 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Personalized Split Federated Learning for On-Device Fine-Tuning of Foundation Models
Aug 14, 2025Fine-tuning foundation models is critical for superior performance on personalized downstream tasks, compared to using pre-trained models. Collaborative learning can leverage local clients' datasets for fine-tuning, but limited client data and heterogeneous data distributions hinder effective collaboration. To address the challenge, we propose a flexible personalized federated learning paradigm that enables clients to engage in collaborative learning while maintaining personalized objectives. Given the limited and heterogeneous computational resources available on clients, we introduce \textbf{flexible personalized split federated learning (FlexP-SFL)}. Based on split learning, FlexP-SFL allows each client to train a portion of the model locally while offloading the rest to a server, according to resource constraints. Additionally, we propose an alignment strategy to improve personalized model performance on global data. Experimental results show that FlexP-SFL outperforms baseline models in personalized fine-tuning efficiency and final accuracy.
SemiDFL: A Semi-Supervised Paradigm for Decentralized Federated Learning
Dec 18, 2024



Decentralized federated learning (DFL) realizes cooperative model training among connected clients without relying on a central server, thereby mitigating communication bottlenecks and eliminating the single-point failure issue present in centralized federated learning (CFL). Most existing work on DFL focuses on supervised learning, assuming each client possesses sufficient labeled data for local training. However, in real-world applications, much of the data is unlabeled. We address this by considering a challenging yet practical semisupervised learning (SSL) scenario in DFL, where clients may have varying data sources: some with few labeled samples, some with purely unlabeled data, and others with both. In this work, we propose SemiDFL, the first semi-supervised DFL method that enhances DFL performance in SSL scenarios by establishing a consensus in both data and model spaces. Specifically, we utilize neighborhood information to improve the quality of pseudo-labeling, which is crucial for effectively leveraging unlabeled data. We then design a consensusbased diffusion model to generate synthesized data, which is used in combination with pseudo-labeled data to create mixed datasets. Additionally, we develop an adaptive aggregation method that leverages the model accuracy of synthesized data to further enhance SemiDFL performance. Through extensive experimentation, we demonstrate the remarkable performance superiority of the proposed DFL-Semi method over existing CFL and DFL schemes in both IID and non-IID SSL scenarios.
Convergence Analysis of Split Federated Learning on Heterogeneous Data
Feb 23, 2024Split federated learning (SFL) is a recent distributed approach for collaborative model training among multiple clients. In SFL, a global model is typically split into two parts, where clients train one part in a parallel federated manner, and a main server trains the other. Despite the recent research on SFL algorithm development, the convergence analysis of SFL is missing in the literature, and this paper aims to fill this gap. The analysis of SFL can be more challenging than that of federated learning (FL), due to the potential dual-paced updates at the clients and the main server. We provide convergence analysis of SFL for strongly convex and general convex objectives on heterogeneous data. The convergence rates are $O(1/T)$ and $O(1/\sqrt[3]{T})$, respectively, where $T$ denotes the total number of rounds for SFL training. We further extend the analysis to non-convex objectives and where some clients may be unavailable during training. Numerical experiments validate our theoretical results and show that SFL outperforms FL and split learning (SL) when data is highly heterogeneous across a large number of clients.
Federated Learning While Providing Model as a Service: Joint Training and Inference Optimization
Dec 21, 2023While providing machine learning model as a service to process users' inference requests, online applications can periodically upgrade the model utilizing newly collected data. Federated learning (FL) is beneficial for enabling the training of models across distributed clients while keeping the data locally. However, existing work has overlooked the coexistence of model training and inference under clients' limited resources. This paper focuses on the joint optimization of model training and inference to maximize inference performance at clients. Such an optimization faces several challenges. The first challenge is to characterize the clients' inference performance when clients may partially participate in FL. To resolve this challenge, we introduce a new notion of age of model (AoM) to quantify client-side model freshness, based on which we use FL's global model convergence error as an approximate measure of inference performance. The second challenge is the tight coupling among clients' decisions, including participation probability in FL, model download probability, and service rates. Toward the challenges, we propose an online problem approximation to reduce the problem complexity and optimize the resources to balance the needs of model training and inference. Experimental results demonstrate that the proposed algorithm improves the average inference accuracy by up to 12%.
FedAL: Black-Box Federated Knowledge Distillation Enabled by Adversarial Learning
Nov 28, 2023

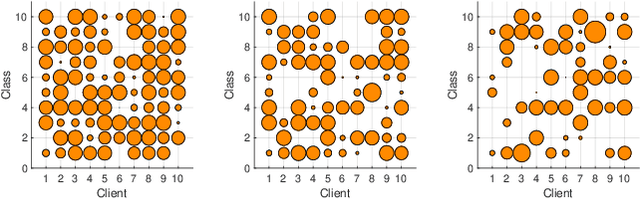

Knowledge distillation (KD) can enable collaborative learning among distributed clients that have different model architectures and do not share their local data and model parameters with others. Each client updates its local model using the average model output/feature of all client models as the target, known as federated KD. However, existing federated KD methods often do not perform well when clients' local models are trained with heterogeneous local datasets. In this paper, we propose Federated knowledge distillation enabled by Adversarial Learning (FedAL) to address the data heterogeneity among clients. First, to alleviate the local model output divergence across clients caused by data heterogeneity, the server acts as a discriminator to guide clients' local model training to achieve consensus model outputs among clients through a min-max game between clients and the discriminator. Moreover, catastrophic forgetting may happen during the clients' local training and global knowledge transfer due to clients' heterogeneous local data. Towards this challenge, we design the less-forgetting regularization for both local training and global knowledge transfer to guarantee clients' ability to transfer/learn knowledge to/from others. Experimental results show that FedAL and its variants achieve higher accuracy than other federated KD baselines.
Incentive Mechanism Design for Distributed Ensemble Learning
Oct 13, 2023



Distributed ensemble learning (DEL) involves training multiple models at distributed learners, and then combining their predictions to improve performance. Existing related studies focus on DEL algorithm design and optimization but ignore the important issue of incentives, without which self-interested learners may be unwilling to participate in DEL. We aim to fill this gap by presenting a first study on the incentive mechanism design for DEL. Our proposed mechanism specifies both the amount of training data and reward for learners with heterogeneous computation and communication costs. One design challenge is to have an accurate understanding regarding how learners' diversity (in terms of training data) affects the ensemble accuracy. To this end, we decompose the ensemble accuracy into a diversity-precision tradeoff to guide the mechanism design. Another challenge is that the mechanism design involves solving a mixed-integer program with a large search space. To this end, we propose an alternating algorithm that iteratively updates each learner's training data size and reward. We prove that under mild conditions, the algorithm converges. Numerical results using MNIST dataset show an interesting result: our proposed mechanism may prefer a lower level of learner diversity to achieve a higher ensemble accuracy.
Lightweight Self-Knowledge Distillation with Multi-source Information Fusion
May 16, 2023Knowledge Distillation (KD) is a powerful technique for transferring knowledge between neural network models, where a pre-trained teacher model is used to facilitate the training of the target student model. However, the availability of a suitable teacher model is not always guaranteed. To address this challenge, Self-Knowledge Distillation (SKD) attempts to construct a teacher model from itself. Existing SKD methods add Auxiliary Classifiers (AC) to intermediate layers of the model or use the history models and models with different input data within the same class. However, these methods are computationally expensive and only capture time-wise and class-wise features of data. In this paper, we propose a lightweight SKD framework that utilizes multi-source information to construct a more informative teacher. Specifically, we introduce a Distillation with Reverse Guidance (DRG) method that considers different levels of information extracted by the model, including edge, shape, and detail of the input data, to construct a more informative teacher. Additionally, we design a Distillation with Shape-wise Regularization (DSR) method that ensures a consistent shape of ranked model output for all data. We validate the performance of the proposed DRG, DSR, and their combination through comprehensive experiments on various datasets and models. Our results demonstrate the superiority of the proposed methods over baselines (up to 2.87%) and state-of-the-art SKD methods (up to 1.15%), while being computationally efficient and robust. The code is available at https://github.com/xucong-parsifal/LightSKD.
Optimization Design for Federated Learning in Heterogeneous 6G Networks
Mar 15, 2023



With the rapid advancement of 5G networks, billions of smart Internet of Things (IoT) devices along with an enormous amount of data are generated at the network edge. While still at an early age, it is expected that the evolving 6G network will adopt advanced artificial intelligence (AI) technologies to collect, transmit, and learn this valuable data for innovative applications and intelligent services. However, traditional machine learning (ML) approaches require centralizing the training data in the data center or cloud, raising serious user-privacy concerns. Federated learning, as an emerging distributed AI paradigm with privacy-preserving nature, is anticipated to be a key enabler for achieving ubiquitous AI in 6G networks. However, there are several system and statistical heterogeneity challenges for effective and efficient FL implementation in 6G networks. In this article, we investigate the optimization approaches that can effectively address the challenging heterogeneity issues from three aspects: incentive mechanism design, network resource management, and personalized model optimization. We also present some open problems and promising directions for future research.
Robustness and Diversity Seeking Data-Free Knowledge Distillation
Nov 07, 2020


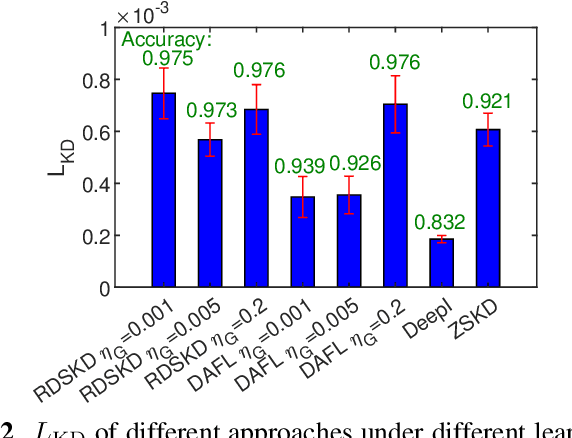
Knowledge distillation (KD) has enabled remarkable progress in model compression and knowledge transfer. However, KD requires a large volume of original data or their representation statistics that are not usually available in practice. Data-free KD has recently been proposed to resolve this problem, wherein teacher and student models are fed by a synthetic sample generator trained from the teacher. Nonetheless, existing data-free KD methods rely on fine-tuning of weights to balance multiple losses, and ignore the diversity of generated samples, resulting in limited accuracy and robustness. To overcome this challenge, we propose robustness and diversity seeking data-free KD (RDSKD) in this paper. The generator loss function is crafted to produce samples with high authenticity, class diversity, and inter-sample diversity. Without real data, the objectives of seeking high sample authenticity and class diversity often conflict with each other, causing frequent loss fluctuations. We mitigate this by exponentially penalizing loss increments. With MNIST, CIFAR-10, and SVHN datasets, our experiments show that RDSKD achieves higher accuracy with more robustness over different hyperparameter settings, compared to other data-free KD methods such as DAFL, MSKD, ZSKD, and DeepInversion.
Adaptive Gradient Sparsification for Efficient Federated Learning: An Online Learning Approach
Jan 16, 2020


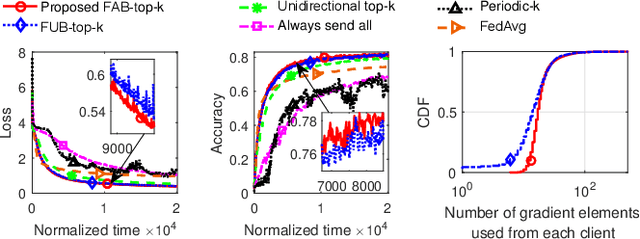
Federated learning (FL) is an emerging technique for training machine learning models using geographically dispersed data collected by local entities. It includes local computation and synchronization steps. To reduce the communication overhead and improve the overall efficiency of FL, gradient sparsification (GS) can be applied, where instead of the full gradient, only a small subset of important elements of the gradient is communicated. Existing work on GS uses a fixed degree of gradient sparsity for i.i.d.-distributed data within a datacenter. In this paper, we consider adaptive degree of sparsity and non-i.i.d. local datasets. We first present a fairness-aware GS method which ensures that different clients provide a similar amount of updates. Then, with the goal of minimizing the overall training time, we propose a novel online learning formulation and algorithm for automatically determining the near-optimal communication and computation trade-off that is controlled by the degree of gradient sparsity. The online learning algorithm uses an estimated sign of the derivative of the objective function, which gives a regret bound that is asymptotically equal to the case where exact derivative is available. Experiments with real datasets confirm the benefits of our proposed approaches, showing up to $40\%$ improvement in model accuracy for a finite training time.