 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Homophily: Towards Generalized Graph Reconstruction Attack and Defense
Jun 06, 2026Graph neural networks (GNNs) are widely deployed on relational data, yet they can leak sensitive or proprietary information about the training graph adjacency, e.g., social ties, transactions, and interactions. This work studies graph reconstruction attacks (GRA), a form of model inversion that reconstructs the training adjacency from a trained GNN, given different levels of attacker-side information. We first provide a systematic characterization of when and why adjacency becomes recoverable through features, labels, embeddings, and predictions, with leakage modulated by graph homophily, heterophily, and the model's inductive bias. Motivated by these findings, we view GNN inference through a Markov chain approximation lens, treating the layered forward computation as a chain of topology-dependent representations. Building on this view, we develop complementary attack and defense methods. On the attack side, we propose MC-GRA (+), which reconstructs the adjacency by optimizing a surrogate adjacency whose GNN-induced representations align with those of the target model at each layer. On the defense side, we propose MC-GPB (+), which suppresses adjacency-dependent information throughout the representation chain while aiming to preserve classification accuracy under a privacy-utility trade-off. Experiments across homophilic/heterophilic graph benchmarks and GNNs show that our attacks improve reconstruction fidelity over prior methods, while our defenses reduce reconstruction success with only minor accuracy loss.
Deliberate Evolution: Agentic Reasoning for Sample-Efficient Symbolic Regression with LLMs
Jun 03, 2026Symbolic regression (SR) discovers compact mathematical expressions from data, yet recent LLM-based evolutionary methods remain sample-inefficient because they rely mainly on scalar feedback such as MSE. We identify a core limitation: existing methods conflate candidate proposal with search guidance, requiring the LLM to infer how to evolve an expression, diagnose its errors, and reuse past experience from a single score. To address this, we propose Deliberate Evolution (DE), an agentic framework that decouples symbolic generation from search control. DE guides LLM proposals with adaptive operators for search direction, analytical tools for structural diagnosis, and reflective memory for trajectory-level experience. Experiments on LLM-SRBench show that DE consistently outperforms representative LLM-based SR baselines across diverse scientific domains while using only 40% of the standard sample budget.
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Multi-Granularity Reasoning for Image Quality Assessment via Attribute-Aware Reinforcement Learning to Rank
Apr 07, 2026Recent advances in reasoning-induced image quality assessment (IQA) have demonstrated the power of reinforcement learning to rank (RL2R) for training vision-language models (VLMs) to assess perceptual quality. However, existing approaches operate at a single granularity, predicting only an overall quality score, while overlooking the multi-dimensional nature of human quality perception, which encompasses attributes such as sharpness, color fidelity, noise level, and compositional aesthetics. In this paper, we propose MG-IQA (Multi-Granularity IQA), a multi-granularity reasoning framework that extends RL2R to jointly assess overall image quality and fine-grained quality attributes within a single inference pass. Our approach introduces three key innovations: (1) an attribute-aware prompting strategy that elicits structured multi-attribute reasoning from VLMs; (2) a multi-dimensional Thurstone reward model that computes attribute-specific fidelity rewards for group relative policy optimization; and (3) a cross-domain alignment mechanism that enables stable joint training across synthetic distortion, authentic distortion, and AI-generated image datasets without perceptual scale re-alignment. Extensive experiments on eight IQA benchmarks demonstrate that MG-IQA consistently outperforms state-of-the-art methods in both overall quality prediction (average SRCC improvement of 2.1\%) and attribute-level assessment, while generating interpretable, human-aligned quality descriptions.
AuTAgent: A Reinforcement Learning Framework for Tool-Augmented Audio Reasoning
Feb 14, 2026Large Audio Language Models (LALMs) excel at perception but struggle with complex reasoning requiring precise acoustic measurements. While external tools can extract fine-grained features like exact tempo or pitch, effective integration remains challenging: naively using all tools causes information overload, while prompt-based selection fails to assess context-dependent utility. To address this, we propose AuTAgent (Audio Tool Agent), a reinforcement learning framework that learns when and which tools to invoke. By employing a sparse-feedback training strategy with a novel Differential Reward mechanism, the agent learns to filter out irrelevant tools and invokes external assistance only when it yields a net performance gain over the base model. Experimental results confirm that AuTAgent complements the representation bottleneck of LALMs by providing verifiable acoustic evidence. It improves accuracy by 4.20% / 6.20% and 9.80% / 8.00% for open-source and closed-source backbones on the MMAU Test-mini and the MMAR benchmarks, respectively. In addition, further experiments demonstrate exceptional transferability. We highlight the complementary role of external tools in augmenting audio model reasoning.
SAGE: Scalable Agentic 3D Scene Generation for Embodied AI
Feb 10, 2026Real-world data collection for embodied agents remains costly and unsafe, calling for scalable, realistic, and simulator-ready 3D environments. However, existing scene-generation systems often rely on rule-based or task-specific pipelines, yielding artifacts and physically invalid scenes. We present SAGE, an agentic framework that, given a user-specified embodied task (e.g., "pick up a bowl and place it on the table"), understands the intent and automatically generates simulation-ready environments at scale. The agent couples multiple generators for layout and object composition with critics that evaluate semantic plausibility, visual realism, and physical stability. Through iterative reasoning and adaptive tool selection, it self-refines the scenes until meeting user intent and physical validity. The resulting environments are realistic, diverse, and directly deployable in modern simulators for policy training. Policies trained purely on this data exhibit clear scaling trends and generalize to unseen objects and layouts, demonstrating the promise of simulation-driven scaling for embodied AI. Code, demos, and the SAGE-10k dataset can be found on the project page here: https://nvlabs.github.io/sage.
BayesRAG: Probabilistic Mutual Evidence Corroboration for Multimodal Retrieval-Augmented Generation
Jan 12, 2026Retrieval-Augmented Generation (RAG) has become a pivotal paradigm for Large Language Models (LLMs), yet current approaches struggle with visually rich documents by treating text and images as isolated retrieval targets. Existing methods relying solely on cosine similarity often fail to capture the semantic reinforcement provided by cross-modal alignment and layout-induced coherence. To address these limitations, we propose BayesRAG, a novel multimodal retrieval framework grounded in Bayesian inference and Dempster-Shafer evidence theory. Unlike traditional approaches that rank candidates strictly by similarity, BayesRAG models the intrinsic consistency of retrieved candidates across modalities as probabilistic evidence to refine retrieval confidence. Specifically, our method computes the posterior association probability for combinations of multimodal retrieval results, prioritizing text-image pairs that mutually corroborate each other in terms of both semantics and layout. Extensive experiments demonstrate that BayesRAG significantly outperforms state-of-the-art (SOTA) methods on challenging multimodal benchmarks. This study establishes a new paradigm for multimodal retrieval fusion that effectively resolves the isolation of heterogeneous modalities through an evidence fusion mechanism and enhances the robustness of retrieval outcomes. Our code is available at https://github.com/TioeAre/BayesRAG.
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
DK-Root: A Joint Data-and-Knowledge-Driven Framework for Root Cause Analysis of QoE Degradations in Mobile Networks
Nov 13, 2025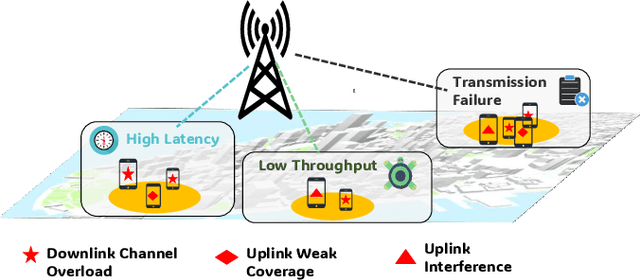
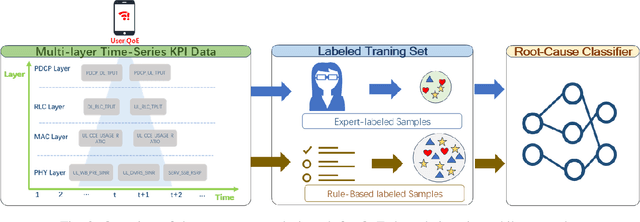
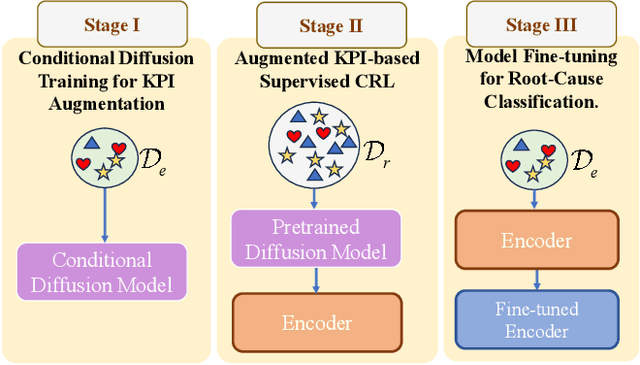
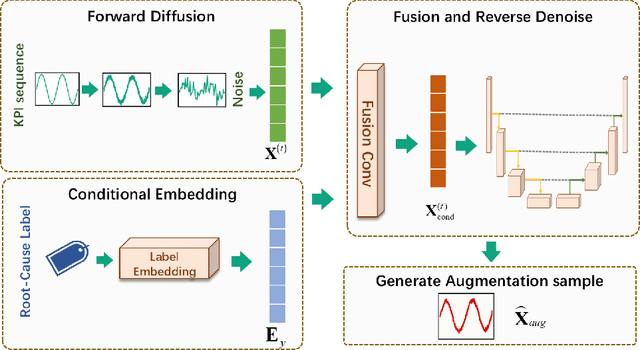
Diagnosing the root causes of Quality of Experience (QoE) degradations in operational mobile networks is challenging due to complex cross-layer interactions among kernel performance indicators (KPIs) and the scarcity of reliable expert annotations. Although rule-based heuristics can generate labels at scale, they are noisy and coarse-grained, limiting the accuracy of purely data-driven approaches. To address this, we propose DK-Root, a joint data-and-knowledge-driven framework that unifies scalable weak supervision with precise expert guidance for robust root-cause analysis. DK-Root first pretrains an encoder via contrastive representation learning using abundant rule-based labels while explicitly denoising their noise through a supervised contrastive objective. To supply task-faithful data augmentation, we introduce a class-conditional diffusion model that generates KPIs sequences preserving root-cause semantics, and by controlling reverse diffusion steps, it produces weak and strong augmentations that improve intra-class compactness and inter-class separability. Finally, the encoder and the lightweight classifier are jointly fine-tuned with scarce expert-verified labels to sharpen decision boundaries. Extensive experiments on a real-world, operator-grade dataset demonstrate state-of-the-art accuracy, with DK-Root surpassing traditional ML and recent semi-supervised time-series methods. Ablations confirm the necessity of the conditional diffusion augmentation and the pretrain-finetune design, validating both representation quality and classification gains.
DeCoT: Decomposing Complex Instructions for Enhanced Text-to-Image Generation with Large Language Models
Aug 17, 2025



Despite remarkable advancements, current Text-to-Image (T2I) models struggle with complex, long-form textual instructions, frequently failing to accurately render intricate details, spatial relationships, or specific constraints. This limitation is highlighted by benchmarks such as LongBench-T2I, which reveal deficiencies in handling composition, specific text, and fine textures. To address this, we propose DeCoT (Decomposition-CoT), a novel framework that leverages Large Language Models (LLMs) to significantly enhance T2I models' understanding and execution of complex instructions. DeCoT operates in two core stages: first, Complex Instruction Decomposition and Semantic Enhancement, where an LLM breaks down raw instructions into structured, actionable semantic units and clarifies ambiguities; second, Multi-Stage Prompt Integration and Adaptive Generation, which transforms these units into a hierarchical or optimized single prompt tailored for existing T2I models. Extensive experiments on the LongBench-T2I dataset demonstrate that DeCoT consistently and substantially improves the performance of leading T2I models across all evaluated dimensions, particularly in challenging aspects like "Text" and "Composition". Quantitative results, validated by multiple MLLM evaluators (Gemini-2.0-Flash and InternVL3-78B), show that DeCoT, when integrated with Infinity-8B, achieves an average score of 3.52, outperforming the baseline Infinity-8B (3.44). Ablation studies confirm the critical contribution of each DeCoT component and the importance of sophisticated LLM prompting. Furthermore, human evaluations corroborate these findings, indicating superior perceptual quality and instruction fidelity. DeCoT effectively bridges the gap between high-level user intent and T2I model requirements, leading to more faithful and accurate image generation.