 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARG, Language-based Automatic Reward and Goal Generation
Jun 19, 2023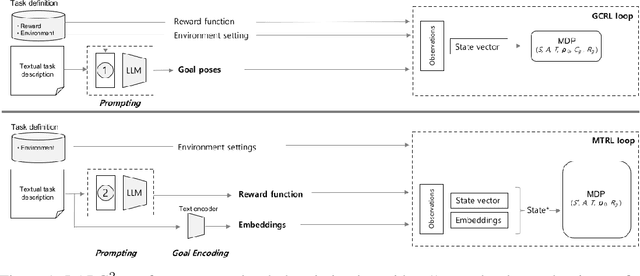


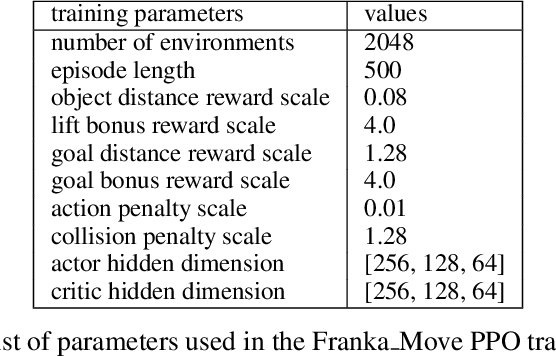
Goal-conditioned and Multi-Task Reinforcement Learning (GCRL and MTRL) address numerous problems related to robot learning, including locomotion, navigation, and manipulation scenarios. Recent works focusing on language-defined robotic manipulation tasks have led to the tedious production of massive human annotations to create dataset of textual descriptions associated with trajectories. To leverage reinforcement learning with text-based task descriptions, we need to produce reward functions associated with individual tasks in a scalable manner. In this paper, we leverage recent capabilities of Large Language Models (LLMs) and introduce \larg, Language-based Automatic Reward and Goal Generation, an approach that converts a text-based task description into its corresponding reward and goal-generation functions We evaluate our approach for robotic manipulation and demonstrate its ability to train and execute policies in a scalable manner, without the need for handcrafted reward functions.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Machine Translation of Restaurant Reviews: New Corpus for Domain Adaptation and Robustness
Oct 31, 2019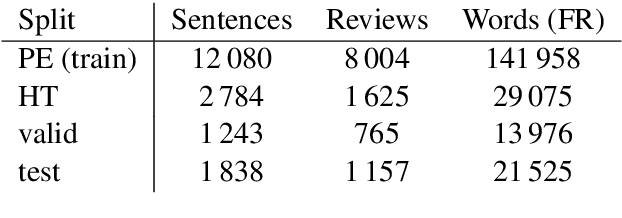


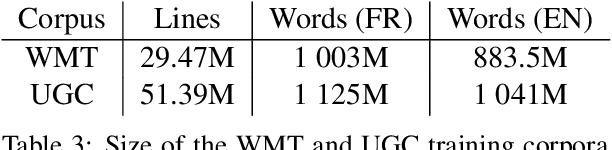
We share a French-English parallel corpus of Foursquare restaurant reviews (https://europe.naverlabs.com/research/natural-language-processing/machine-translation-of-restaurant-reviews), and define a new task to encourage research on Neural Machine Translation robustness and domain adaptation, in a real-world scenario where better-quality MT would be greatly beneficial. We discuss the challenges of such user-generated content, and train good baseline models that build upon the latest techniques for MT robustness. We also perform an extensive evaluation (automatic and human) that shows significant improvements over existing online systems. Finally, we propose task-specific metrics based on sentiment analysis or translation accuracy of domain-specific polysemous words.
Naver Labs Europe's Systems for the WMT19 Machine Translation Robustness Task
Jul 15, 2019
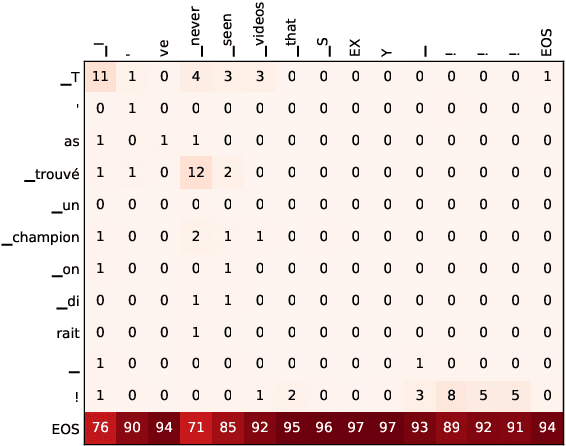
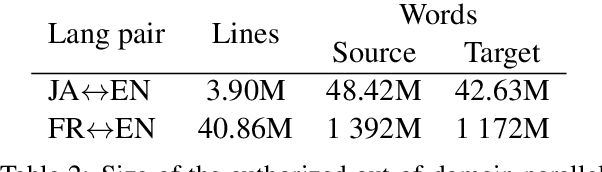
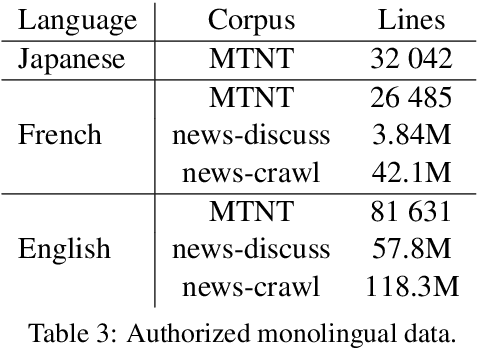
This paper describes the systems that we submitted to the WMT19 Machine Translation robustness task. This task aims to improve MT's robustness to noise found on social media, like informal language, spelling mistakes and other orthographic variations. The organizers provide parallel data extracted from a social media website in two language pairs: French-English and Japanese-English (in both translation directions). The goal is to obtain the best scores on unseen test sets from the same source, according to automatic metrics (BLEU) and human evaluation. We proposed one single and one ensemble system for each translation direction. Our ensemble models ranked first in all language pairs, according to BLEU evaluation. We discuss the pre-processing choices that we made, and present our solutions for robustness to noise and domain adaptation.