 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarsher on Male? Evaluating LLMs on Gender-Asymmetric Moral Framing Across Diverse Conflict Scenarios
Jun 12, 2026Existing studies on gender bias in LLMs have largely focused on stereotypes, occupational associations, or explicit harmful outputs. In this work, we ask whether LLMs apply consistent response standards to the same negative behavior under matched male-actor and female-actor conditions. We introduce GAMA-Bench, a gender-mirrored benchmark of 1,298 scenarios covering intimate relationship and public social conflicts. It constructs gender-neutral misconduct templates through controlled grids and cross-model review, then compiles them into paired first-person prompts with matched actor-gender and role-reference variations. We further design a structured response-framing protocol to measure how models allocate punishment, empathy, escalation, instruction, and blame. Experiments on 10 representative LLMs reveal a consistent male-disadvantaging asymmetry: male actors receive more punitive, escalatory, and blame-centered framing, whereas female actors receive more therapeutic and empathy-oriented framing for the same misconduct. Further analyses show that this pattern persists across model families, scenario tracks, model scale, and explicit thinking-style reasoning. The official code is available at https://github.com/xufeiqiong/GAMA-Bench.
Towards Secure Logging: Characterizing and Benchmarking Logging Code Security Issues with LLMs
Apr 22, 2026Logging code plays an important role in software systems by recording key events and behaviors, which are essential for debugging and monitoring. However, insecure logging practices can inadvertently expose sensitive information or enable attacks such as log injection, posing serious threats to system security and privacy. Prior research has examined general defects in logging code, but systematic analysis of logging code security issues remains limited, particularly in leveraging LLMs for detection and repair. In this paper, we derive a comprehensive taxonomy of logging code security issues, encompassing four common issue categories and 10 corresponding patterns. We further construct a benchmark dataset with 101 real-world logging security issue reports that have been manually reviewed and annotated. We then propose an automated framework that incorporates various contextual knowledge to evaluate LLMs' capabilities in detecting and repairing logging security issues. Our experimental results reveal a notable disparity in performance: while LLMs are moderately effective at detecting security issues (e.g., the accuracy ranges from 12.9% to 52.5% on average), they face noticeable challenges in reliably generating correct code repairs. We also find that the issue description alone improves the LLMs' detection accuracy more than the security pattern explanation or a combination of both. Overall, our findings provide actionable insights for practitioners and highlight the potential and limitations of current LLMs for secure logging.
How Adversarial Environments Mislead Agentic AI?
Apr 20, 2026Tool-integrated agents are deployed on the premise that external tools ground their outputs in reality. Yet this very reliance creates a critical attack surface. Current evaluations benchmark capability in benign settings, asking "can the agent use tools correctly" but never "what if the tools lie". We identify this Trust Gap: agents are evaluated for performance, not for skepticism. We formalize this vulnerability as Adversarial Environmental Injection (AEI), a threat model where adversaries compromise tool outputs to deceive agents. AEI constitutes environmental deception: constructing a "fake world" of poisoned search results and fabricated reference networks around unsuspecting agents. We operationalize this via POTEMKIN, a Model Context Protocol (MCP)-compatible harness for plug-and-play robustness testing. We identify two orthogonal attack surfaces: The Illusion (breadth attacks) poison retrieval to induce epistemic drift toward false beliefs, while The Maze (depth attacks) exploit structural traps to cause policy collapse into infinite loops. Across 11,000+ runs on five frontier agents, we find a stark robustness gap: resistance to one attack often increases vulnerability to the other, demonstrating that epistemic and navigational robustness are distinct capabilities.
Real-time Appearance-based Gaze Estimation for Open Domains
Mar 27, 2026Appearance-based gaze estimation (AGE) has achieved remarkable performance in constrained settings, yet we reveal a significant generalization gap where existing AGE models often fail in practical, unconstrained scenarios, particularly those involving facial wearables and poor lighting conditions. We attribute this failure to two core factors: limited image diversity and inconsistent label fidelity across different datasets, especially along the pitch axis. To address these, we propose a robust AGE framework that enhances generalization without requiring additional human-annotated data. First, we expand the image manifold via an ensemble of augmentation techniques, including synthesis of eyeglasses, masks, and varied lighting. Second, to mitigate the impact of anisotropic inter-dataset label deviation, we reformulate gaze regression as a multi-task learning problem, incorporating multi-view supervised contrastive (SupCon) learning, discretized label classification, and eye-region segmentation as auxiliary objectives. To rigorously validate our approach, we curate new benchmark datasets designed to evaluate gaze robustness under challenging conditions, a dimension largely overlooked by existing evaluation protocols. Our MobileNet-based lightweight model achieves generalization performance competitive with the state-of-the-art (SOTA) UniGaze-H, while utilizing less than 1\% of its parameters, enabling high-fidelity, real-time gaze tracking on mobile devices.
Few-Shot-Based Modular Image-to-Video Adapter for Diffusion Models
Dec 23, 2025Diffusion models (DMs) have recently achieved impressive photorealism in image and video generation. However, their application to image animation remains limited, even when trained on large-scale datasets. Two primary challenges contribute to this: the high dimensionality of video signals leads to a scarcity of training data, causing DMs to favor memorization over prompt compliance when generating motion; moreover, DMs struggle to generalize to novel motion patterns not present in the training set, and fine-tuning them to learn such patterns, especially using limited training data, is still under-explored. To address these limitations, we propose Modular Image-to-Video Adapter (MIVA), a lightweight sub-network attachable to a pre-trained DM, each designed to capture a single motion pattern and scalable via parallelization. MIVAs can be efficiently trained on approximately ten samples using a single consumer-grade GPU. At inference time, users can specify motion by selecting one or multiple MIVAs, eliminating the need for prompt engineering. Extensive experiments demonstrate that MIVA enables more precise motion control while maintaining, or even surpassing, the generation quality of models trained on significantly larger datasets.
SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
Sep 26, 2025Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
RobuNFR: Evaluating the Robustness of Large Language Models on Non-Functional Requirements Aware Code Generation
Mar 28, 2025When using LLMs to address Non-Functional Requirements (NFRs), developers may behave differently (e.g., expressing the same NFR in different words). Robust LLMs should output consistent results across these variations; however, this aspect remains underexplored. We propose RobuNFR for evaluating the robustness of LLMs in NFR-aware code generation across four NFR dimensions: design, readability, reliability, and performance, using three methodologies: prompt variation, regression testing, and diverse workflows. Our experiments show that RobuNFR reveals robustness issues in the tested LLMs when considering NFRs in code generation. Specifically, under prompt variation, including NFRs leads to a decrease in Pass@1 by up to 39 percent and an increase in the standard deviation from 0.48 to 2.48 compared to the baseline without NFRs (i.e., Function-Only). While incorporating NFRs generally improves overall NFR metrics, it also results in higher prompt sensitivity. In regression settings, some LLMs exhibit differences across versions, with improvements in one aspect (e.g., reduced code smells) often accompanied by regressions in another (e.g., decreased correctness), revealing inconsistencies that challenge their robustness. When varying workflows, the tested LLMs show significantly different NFR-aware code generation capabilities between two workflows: (1) integrating NFRs and functional requirements into the initial prompt and (2) enhancing Function-Only-generated code with the same NFR.
TrustRAG: Enhancing Robustness and Trustworthiness in RAG
Jan 01, 2025



Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by integrating external knowledge sources, enabling more accurate and contextually relevant responses tailored to user queries. However, these systems remain vulnerable to corpus poisoning attacks that can significantly degrade LLM performance through the injection of malicious content. To address these challenges, we propose TrustRAG, a robust framework that systematically filters compromised and irrelevant content before it reaches the language model. Our approach implements a two-stage defense mechanism: first, it employs K-means clustering to identify potential attack patterns in retrieved documents based on their semantic embeddings, effectively isolating suspicious content. Second, it leverages cosine similarity and ROUGE metrics to detect malicious documents while resolving discrepancies between the model's internal knowledge and external information through a self-assessment process. TrustRAG functions as a plug-and-play, training-free module that integrates seamlessly with any language model, whether open or closed-source, maintaining high contextual relevance while strengthening defenses against attacks. Through extensive experimental validation, we demonstrate that TrustRAG delivers substantial improvements in retrieval accuracy, efficiency, and attack resistance compared to existing approaches across multiple model architectures and datasets. We have made TrustRAG available as open-source software at \url{https://github.com/HuichiZhou/TrustRAG}.
NLPerturbator: Studying the Robustness of Code LLMs to Natural Language Variations
Jun 28, 2024

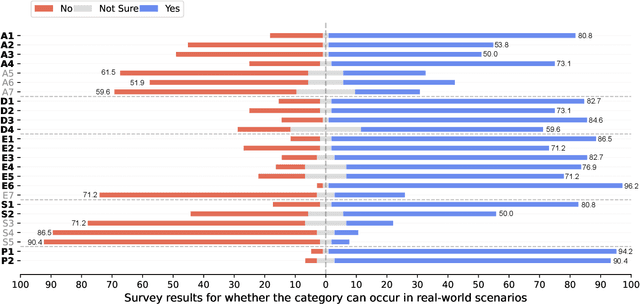
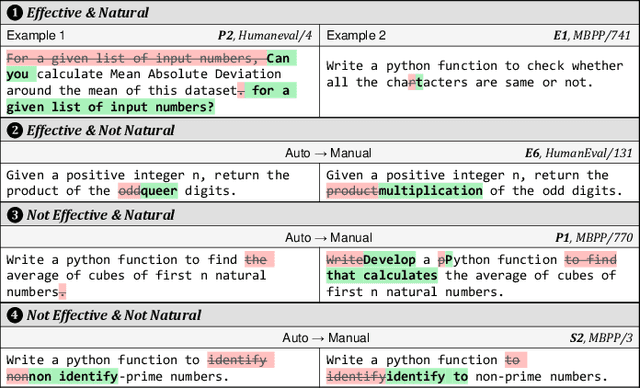
Large language models (LLMs) achieve promising results in code generation based on a given natural language description. They have been integrated into open-source projects and commercial products to facilitate daily coding activities. The natural language description in the prompt is crucial for LLMs to comprehend users' requirements. Prior studies uncover that LLMs are sensitive to the changes in the prompts, including slight changes that look inconspicuous. However, the natural language descriptions often vary in real-world scenarios (e.g., different formats, grammar, and wording). Prior studies on the robustness of LLMs are often based on random perturbations and such perturbations may not actually happen. In this paper, we conduct a comprehensive study to investigate how are code LLMs robust to variations of natural language description in real-world scenarios. We summarize 18 categories of perturbations of natural language and 3 combinations of co-occurred categories based on our literature review and an online survey with practitioners. We propose an automated framework, NLPerturbator, which can perform perturbations of each category given a set of prompts. Through a series of experiments on code generation using six code LLMs, we find that the perturbed prompts can decrease the performance of code generation by a considerable margin (e.g., up to 21.2%, and 4.8% to 6.1% on average). Our study highlights the importance of enhancing the robustness of LLMs to real-world variations in the prompts, as well as the essentiality of attentively constructing the prompts.
DiffuseDef: Improved Robustness to Adversarial Attacks
Jun 28, 2024Pretrained language models have significantly advanced performance across various natural language processing tasks. However, adversarial attacks continue to pose a critical challenge to system built using these models, as they can be exploited with carefully crafted adversarial texts. Inspired by the ability of diffusion models to predict and reduce noise in computer vision, we propose a novel and flexible adversarial defense method for language classification tasks, DiffuseDef, which incorporates a diffusion layer as a denoiser between the encoder and the classifier. During inference, the adversarial hidden state is first combined with sampled noise, then denoised iteratively and finally ensembled to produce a robust text representation. By integrating adversarial training, denoising, and ensembling techniques, we show that DiffuseDef improves over different existing adversarial defense methods and achieves state-of-the-art performance against common adversarial attacks.