 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobuNFR: Evaluating the Robustness of Large Language Models on Non-Functional Requirements Aware Code Generation
Mar 28, 2025When using LLMs to address Non-Functional Requirements (NFRs), developers may behave differently (e.g., expressing the same NFR in different words). Robust LLMs should output consistent results across these variations; however, this aspect remains underexplored. We propose RobuNFR for evaluating the robustness of LLMs in NFR-aware code generation across four NFR dimensions: design, readability, reliability, and performance, using three methodologies: prompt variation, regression testing, and diverse workflows. Our experiments show that RobuNFR reveals robustness issues in the tested LLMs when considering NFRs in code generation. Specifically, under prompt variation, including NFRs leads to a decrease in Pass@1 by up to 39 percent and an increase in the standard deviation from 0.48 to 2.48 compared to the baseline without NFRs (i.e., Function-Only). While incorporating NFRs generally improves overall NFR metrics, it also results in higher prompt sensitivity. In regression settings, some LLMs exhibit differences across versions, with improvements in one aspect (e.g., reduced code smells) often accompanied by regressions in another (e.g., decreased correctness), revealing inconsistencies that challenge their robustness. When varying workflows, the tested LLMs show significantly different NFR-aware code generation capabilities between two workflows: (1) integrating NFRs and functional requirements into the initial prompt and (2) enhancing Function-Only-generated code with the same NFR.
Generalization of Urban Wind Environment Using Fourier Neural Operator Across Different Wind Directions and Cities
Jan 09, 2025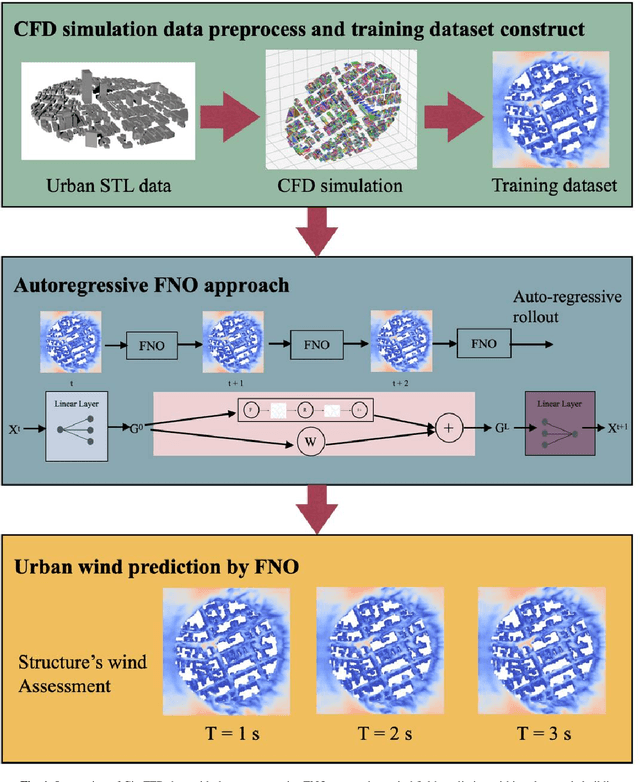

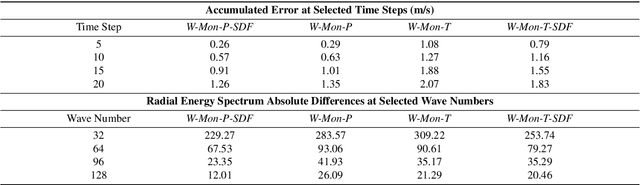
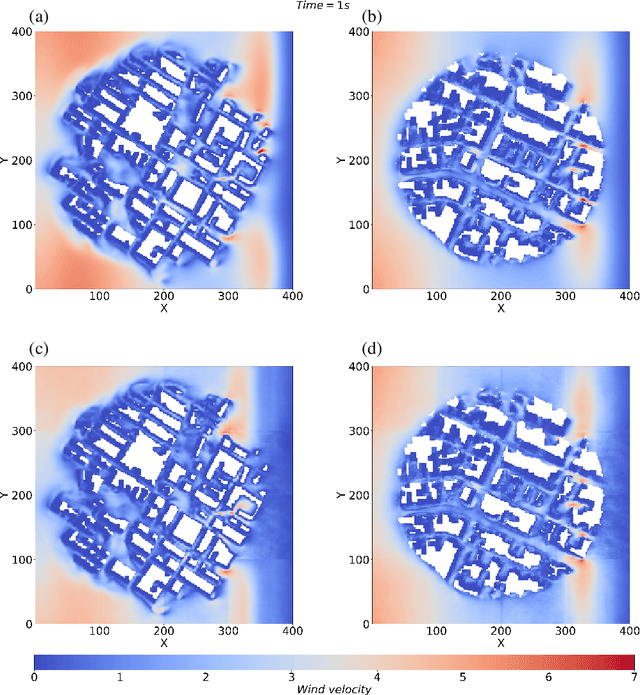
Simulation of urban wind environments is crucial for urban planning, pollution control, and renewable energy utilization. However, the computational requirements of high-fidelity computational fluid dynamics (CFD) methods make them impractical for real cities. To address these limitations, this study investigates the effectiveness of the Fourier Neural Operator (FNO) model in predicting flow fields under different wind directions and urban layouts. In this study, we investigate the effectiveness of the Fourier Neural Operator (FNO) model in predicting urban wind conditions under different wind directions and urban layouts. By training the model on velocity data from large eddy simulation data, we evaluate the performance of the model under different urban configurations and wind conditions. The results show that the FNO model can provide accurate predictions while significantly reducing the computational time by 99%. Our innovative approach of dividing the wind field into smaller spatial blocks for training improves the ability of the FNO model to capture wind frequency features effectively. The SDF data also provides important spatial building information, enhancing the model's ability to recognize physical boundaries and generate more realistic predictions. The proposed FNO approach enhances the AI model's generalizability for different wind directions and urban layouts.
Time to Retrain? Detecting Concept Drifts in Machine Learning Systems
Oct 11, 2024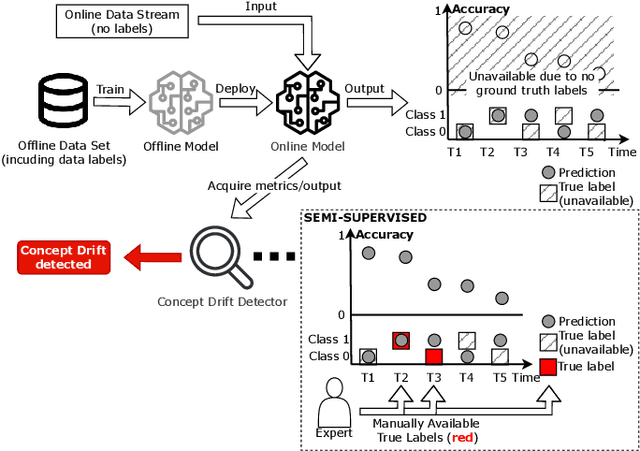
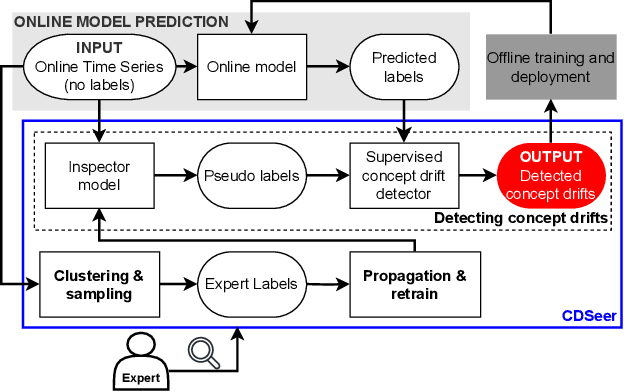
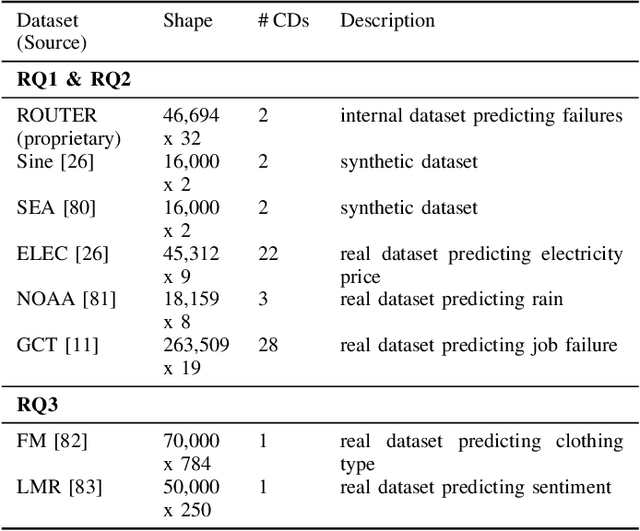
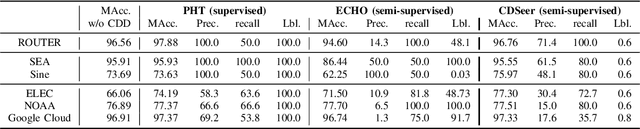
With the boom of machine learning (ML) techniques, software practitioners build ML systems to process the massive volume of streaming data for diverse software engineering tasks such as failure prediction in AIOps. Trained using historical data, such ML models encounter performance degradation caused by concept drift, i.e., data and inter-relationship (concept) changes between training and production. It is essential to use concept rift detection to monitor the deployed ML models and re-train the ML models when needed. In this work, we explore applying state-of-the-art (SOTA) concept drift detection techniques on synthetic and real-world datasets in an industrial setting. Such an industrial setting requires minimal manual effort in labeling and maximal generality in ML model architecture. We find that current SOTA semi-supervised methods not only require significant labeling effort but also only work for certain types of ML models. To overcome such limitations, we propose a novel model-agnostic technique (CDSeer) for detecting concept drift. Our evaluation shows that CDSeer has better precision and recall compared to the state-of-the-art while requiring significantly less manual labeling. We demonstrate the effectiveness of CDSeer at concept drift detection by evaluating it on eight datasets from different domains and use cases. Results from internal deployment of CDSeer on an industrial proprietary dataset show a 57.1% improvement in precision while using 99% fewer labels compared to the SOTA concept drift detection method. The performance is also comparable to the supervised concept drift detection method, which requires 100% of the data to be labeled. The improved performance and ease of adoption of CDSeer are valuable in making ML systems more reliable.
Evaluating and Improving the Robustness of LiDAR-based Localization and Mapping
Sep 17, 2024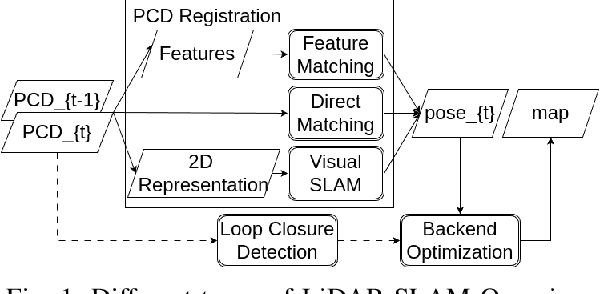

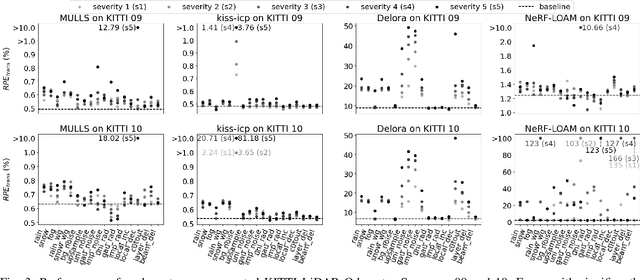
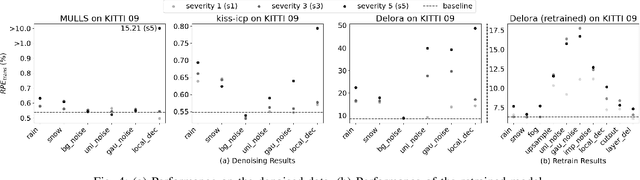
LiDAR is one of the most commonly adopted sensors for simultaneous localization and mapping (SLAM) and map-based global localization. SLAM and map-based localization are crucial for the independent operation of autonomous systems, especially when external signals such as GNSS are unavailable or unreliable. While state-of-the-art (SOTA) LiDAR SLAM systems could achieve 0.5% (i.e., 0.5m per 100m) of errors and map-based localization could achieve centimeter-level global localization, it is still unclear how robust they are under various common LiDAR data corruptions. In this work, we extensively evaluated five SOTA LiDAR-based localization systems under 18 common scene-level LiDAR point cloud data (PCD) corruptions. We found that the robustness of LiDAR-based localization varies significantly depending on the category. For SLAM, hand-crafted methods are in general robust against most types of corruption, while being extremely vulnerable (up to +80% errors) to a specific corruption. Learning-based methods are vulnerable to most types of corruptions. For map-based global localization, we found that the SOTA is resistant to all applied corruptions. Finally, we found that simple Bilateral Filter denoising effectively eliminates noise-based corruption but is not helpful in density-based corruption. Re-training is more effective in defending learning-based SLAM against all types of corruption.
A Survey on Query-based API Recommendation
Dec 21, 2023Application Programming Interfaces (APIs) are designed to help developers build software more effectively. Recommending the right APIs for specific tasks has gained increasing attention among researchers and developers in recent years. To comprehensively understand this research domain, we have surveyed to analyze API recommendation studies published in the last 10 years. Our study begins with an overview of the structure of API recommendation tools. Subsequently, we systematically analyze prior research and pose four key research questions. For RQ1, we examine the volume of published papers and the venues in which these papers appear within the API recommendation field. In RQ2, we categorize and summarize the prevalent data sources and collection methods employed in API recommendation research. In RQ3, we explore the types of data and common data representations utilized by API recommendation approaches. We also investigate the typical data extraction procedures and collection approaches employed by the existing approaches. RQ4 delves into the modeling techniques employed by API recommendation approaches, encompassing both statistical and deep learning models. Additionally, we compile an overview of the prevalent ranking strategies and evaluation metrics used for assessing API recommendation tools. Drawing from our survey findings, we identify current challenges in API recommendation research that warrant further exploration, along with potential avenues for future research.