 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechMapper: Speech-to-text Embedding Projector for LLMs
Jan 28, 2026Current speech LLMs bridge speech foundation models to LLMs using projection layers, training all of these components on speech instruction data. This strategy is computationally intensive and susceptible to task and prompt overfitting. We present SpeechMapper, a cost-efficient speech-to-LLM-embedding training approach that mitigates overfitting, enabling more robust and generalizable models. Our model is first pretrained without the LLM on inexpensive hardware, and then efficiently attached to the target LLM via a brief 1K-step instruction tuning (IT) stage. Through experiments on speech translation and spoken question answering, we demonstrate the versatility of SpeechMapper's pretrained block, presenting results for both task-agnostic IT, an ASR-based adaptation strategy that does not train in the target task, and task-specific IT. In task-agnostic settings, Speechmapper rivals the best instruction-following speech LLM from IWSLT25, despite never being trained on these tasks, while in task-specific settings, it outperforms this model across many datasets, despite requiring less data and compute. Overall, SpeechMapper offers a practical and scalable approach for efficient, generalizable speech-LLM integration without large-scale IT.
Speech Foundation Models and Crowdsourcing for Efficient, High-Quality Data Collection
Dec 16, 2024


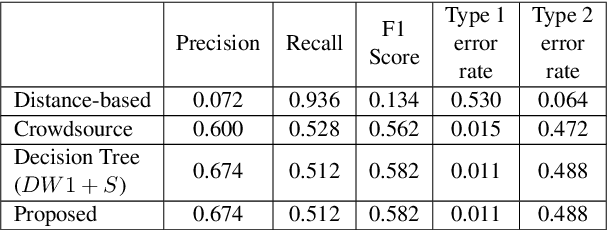
While crowdsourcing is an established solution for facilitating and scaling the collection of speech data, the involvement of non-experts necessitates protocols to ensure final data quality. To reduce the costs of these essential controls, this paper investigates the use of Speech Foundation Models (SFMs) to automate the validation process, examining for the first time the cost/quality trade-off in data acquisition. Experiments conducted on French, German, and Korean data demonstrate that SFM-based validation has the potential to reduce reliance on human validation, resulting in an estimated cost saving of over 40.0% without degrading final data quality. These findings open new opportunities for more efficient, cost-effective, and scalable speech data acquisition.
Speech-MASSIVE: A Multilingual Speech Dataset for SLU and Beyond
Aug 07, 2024



We present Speech-MASSIVE, a multilingual Spoken Language Understanding (SLU) dataset comprising the speech counterpart for a portion of the MASSIVE textual corpus. Speech-MASSIVE covers 12 languages from different families and inherits from MASSIVE the annotations for the intent prediction and slot-filling tasks. Our extension is prompted by the scarcity of massively multilingual SLU datasets and the growing need for versatile speech datasets to assess foundation models (LLMs, speech encoders) across languages and tasks. We provide a multimodal, multitask, multilingual dataset and report SLU baselines using both cascaded and end-to-end architectures in various training scenarios (zero-shot, few-shot, and full fine-tune). Furthermore, we demonstrate the suitability of Speech-MASSIVE for benchmarking other tasks such as speech transcription, language identification, and speech translation. The dataset, models, and code are publicly available at: https://github.com/hlt-mt/Speech-MASSIVE
An Adapter-Based Unified Model for Multiple Spoken Language Processing Tasks
Jun 20, 2024Self-supervised learning models have revolutionized the field of speech processing. However, the process of fine-tuning these models on downstream tasks requires substantial computational resources, particularly when dealing with multiple speech-processing tasks. In this paper, we explore the potential of adapter-based fine-tuning in developing a unified model capable of effectively handling multiple spoken language processing tasks. The tasks we investigate are Automatic Speech Recognition, Phoneme Recognition, Intent Classification, Slot Filling, and Spoken Emotion Recognition. We validate our approach through a series of experiments on the SUPERB benchmark, and our results indicate that adapter-based fine-tuning enables a single encoder-decoder model to perform multiple speech processing tasks with an average improvement of 18.4% across the five target tasks while staying efficient in terms of parameter updates.
mHuBERT-147: A Compact Multilingual HuBERT Model
Jun 11, 2024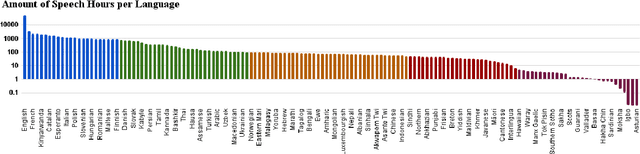
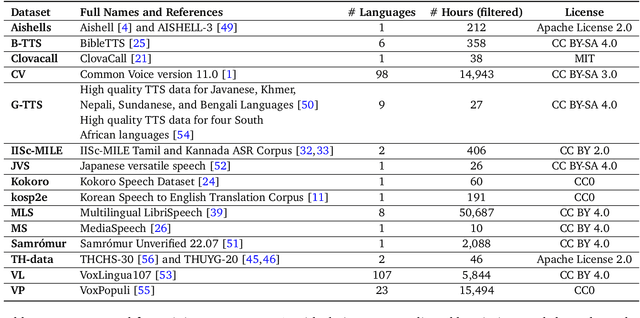
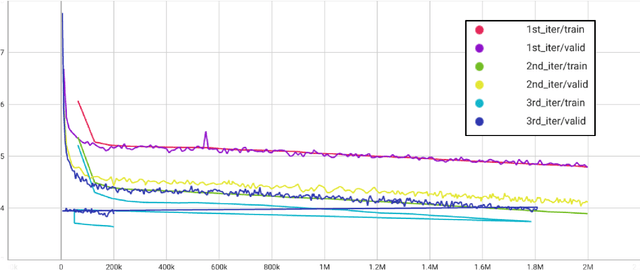
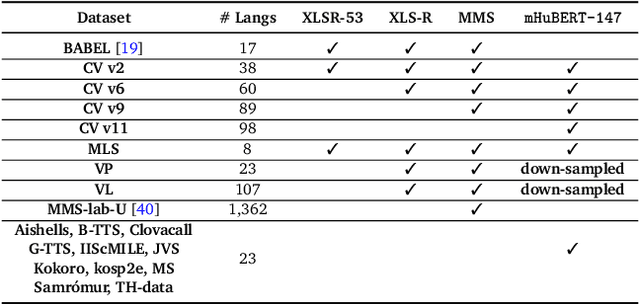
We present mHuBERT-147, the first general-purpose massively multilingual HuBERT speech representation model trained on 90K hours of clean, open-license data. To scale up the multi-iteration HuBERT approach, we use faiss-based clustering, achieving 5.2x faster label assignment than the original method. We also apply a new multilingual batching up-sampling strategy, leveraging both language and dataset diversity. After 3 training iterations, our compact 95M parameter mHuBERT-147 outperforms larger models trained on substantially more data. We rank second and first on the ML-SUPERB 10min and 1h leaderboards, with SOTA scores for 3 tasks. Across ASR/LID tasks, our model consistently surpasses XLS-R (300M params; 436K hours) and demonstrates strong competitiveness against the much larger MMS (1B params; 491K hours). Our findings indicate that mHuBERT-147 is a promising model for multilingual speech tasks, offering an unprecedented balance between high performance and parameter efficiency.
NAVER LABS Europe's Multilingual Speech Translation Systems for the IWSLT 2023 Low-Resource Track
Jun 13, 2023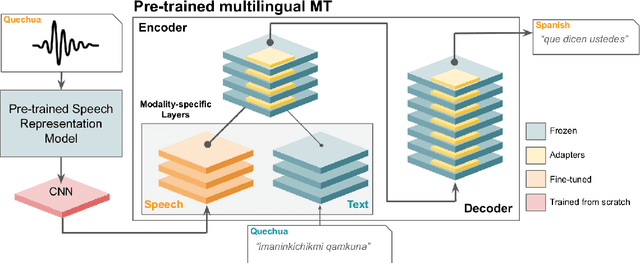
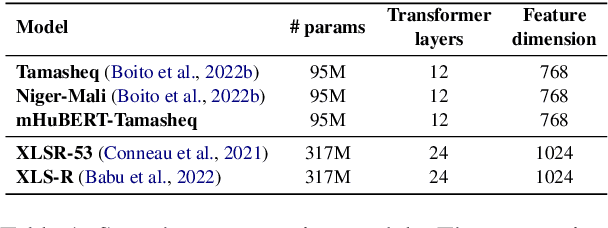
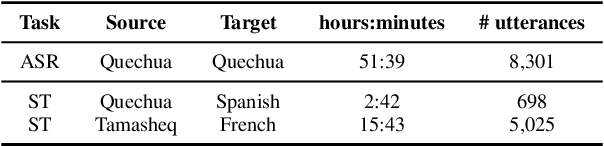
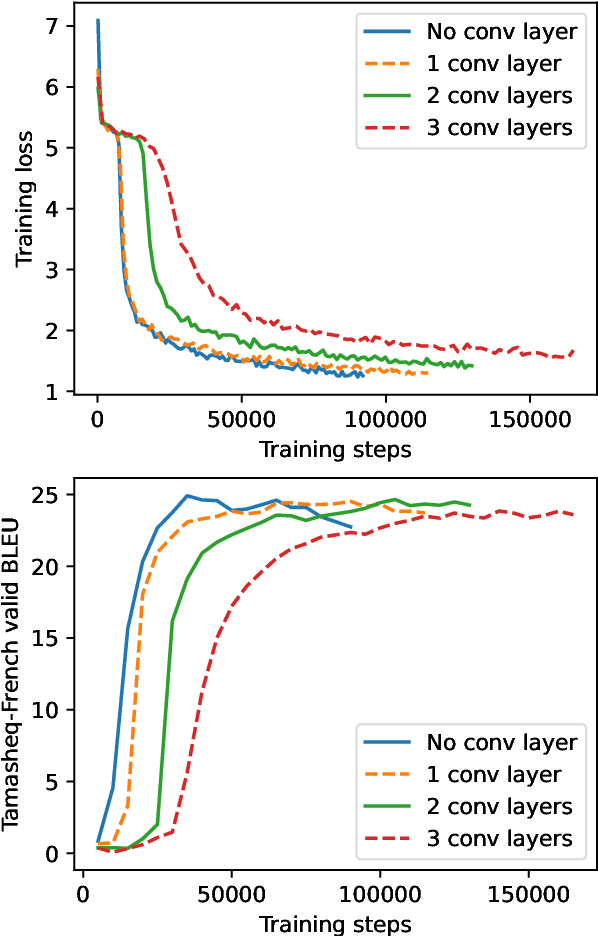
This paper presents NAVER LABS Europe's systems for Tamasheq-French and Quechua-Spanish speech translation in the IWSLT 2023 Low-Resource track. Our work attempts to maximize translation quality in low-resource settings using multilingual parameter-efficient solutions that leverage strong pre-trained models. Our primary submission for Tamasheq outperforms the previous state of the art by 7.5 BLEU points on the IWSLT 2022 test set, and achieves 23.6 BLEU on this year's test set, outperforming the second best participant by 7.7 points. For Quechua, we also rank first and achieve 17.7 BLEU, despite having only two hours of translation data. Finally, we show that our proposed multilingual architecture is also competitive for high-resource languages, outperforming the best unconstrained submission to the IWSLT 2021 Multilingual track, despite using much less training data and compute.
DaLC: Domain Adaptation Learning Curve Prediction for Neural Machine Translation
Apr 20, 2022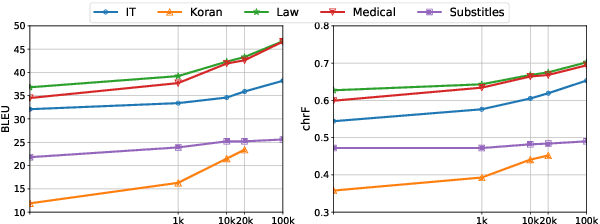



Domain Adaptation (DA) of Neural Machine Translation (NMT) model often relies on a pre-trained general NMT model which is adapted to the new domain on a sample of in-domain parallel data. Without parallel data, there is no way to estimate the potential benefit of DA, nor the amount of parallel samples it would require. It is however a desirable functionality that could help MT practitioners to make an informed decision before investing resources in dataset creation. We propose a Domain adaptation Learning Curve prediction (DaLC) model that predicts prospective DA performance based on in-domain monolingual samples in the source language. Our model relies on the NMT encoder representations combined with various instance and corpus-level features. We demonstrate that instance-level is better able to distinguish between different domains compared to corpus-level frameworks proposed in previous studies. Finally, we perform in-depth analyses of the results highlighting the limitations of our approach, and provide directions for future research.
Machine Translation of Restaurant Reviews: New Corpus for Domain Adaptation and Robustness
Oct 31, 2019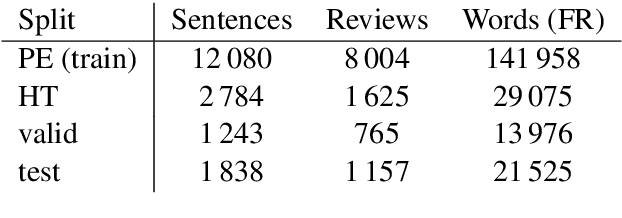


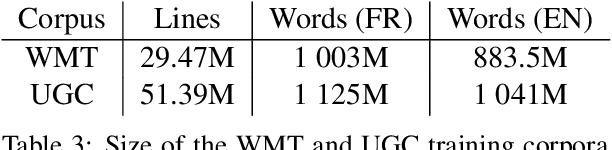
We share a French-English parallel corpus of Foursquare restaurant reviews (https://europe.naverlabs.com/research/natural-language-processing/machine-translation-of-restaurant-reviews), and define a new task to encourage research on Neural Machine Translation robustness and domain adaptation, in a real-world scenario where better-quality MT would be greatly beneficial. We discuss the challenges of such user-generated content, and train good baseline models that build upon the latest techniques for MT robustness. We also perform an extensive evaluation (automatic and human) that shows significant improvements over existing online systems. Finally, we propose task-specific metrics based on sentiment analysis or translation accuracy of domain-specific polysemous words.
Naver Labs Europe's Systems for the Document-Level Generation and Translation Task at WNGT 2019
Oct 31, 2019
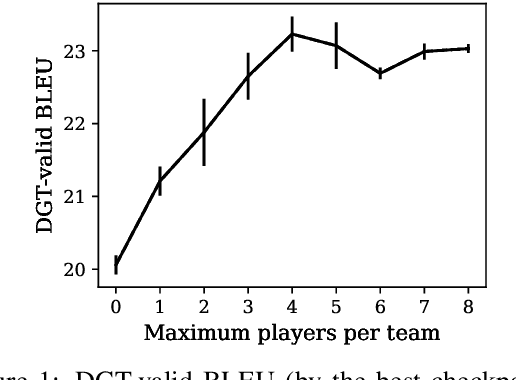

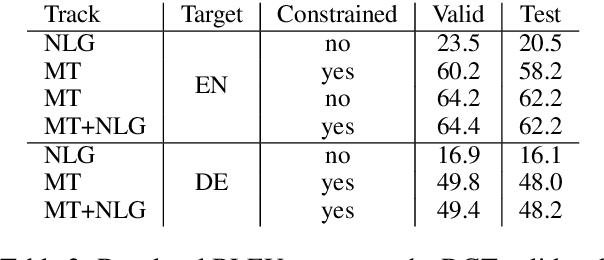
Recently, neural models led to significant improvements in both machine translation (MT) and natural language generation tasks (NLG). However, generation of long descriptive summaries conditioned on structured data remains an open challenge. Likewise, MT that goes beyond sentence-level context is still an open issue (e.g., document-level MT or MT with metadata). To address these challenges, we propose to leverage data from both tasks and do transfer learning between MT, NLG, and MT with source-side metadata (MT+NLG). First, we train document-based MT systems with large amounts of parallel data. Then, we adapt these models to pure NLG and MT+NLG tasks by fine-tuning with smaller amounts of domain-specific data. This end-to-end NLG approach, without data selection and planning, outperforms the previous state of the art on the Rotowire NLG task. We participated to the "Document Generation and Translation" task at WNGT 2019, and ranked first in all tracks.
Naver Labs Europe's Systems for the WMT19 Machine Translation Robustness Task
Jul 15, 2019
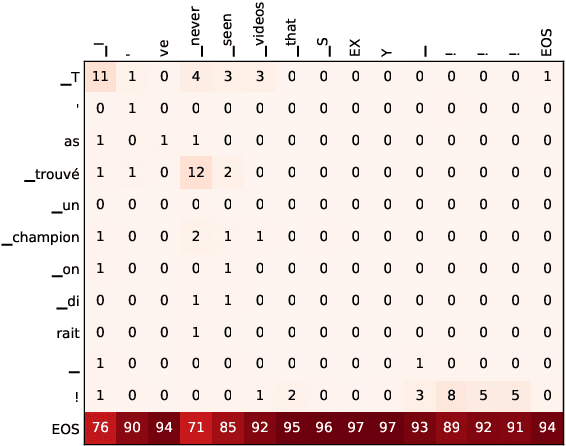
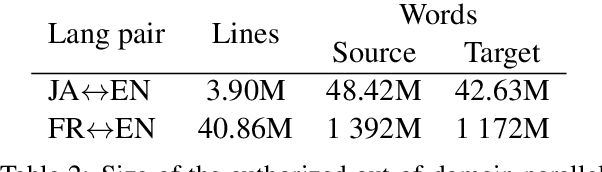
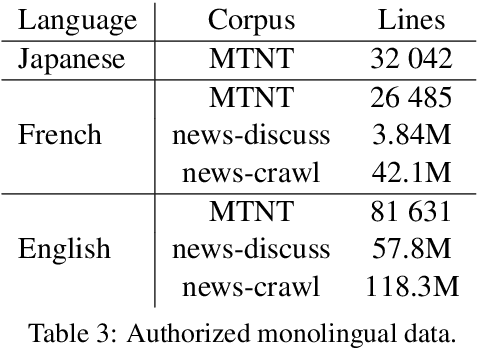
This paper describes the systems that we submitted to the WMT19 Machine Translation robustness task. This task aims to improve MT's robustness to noise found on social media, like informal language, spelling mistakes and other orthographic variations. The organizers provide parallel data extracted from a social media website in two language pairs: French-English and Japanese-English (in both translation directions). The goal is to obtain the best scores on unseen test sets from the same source, according to automatic metrics (BLEU) and human evaluation. We proposed one single and one ensemble system for each translation direction. Our ensemble models ranked first in all language pairs, according to BLEU evaluation. We discuss the pre-processing choices that we made, and present our solutions for robustness to noise and domain adaptation.