 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint-Aware Generative Re-ranking for Multi-Objective Optimization in Advertising Feeds
Mar 04, 2026Optimizing reranking in advertising feeds is a constrained combinatorial problem, requiring simultaneous maximization of platform revenue and preservation of user experience. Recent generative ranking methods enable listwise optimization via autoregressive decoding, but their deployment is hindered by high inference latency and limited constraint handling. We propose a constraint-aware generative reranking framework that transforms constrained optimization into bounded neural decoding. Unlike prior approaches that separate generator and evaluator models, our framework unifies sequence generation and reward estimation into a single network. We further introduce constraint-aware reward pruning, integrating constraint satisfaction directly into decoding to efficiently generate optimal sequences. Experiments on large-scale industrial feeds and online A/B tests show that our method improves revenue and user engagement while meeting strict latency requirements, providing an efficient neural solution for constrained listwise optimization.
Generalization of Urban Wind Environment Using Fourier Neural Operator Across Different Wind Directions and Cities
Jan 09, 2025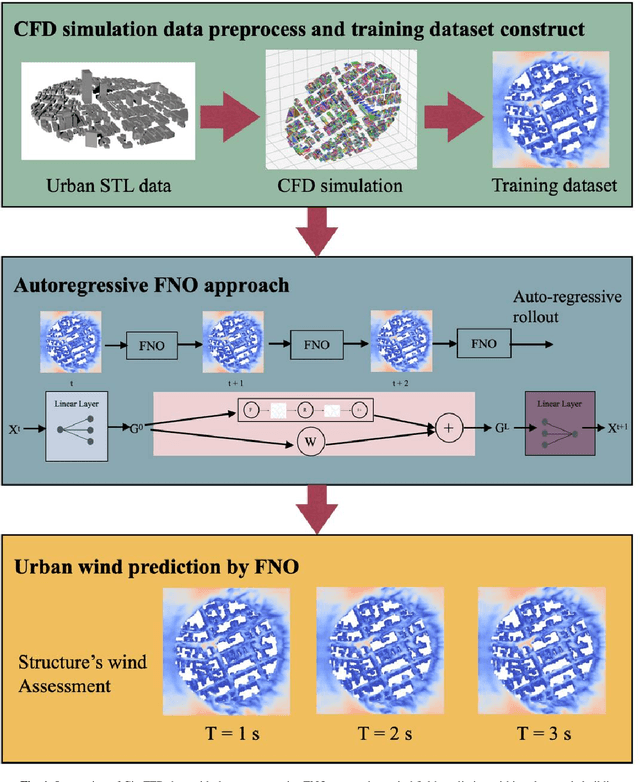

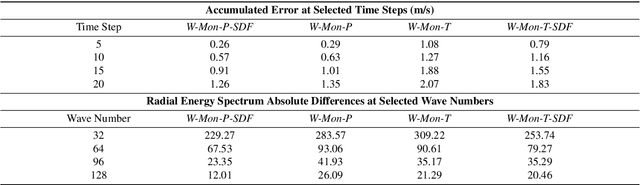
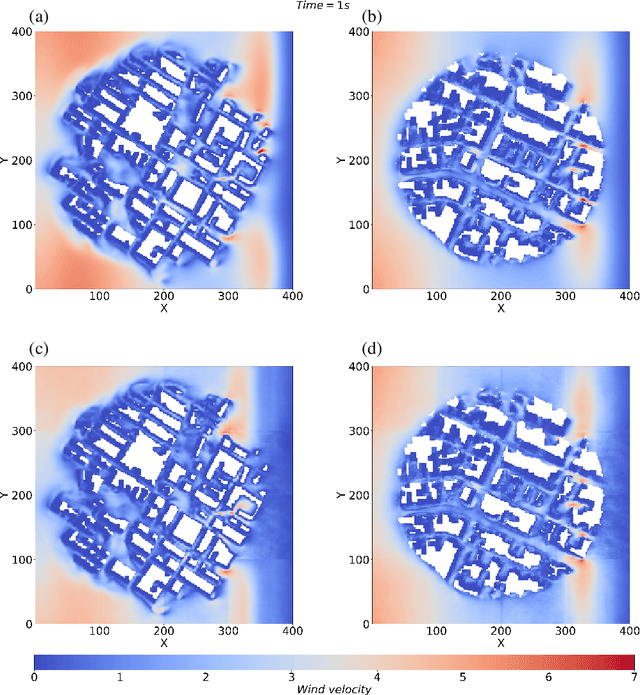
Simulation of urban wind environments is crucial for urban planning, pollution control, and renewable energy utilization. However, the computational requirements of high-fidelity computational fluid dynamics (CFD) methods make them impractical for real cities. To address these limitations, this study investigates the effectiveness of the Fourier Neural Operator (FNO) model in predicting flow fields under different wind directions and urban layouts. In this study, we investigate the effectiveness of the Fourier Neural Operator (FNO) model in predicting urban wind conditions under different wind directions and urban layouts. By training the model on velocity data from large eddy simulation data, we evaluate the performance of the model under different urban configurations and wind conditions. The results show that the FNO model can provide accurate predictions while significantly reducing the computational time by 99%. Our innovative approach of dividing the wind field into smaller spatial blocks for training improves the ability of the FNO model to capture wind frequency features effectively. The SDF data also provides important spatial building information, enhancing the model's ability to recognize physical boundaries and generate more realistic predictions. The proposed FNO approach enhances the AI model's generalizability for different wind directions and urban layouts.
Modeling Multivariable High-resolution 3D Urban Microclimate Using Localized Fourier Neural Operator
Nov 18, 2024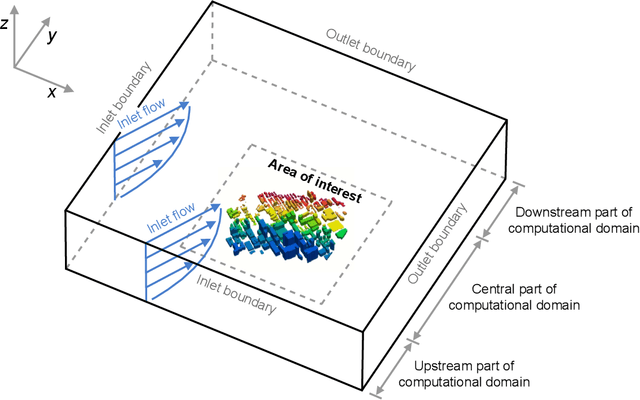

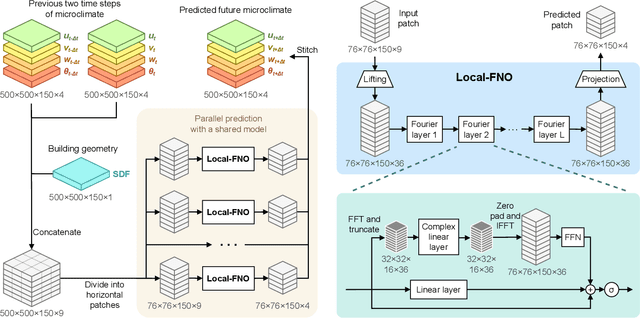

Accurate urban microclimate analysis with wind velocity and temperature is vital for energy-efficient urban planning, supporting carbon reduction, enhancing public health and comfort, and advancing the low-altitude economy. However, traditional computational fluid dynamics (CFD) simulations that couple velocity and temperature are computationally expensive. Recent machine learning advancements offer promising alternatives for accelerating urban microclimate simulations. The Fourier neural operator (FNO) has shown efficiency and accuracy in predicting single-variable velocity magnitudes in urban wind fields. Yet, for multivariable high-resolution 3D urban microclimate prediction, FNO faces three key limitations: blurry output quality, high GPU memory demand, and substantial data requirements. To address these issues, we propose a novel localized Fourier neural operator (Local-FNO) model that employs local training, geometry encoding, and patch overlapping. Local-FNO provides accurate predictions for rapidly changing turbulence in urban microclimate over 60 seconds, four times the average turbulence integral time scale, with an average error of 0.35 m/s in velocity and 0.30 {\deg}C in temperature. It also accurately captures turbulent heat flux represented by the velocity-temperature correlation. In a 2 km by 2 km domain, Local-FNO resolves turbulence patterns down to a 10 m resolution. It provides high-resolution predictions with 150 million feature dimensions on a single 32 GB GPU at nearly 50 times the speed of a CFD solver. Compared to FNO, Local-FNO achieves a 23.9% reduction in prediction error and a 47.3% improvement in turbulent fluctuation correlation.
Convergence Analysis of Split Federated Learning on Heterogeneous Data
Feb 23, 2024Split federated learning (SFL) is a recent distributed approach for collaborative model training among multiple clients. In SFL, a global model is typically split into two parts, where clients train one part in a parallel federated manner, and a main server trains the other. Despite the recent research on SFL algorithm development, the convergence analysis of SFL is missing in the literature, and this paper aims to fill this gap. The analysis of SFL can be more challenging than that of federated learning (FL), due to the potential dual-paced updates at the clients and the main server. We provide convergence analysis of SFL for strongly convex and general convex objectives on heterogeneous data. The convergence rates are $O(1/T)$ and $O(1/\sqrt[3]{T})$, respectively, where $T$ denotes the total number of rounds for SFL training. We further extend the analysis to non-convex objectives and where some clients may be unavailable during training. Numerical experiments validate our theoretical results and show that SFL outperforms FL and split learning (SL) when data is highly heterogeneous across a large number of clients.
When MiniBatch SGD Meets SplitFed Learning:Convergence Analysis and Performance Evaluation
Aug 23, 2023Federated learning (FL) enables collaborative model training across distributed clients (e.g., edge devices) without sharing raw data. Yet, FL can be computationally expensive as the clients need to train the entire model multiple times. SplitFed learning (SFL) is a recent distributed approach that alleviates computation workload at the client device by splitting the model at a cut layer into two parts, where clients only need to train part of the model. However, SFL still suffers from the \textit{client drift} problem when clients' data are highly non-IID. To address this issue, we propose MiniBatch-SFL. This algorithm incorporates MiniBatch SGD into SFL, where the clients train the client-side model in an FL fashion while the server trains the server-side model similar to MiniBatch SGD. We analyze the convergence of MiniBatch-SFL and show that the bound of the expected loss can be obtained by analyzing the expected server-side and client-side model updates, respectively. The server-side updates do not depend on the non-IID degree of the clients' datasets and can potentially mitigate client drift. However, the client-side model relies on the non-IID degree and can be optimized by properly choosing the cut layer. Perhaps counter-intuitive, our empirical result shows that a latter position of the cut layer leads to a smaller average gradient divergence and a better algorithm performance. Moreover, numerical results show that MiniBatch-SFL achieves higher accuracy than conventional SFL and FL. The accuracy improvement can be up to 24.1\% and 17.1\% with highly non-IID data, respectively.