 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneAligner: 3D-Grounded Floorplan Localization in the Wild
May 21, 2026Many public buildings provide floorplans with a "you are here" indicator to help visitors orient themselves. Floorplan localization seeks to computationally replicate this capability by determining where visual observations were captured within a floorplan. However, existing methods typically assume controlled small-scale environments and precise vectorized floorplans, limiting their ability to operate in large-scale buildings and rasterized floorplans. In this work, we present an approach for performing floorplan localization in the wild by grounding the task in a reconstructed 3D representation of the scene. Given an unconstrained image collection, our method reconstructs a gravity-aligned 3D scene and projects it into a 2D density map that serves as a floorplan proxy. Floorplan localization is then formulated as aligning this proxy with the input floorplan via a 2D similarity transform. To bridge the appearance gap between density maps and architectural floorplans, we adapt a 2D foundation model to learn cross-modal correspondences, introducing a fine-tuning scheme that encourages semantically aligned matches while preserving structural consistency. Extensive experiments demonstrate substantial improvements over prior methods, including in extremely sparse settings with as little as a single input image. Our code and data will be publicly available.
ArchSym: Detecting 3D-Grounded Architectural Symmetries in the Wild
Apr 24, 2026Symmetry detection is a fundamental problem in computer vision, and symmetries serve as powerful priors for downstream tasks. However, existing learning-based methods for detecting 3D symmetries from single images have been almost exclusively trained and evaluated on object-centric or synthetic datasets, and thus fail to generalize to real-world scenes. Furthermore, due to the inherent scale ambiguity of monocular inputs, which makes localizing the 3D plane an ill-posed problem, many existing works only predict the plane's orientation. In this paper, we address these limitations by presenting the first framework for detecting 3D-grounded reflectional symmetries from single, in-the-wild RGB images, focusing on architectural landmarks. We introduce two key innovations: (1) a scalable data annotation pipeline to automatically curate a large-scale dataset of architectural symmetries, ArchSym, from SfM reconstructions by leveraging cross-view image matching; and building on the dataset, (2) a single-view symmetry detector that accurately localizes symmetries in 3D by parameterizing them as signed distance maps defined relative to predicted scene geometry. We validate our symmetry annotation pipeline against geometry-based alternatives and demonstrate that our symmetry detector significantly outperforms state-of-the-art baselines on our new benchmark.
Long-tail Internet photo reconstruction
Apr 24, 2026Internet photo collections exhibit an extremely long-tailed distribution: a few famous landmarks are densely photographed and easily reconstructed in 3D, while most real-world sites are represented with sparse, noisy, uneven imagery beyond the capabilities of both classical and learned 3D methods. We believe that tackling this long-tail regime represents one of the next frontiers for 3D foundation models. Although reliable ground-truth 3D supervision from sparse scenes is challenging to acquire, we observe that it can be effectively simulated by sampling sparse subsets from well-reconstructed Internet landmarks. To this end, we introduce MegaDepth-X, a large dataset of 3D reconstructions with clean, dense depth, together with a strategy for sampling sets of training images that mimic camera distributions in long-tail scenes. Finetuning 3D foundation models with these components yields robust reconstructions under extreme sparsity, and also enables more reliable reconstruction in symmetric and repetitive scenes, while preserving generalization to standard, dense 3D benchmark datasets.
Can Generative Video Models Help Pose Estimation?
Dec 20, 2024Pairwise pose estimation from images with little or no overlap is an open challenge in computer vision. Existing methods, even those trained on large-scale datasets, struggle in these scenarios due to the lack of identifiable correspondences or visual overlap. Inspired by the human ability to infer spatial relationships from diverse scenes, we propose a novel approach, InterPose, that leverages the rich priors encoded within pre-trained generative video models. We propose to use a video model to hallucinate intermediate frames between two input images, effectively creating a dense, visual transition, which significantly simplifies the problem of pose estimation. Since current video models can still produce implausible motion or inconsistent geometry, we introduce a self-consistency score that evaluates the consistency of pose predictions from sampled videos. We demonstrate that our approach generalizes among three state-of-the-art video models and show consistent improvements over the state-of-the-art DUSt3R on four diverse datasets encompassing indoor, outdoor, and object-centric scenes. Our findings suggest a promising avenue for improving pose estimation models by leveraging large generative models trained on vast amounts of video data, which is more readily available than 3D data. See our project page for results: https://inter-pose.github.io/.
Doppelgangers++: Improved Visual Disambiguation with Geometric 3D Features
Dec 08, 2024



Accurate 3D reconstruction is frequently hindered by visual aliasing, where visually similar but distinct surfaces (aka, doppelgangers), are incorrectly matched. These spurious matches distort the structure-from-motion (SfM) process, leading to misplaced model elements and reduced accuracy. Prior efforts addressed this with CNN classifiers trained on curated datasets, but these approaches struggle to generalize across diverse real-world scenes and can require extensive parameter tuning. In this work, we present Doppelgangers++, a method to enhance doppelganger detection and improve 3D reconstruction accuracy. Our contributions include a diversified training dataset that incorporates geo-tagged images from everyday scenes to expand robustness beyond landmark-based datasets. We further propose a Transformer-based classifier that leverages 3D-aware features from the MASt3R model, achieving superior precision and recall across both in-domain and out-of-domain tests. Doppelgangers++ integrates seamlessly into standard SfM and MASt3R-SfM pipelines, offering efficiency and adaptability across varied scenes. To evaluate SfM accuracy, we introduce an automated, geotag-based method for validating reconstructed models, eliminating the need for manual inspection. Through extensive experiments, we demonstrate that Doppelgangers++ significantly enhances pairwise visual disambiguation and improves 3D reconstruction quality in complex and diverse scenarios.
Extreme Rotation Estimation in the Wild
Nov 12, 2024We present a technique and benchmark dataset for estimating the relative 3D orientation between a pair of Internet images captured in an extreme setting, where the images have limited or non-overlapping field of views. Prior work targeting extreme rotation estimation assume constrained 3D environments and emulate perspective images by cropping regions from panoramic views. However, real images captured in the wild are highly diverse, exhibiting variation in both appearance and camera intrinsics. In this work, we propose a Transformer-based method for estimating relative rotations in extreme real-world settings, and contribute the ExtremeLandmarkPairs dataset, assembled from scene-level Internet photo collections. Our evaluation demonstrates that our approach succeeds in estimating the relative rotations in a wide variety of extreme-view Internet image pairs, outperforming various baselines, including dedicated rotation estimation techniques and contemporary 3D reconstruction methods.
MegaScenes: Scene-Level View Synthesis at Scale
Jun 17, 2024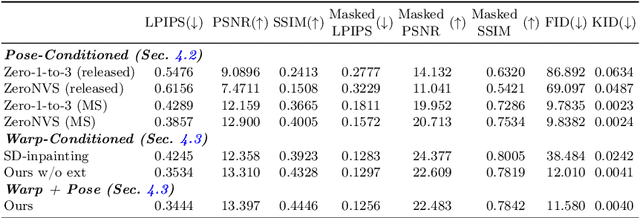
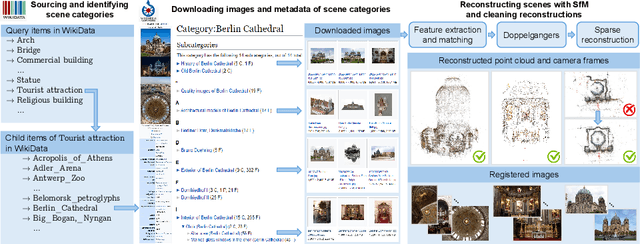
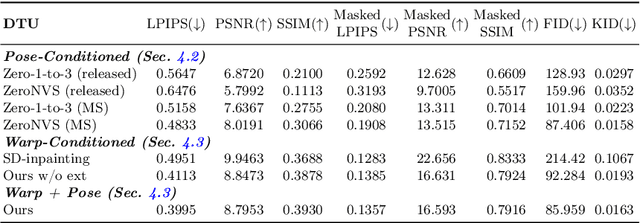
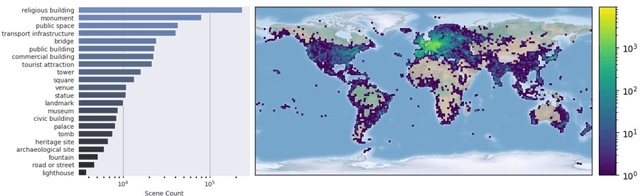
Scene-level novel view synthesis (NVS) is fundamental to many vision and graphics applications. Recently, pose-conditioned diffusion models have led to significant progress by extracting 3D information from 2D foundation models, but these methods are limited by the lack of scene-level training data. Common dataset choices either consist of isolated objects (Objaverse), or of object-centric scenes with limited pose distributions (DTU, CO3D). In this paper, we create a large-scale scene-level dataset from Internet photo collections, called MegaScenes, which contains over 100K structure from motion (SfM) reconstructions from around the world. Internet photos represent a scalable data source but come with challenges such as lighting and transient objects. We address these issues to further create a subset suitable for the task of NVS. Additionally, we analyze failure cases of state-of-the-art NVS methods and significantly improve generation consistency. Through extensive experiments, we validate the effectiveness of both our dataset and method on generating in-the-wild scenes. For details on the dataset and code, see our project page at https://megascenes.github.io .
Doppelgangers: Learning to Disambiguate Images of Similar Structures
Sep 05, 2023We consider the visual disambiguation task of determining whether a pair of visually similar images depict the same or distinct 3D surfaces (e.g., the same or opposite sides of a symmetric building). Illusory image matches, where two images observe distinct but visually similar 3D surfaces, can be challenging for humans to differentiate, and can also lead 3D reconstruction algorithms to produce erroneous results. We propose a learning-based approach to visual disambiguation, formulating it as a binary classification task on image pairs. To that end, we introduce a new dataset for this problem, Doppelgangers, which includes image pairs of similar structures with ground truth labels. We also design a network architecture that takes the spatial distribution of local keypoints and matches as input, allowing for better reasoning about both local and global cues. Our evaluation shows that our method can distinguish illusory matches in difficult cases, and can be integrated into SfM pipelines to produce correct, disambiguated 3D reconstructions. See our project page for our code, datasets, and more results: http://doppelgangers-3d.github.io/.
Neural Scene Chronology
Jun 13, 2023



In this work, we aim to reconstruct a time-varying 3D model, capable of rendering photo-realistic renderings with independent control of viewpoint, illumination, and time, from Internet photos of large-scale landmarks. The core challenges are twofold. First, different types of temporal changes, such as illumination and changes to the underlying scene itself (such as replacing one graffiti artwork with another) are entangled together in the imagery. Second, scene-level temporal changes are often discrete and sporadic over time, rather than continuous. To tackle these problems, we propose a new scene representation equipped with a novel temporal step function encoding method that can model discrete scene-level content changes as piece-wise constant functions over time. Specifically, we represent the scene as a space-time radiance field with a per-image illumination embedding, where temporally-varying scene changes are encoded using a set of learned step functions. To facilitate our task of chronology reconstruction from Internet imagery, we also collect a new dataset of four scenes that exhibit various changes over time. We demonstrate that our method exhibits state-of-the-art view synthesis results on this dataset, while achieving independent control of viewpoint, time, and illumination.
Tracking Everything Everywhere All at Once
Jun 08, 2023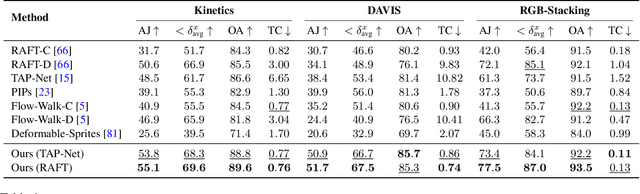
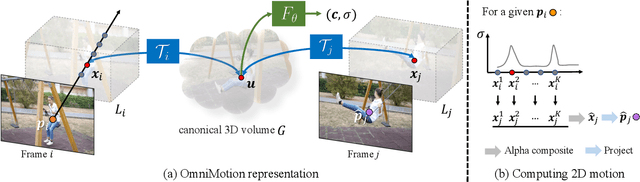
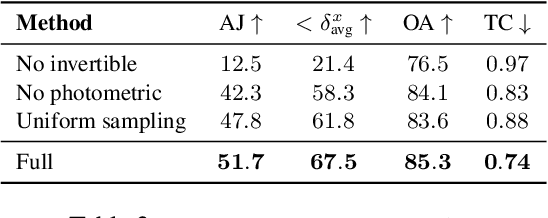

We present a new test-time optimization method for estimating dense and long-range motion from a video sequence. Prior optical flow or particle video tracking algorithms typically operate within limited temporal windows, struggling to track through occlusions and maintain global consistency of estimated motion trajectories. We propose a complete and globally consistent motion representation, dubbed OmniMotion, that allows for accurate, full-length motion estimation of every pixel in a video. OmniMotion represents a video using a quasi-3D canonical volume and performs pixel-wise tracking via bijections between local and canonical space. This representation allows us to ensure global consistency, track through occlusions, and model any combination of camera and object motion. Extensive evaluations on the TAP-Vid benchmark and real-world footage show that our approach outperforms prior state-of-the-art methods by a large margin both quantitatively and qualitatively. See our project page for more results: http://omnimotion.github.io/