 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression
Dec 18, 2025Accurate and efficient discrete video tokenization is essential for long video sequences processing. Yet, the inherent complexity and variable information density of videos present a significant bottleneck for current tokenizers, which rigidly compress all content at a fixed rate, leading to redundancy or information loss. Drawing inspiration from Shannon's information theory, this paper introduces InfoTok, a principled framework for adaptive video tokenization. We rigorously prove that existing data-agnostic training methods are suboptimal in representation length, and present a novel evidence lower bound (ELBO)-based algorithm that approaches theoretical optimality. Leveraging this framework, we develop a transformer-based adaptive compressor that enables adaptive tokenization. Empirical results demonstrate state-of-the-art compression performance, saving 20% tokens without influence on performance, and achieving 2.3x compression rates while still outperforming prior heuristic adaptive approaches. By allocating tokens according to informational richness, InfoTok enables a more compressed yet accurate tokenization for video representation, offering valuable insights for future research.
Efficient Part-level 3D Object Generation via Dual Volume Packing
Jun 11, 2025Recent progress in 3D object generation has greatly improved both the quality and efficiency. However, most existing methods generate a single mesh with all parts fused together, which limits the ability to edit or manipulate individual parts. A key challenge is that different objects may have a varying number of parts. To address this, we propose a new end-to-end framework for part-level 3D object generation. Given a single input image, our method generates high-quality 3D objects with an arbitrary number of complete and semantically meaningful parts. We introduce a dual volume packing strategy that organizes all parts into two complementary volumes, allowing for the creation of complete and interleaved parts that assemble into the final object. Experiments show that our model achieves better quality, diversity, and generalization than previous image-based part-level generation methods.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Meshtron: High-Fidelity, Artist-Like 3D Mesh Generation at Scale
Dec 12, 2024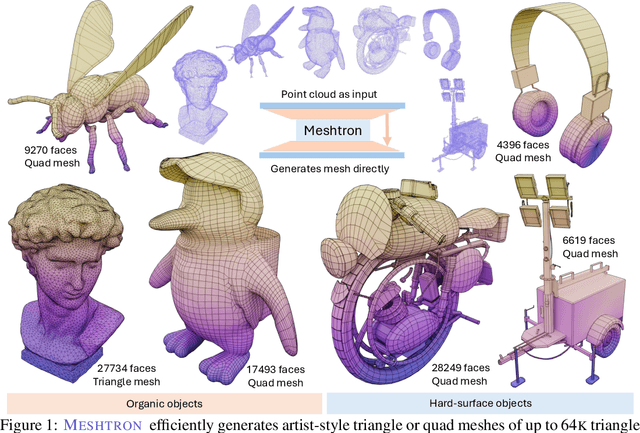
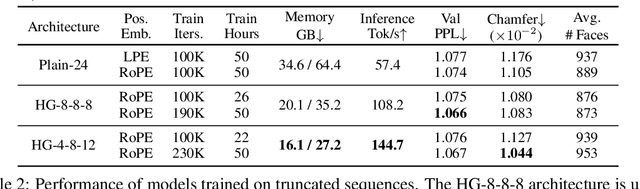
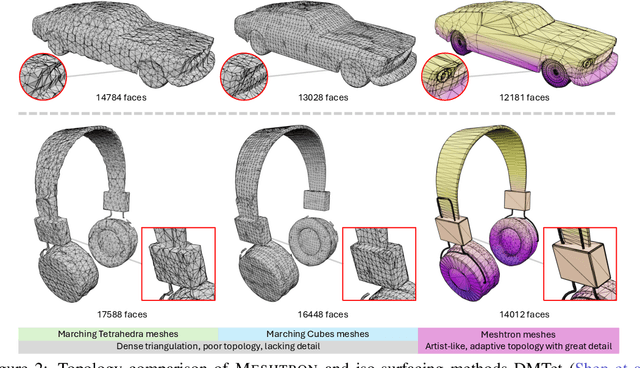

Meshes are fundamental representations of 3D surfaces. However, creating high-quality meshes is a labor-intensive task that requires significant time and expertise in 3D modeling. While a delicate object often requires over $10^4$ faces to be accurately modeled, recent attempts at generating artist-like meshes are limited to $1.6$K faces and heavy discretization of vertex coordinates. Hence, scaling both the maximum face count and vertex coordinate resolution is crucial to producing high-quality meshes of realistic, complex 3D objects. We present Meshtron, a novel autoregressive mesh generation model able to generate meshes with up to 64K faces at 1024-level coordinate resolution --over an order of magnitude higher face count and $8{\times}$ higher coordinate resolution than current state-of-the-art methods. Meshtron's scalability is driven by four key components: (1) an hourglass neural architecture, (2) truncated sequence training, (3) sliding window inference, (4) a robust sampling strategy that enforces the order of mesh sequences. This results in over $50{\%}$ less training memory, $2.5{\times}$ faster throughput, and better consistency than existing works. Meshtron generates meshes of detailed, complex 3D objects at unprecedented levels of resolution and fidelity, closely resembling those created by professional artists, and opening the door to more realistic generation of detailed 3D assets for animation, gaming, and virtual environments.
Edify 3D: Scalable High-Quality 3D Asset Generation
Nov 11, 2024
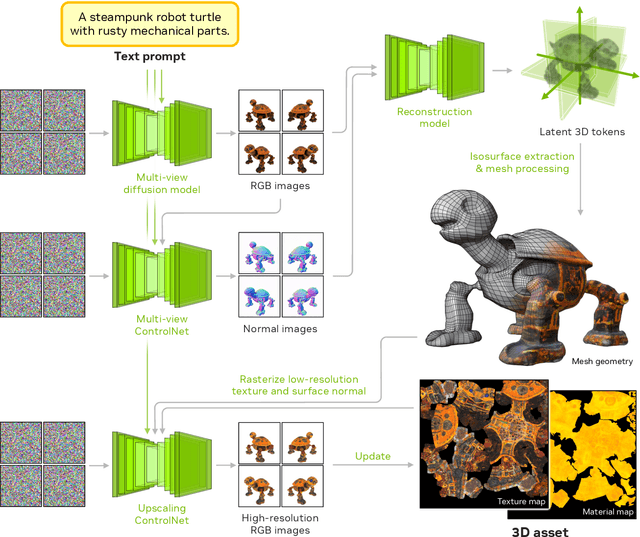

We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
EdgeRunner: Auto-regressive Auto-encoder for Artistic Mesh Generation
Sep 26, 2024



Current auto-regressive mesh generation methods suffer from issues such as incompleteness, insufficient detail, and poor generalization. In this paper, we propose an Auto-regressive Auto-encoder (ArAE) model capable of generating high-quality 3D meshes with up to 4,000 faces at a spatial resolution of $512^3$. We introduce a novel mesh tokenization algorithm that efficiently compresses triangular meshes into 1D token sequences, significantly enhancing training efficiency. Furthermore, our model compresses variable-length triangular meshes into a fixed-length latent space, enabling training latent diffusion models for better generalization. Extensive experiments demonstrate the superior quality, diversity, and generalization capabilities of our model in both point cloud and image-conditioned mesh generation tasks.
GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds
Apr 15, 2021

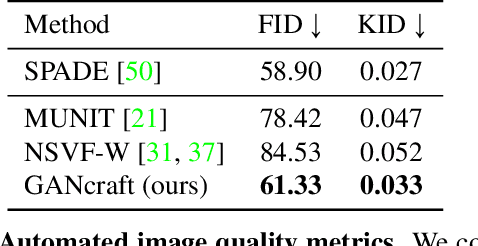
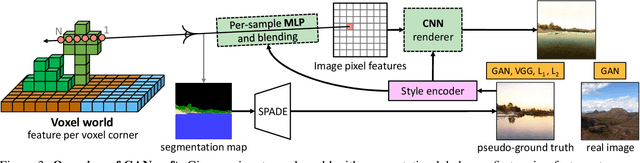
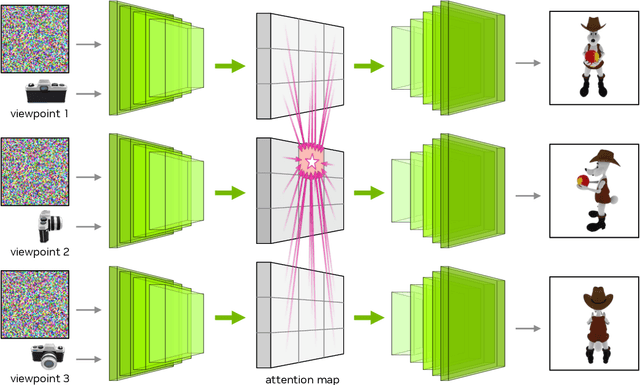
We present GANcraft, an unsupervised neural rendering framework for generating photorealistic images of large 3D block worlds such as those created in Minecraft. Our method takes a semantic block world as input, where each block is assigned a semantic label such as dirt, grass, or water. We represent the world as a continuous volumetric function and train our model to render view-consistent photorealistic images for a user-controlled camera. In the absence of paired ground truth real images for the block world, we devise a training technique based on pseudo-ground truth and adversarial training. This stands in contrast to prior work on neural rendering for view synthesis, which requires ground truth images to estimate scene geometry and view-dependent appearance. In addition to camera trajectory, GANcraft allows user control over both scene semantics and output style. Experimental results with comparison to strong baselines show the effectiveness of GANcraft on this novel task of photorealistic 3D block world synthesis. The project website is available at https://nvlabs.github.io/GANcraft/ .
Learning Gradient Fields for Shape Generation
Aug 18, 2020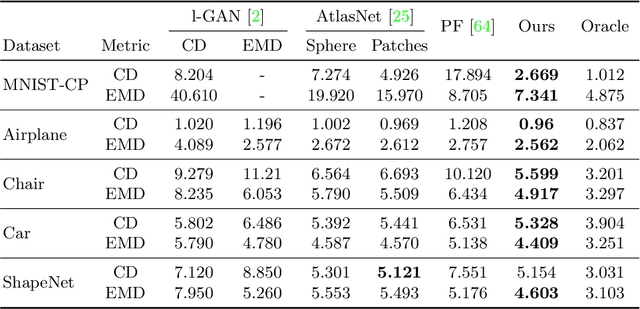
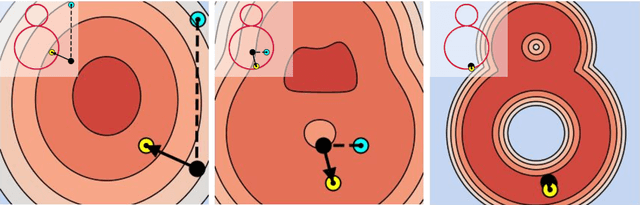
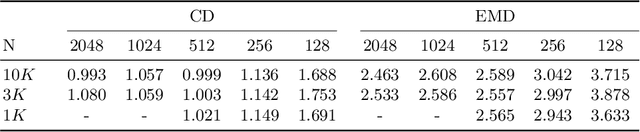
In this work, we propose a novel technique to generate shapes from point cloud data. A point cloud can be viewed as samples from a distribution of 3D points whose density is concentrated near the surface of the shape. Point cloud generation thus amounts to moving randomly sampled points to high-density areas. We generate point clouds by performing stochastic gradient ascent on an unnormalized probability density, thereby moving sampled points toward the high-likelihood regions. Our model directly predicts the gradient of the log density field and can be trained with a simple objective adapted from score-based generative models. We show that our method can reach state-of-the-art performance for point cloud auto-encoding and generation, while also allowing for extraction of a high-quality implicit surface. Code is available at https://github.com/RuojinCai/ShapeGF.
DualSDF: Semantic Shape Manipulation using a Two-Level Representation
Apr 06, 2020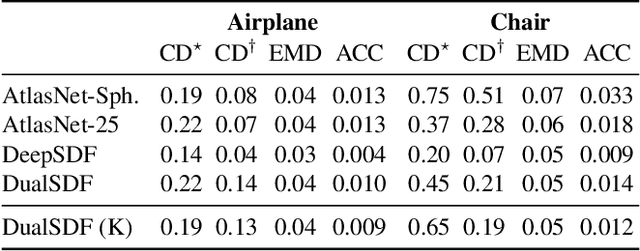
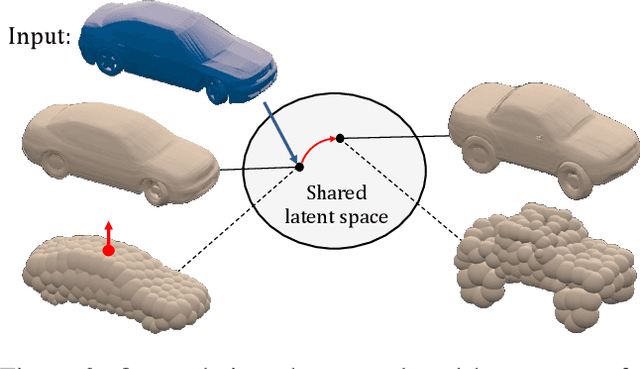
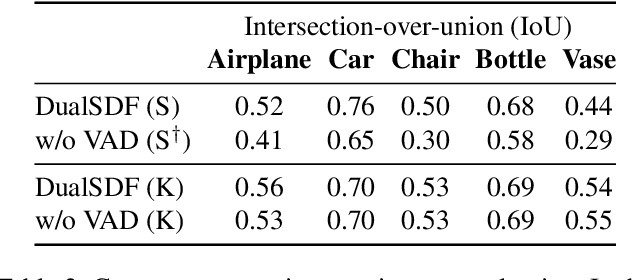
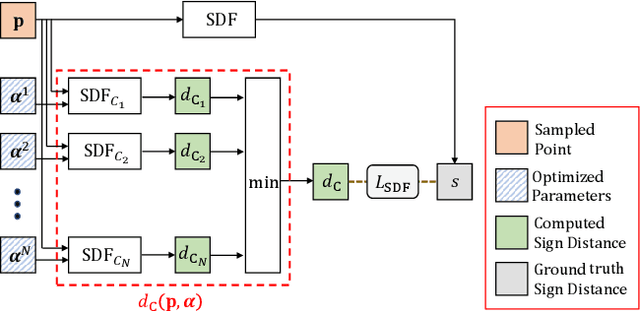
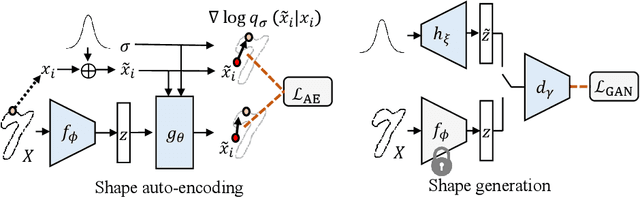
We are seeing a Cambrian explosion of 3D shape representations for use in machine learning. Some representations seek high expressive power in capturing high-resolution detail. Other approaches seek to represent shapes as compositions of simple parts, which are intuitive for people to understand and easy to edit and manipulate. However, it is difficult to achieve both fidelity and interpretability in the same representation. We propose DualSDF, a representation expressing shapes at two levels of granularity, one capturing fine details and the other representing an abstracted proxy shape using simple and semantically consistent shape primitives. To achieve a tight coupling between the two representations, we use a variational objective over a shared latent space. Our two-level model gives rise to a new shape manipulation technique in which a user can interactively manipulate the coarse proxy shape and see the changes instantly mirrored in the high-resolution shape. Moreover, our model actively augments and guides the manipulation towards producing semantically meaningful shapes, making complex manipulations possible with minimal user input.
PointFlow: 3D Point Cloud Generation with Continuous Normalizing Flows
Jul 01, 2019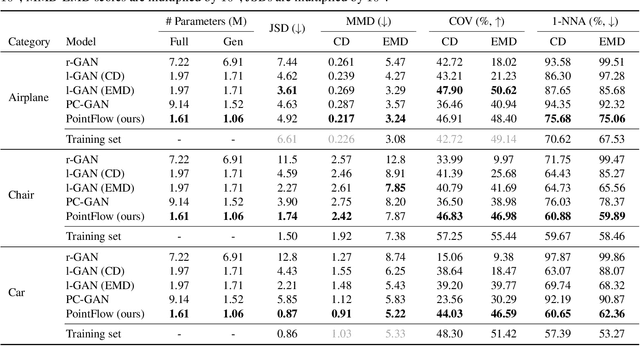
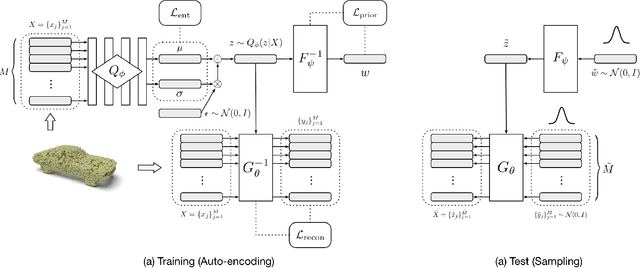
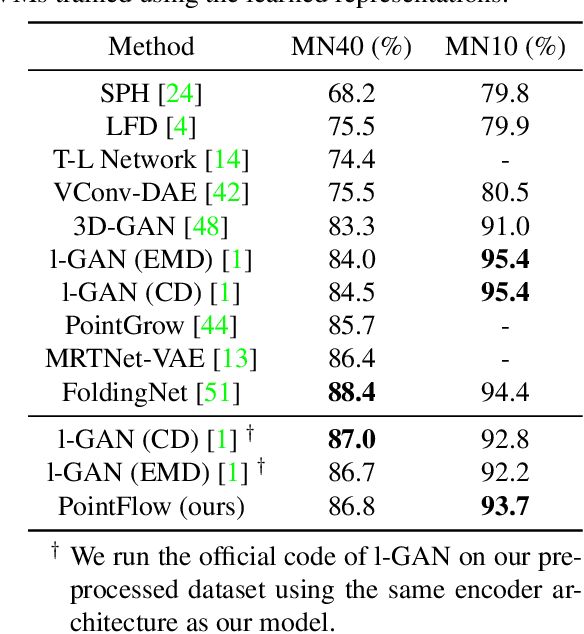
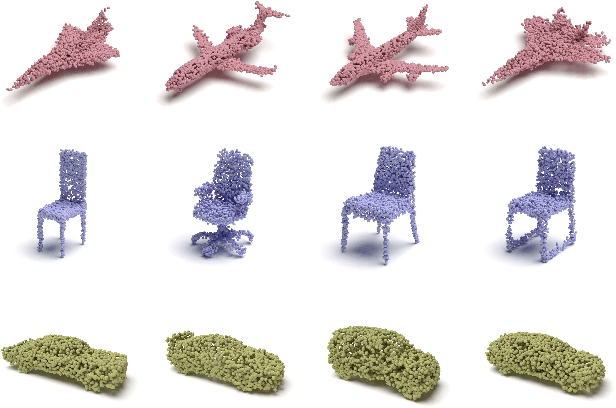
As 3D point clouds become the representation of choice for multiple vision and graphics applications, the ability to synthesize or reconstruct high-resolution, high-fidelity point clouds becomes crucial. Despite the recent success of deep learning models in discriminative tasks of point clouds, generating point clouds remains challenging. This paper proposes a principled probabilistic framework to generate 3D point clouds by modeling them as a distribution of distributions. Specifically, we learn a two-level hierarchy of distributions where the first level is the distribution of shapes and the second level is the distribution of points given a shape. This formulation allows us to both sample shapes and sample an arbitrary number of points from a shape. Our generative model, named PointFlow, learns each level of the distribution with a continuous normalizing flow. The invertibility of normalizing flows enables the computation of the likelihood during training and allows us to train our model in the variational inference framework. Empirically, we demonstrate that PointFlow achieves state-of-the-art performance in point cloud generation. We additionally show that our model can faithfully reconstruct point clouds and learn useful representations in an unsupervised manner. The code will be available at https://github.com/stevenygd/PointFlow.