtain contrastive explanations in S2T by analyzing how parts of the input spectrogram influence the choice between alternative outputs. Through a case study on gender assignment in speech translation, we show that our method accurately identifies the audio features that drive the selection of one gender over another. By extending the scope of contrastive explanations to S2T, our work provides a foundation for better understanding S2T models.
The Warmup Dilemma: How Learning Rate Strategies Impact Speech-to-Text Model Convergence
May 29, 2025Training large-scale models presents challenges not only in terms of resource requirements but also in terms of their convergence. For this reason, the learning rate (LR) is often decreased when the size of a model is increased. Such a simple solution is not enough in the case of speech-to-text (S2T) trainings, where evolved and more complex variants of the Transformer architecture -- e.g., Conformer or Branchformer -- are used in light of their better performance. As a workaround, OWSM designed a double linear warmup of the LR, increasing it to a very small value in the first phase before updating it to a higher value in the second phase. While this solution worked well in practice, it was not compared with alternative solutions, nor was the impact on the final performance of different LR warmup schedules studied. This paper fills this gap, revealing that i) large-scale S2T trainings demand a sub-exponential LR warmup, and ii) a higher LR in the warmup phase accelerates initial convergence, but it does not boost final performance.
FAMA: The First Large-Scale Open-Science Speech Foundation Model for English and Italian
May 28, 2025The development of speech foundation models (SFMs) like Whisper and SeamlessM4T has significantly advanced the field of speech processing. However, their closed nature--with inaccessible training data and code--poses major reproducibility and fair evaluation challenges. While other domains have made substantial progress toward open science by developing fully transparent models trained on open-source (OS) code and data, similar efforts in speech remain limited. To fill this gap, we introduce FAMA, the first family of open science SFMs for English and Italian, trained on 150k+ hours of OS speech data. Moreover, we present a new dataset containing 16k hours of cleaned and pseudo-labeled speech for both languages. Results show that FAMA achieves competitive performance compared to existing SFMs while being up to 8 times faster. All artifacts, including code, datasets, and models, are released under OS-compliant licenses, promoting openness in speech technology research.
Memorization to Generalization: Emergence of Diffusion Models from Associative Memory
May 27, 2025



Hopfield networks are associative memory (AM) systems, designed for storing and retrieving patterns as local minima of an energy landscape. In the classical Hopfield model, an interesting phenomenon occurs when the amount of training data reaches its critical memory load $- spurious\,\,states$, or unintended stable points, emerge at the end of the retrieval dynamics, leading to incorrect recall. In this work, we examine diffusion models, commonly used in generative modeling, from the perspective of AMs. The training phase of diffusion model is conceptualized as memory encoding (training data is stored in the memory). The generation phase is viewed as an attempt of memory retrieval. In the small data regime the diffusion model exhibits a strong memorization phase, where the network creates distinct basins of attraction around each sample in the training set, akin to the Hopfield model below the critical memory load. In the large data regime, a different phase appears where an increase in the size of the training set fosters the creation of new attractor states that correspond to manifolds of the generated samples. Spurious states appear at the boundary of this transition and correspond to emergent attractor states, which are absent in the training set, but, at the same time, have distinct basins of attraction around them. Our findings provide: a novel perspective on the memorization-generalization phenomenon in diffusion models via the lens of AMs, theoretical prediction of existence of spurious states, empirical validation of this prediction in commonly-used diffusion models.
Implicit bias produces neural scaling laws in learning curves, from perceptrons to deep networks
May 19, 2025Scaling laws in deep learning - empirical power-law relationships linking model performance to resource growth - have emerged as simple yet striking regularities across architectures, datasets, and tasks. These laws are particularly impactful in guiding the design of state-of-the-art models, since they quantify the benefits of increasing data or model size, and hint at the foundations of interpretability in machine learning. However, most studies focus on asymptotic behavior at the end of training or on the optimal training time given the model size. In this work, we uncover a richer picture by analyzing the entire training dynamics through the lens of spectral complexity norms. We identify two novel dynamical scaling laws that govern how performance evolves during training. These laws together recover the well-known test error scaling at convergence, offering a mechanistic explanation of generalization emergence. Our findings are consistent across CNNs, ResNets, and Vision Transformers trained on MNIST, CIFAR-10 and CIFAR-100. Furthermore, we provide analytical support using a solvable model: a single-layer perceptron trained with binary cross-entropy. In this setting, we show that the growth of spectral complexity driven by the implicit bias mirrors the generalization behavior observed at fixed norm, allowing us to connect the performance dynamics to classical learning rules in the perceptron.
An LLM-as-a-judge Approach for Scalable Gender-Neutral Translation Evaluation
Apr 16, 2025Gender-neutral translation (GNT) aims to avoid expressing the gender of human referents when the source text lacks explicit cues about the gender of those referents. Evaluating GNT automatically is particularly challenging, with current solutions being limited to monolingual classifiers. Such solutions are not ideal because they do not factor in the source sentence and require dedicated data and fine-tuning to scale to new languages. In this work, we address such limitations by investigating the use of large language models (LLMs) as evaluators of GNT. Specifically, we explore two prompting approaches: one in which LLMs generate sentence-level assessments only, and another, akin to a chain-of-thought approach, where they first produce detailed phrase-level annotations before a sentence-level judgment. Through extensive experiments on multiple languages with five models, both open and proprietary, we show that LLMs can serve as evaluators of GNT. Moreover, we find that prompting for phrase-level annotations before sentence-level assessments consistently improves the accuracy of all models, providing a better and more scalable alternative to current solutions.
Translation in the Hands of Many:Centering Lay Users in Machine Translation Interactions
Feb 19, 2025Converging societal and technical factors have transformed language technologies into user-facing applications employed across languages. Machine Translation (MT) has become a global tool, with cross-lingual services now also supported by dialogue systems powered by multilingual Large Language Models (LLMs). This accessibility has expanded MT's reach to a vast base of lay users, often with little to no expertise in the languages or the technology itself. Despite this, the understanding of MT consumed by this diverse group of users -- their needs, experiences, and interactions with these systems -- remains limited. This paper traces the shift in MT user profiles, focusing on non-expert users and how their engagement with these systems may change with LLMs. We identify three key factors -- usability, trust, and literacy -- that shape these interactions and must be addressed to align MT with user needs. By exploring these dimensions, we offer insights to guide future MT with a user-centered approach.
GFG -- Gender-Fair Generation: A CALAMITA Challenge
Dec 26, 2024Gender-fair language aims at promoting gender equality by using terms and expressions that include all identities and avoid reinforcing gender stereotypes. Implementing gender-fair strategies is particularly challenging in heavily gender-marked languages, such as Italian. To address this, the Gender-Fair Generation challenge intends to help shift toward gender-fair language in written communication. The challenge, designed to assess and monitor the recognition and generation of gender-fair language in both mono- and cross-lingual scenarios, includes three tasks: (1) the detection of gendered expressions in Italian sentences, (2) the reformulation of gendered expressions into gender-fair alternatives, and (3) the generation of gender-fair language in automatic translation from English to Italian. The challenge relies on three different annotated datasets: the GFL-it corpus, which contains Italian texts extracted from administrative documents provided by the University of Brescia; GeNTE, a bilingual test set for gender-neutral rewriting and translation built upon a subset of the Europarl dataset; and Neo-GATE, a bilingual test set designed to assess the use of non-binary neomorphemes in Italian for both fair formulation and translation tasks. Finally, each task is evaluated with specific metrics: average of F1-score obtained by means of BERTScore computed on each entry of the datasets for task 1, an accuracy measured with a gender-neutral classifier, and a coverage-weighted accuracy for tasks 2 and 3.
Speech Foundation Models and Crowdsourcing for Efficient, High-Quality Data Collection
Dec 16, 2024


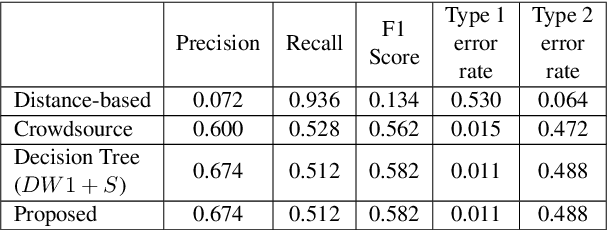
While crowdsourcing is an established solution for facilitating and scaling the collection of speech data, the involvement of non-experts necessitates protocols to ensure final data quality. To reduce the costs of these essential controls, this paper investigates the use of Speech Foundation Models (SFMs) to automate the validation process, examining for the first time the cost/quality trade-off in data acquisition. Experiments conducted on French, German, and Korean data demonstrate that SFM-based validation has the potential to reduce reliance on human validation, resulting in an estimated cost saving of over 40.0% without degrading final data quality. These findings open new opportunities for more efficient, cost-effective, and scalable speech data acquisition.