 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Camera Poses and Where to Find Them
Apr 24, 2025Annotating camera poses on dynamic Internet videos at scale is critical for advancing fields like realistic video generation and simulation. However, collecting such a dataset is difficult, as most Internet videos are unsuitable for pose estimation. Furthermore, annotating dynamic Internet videos present significant challenges even for state-of-theart methods. In this paper, we introduce DynPose-100K, a large-scale dataset of dynamic Internet videos annotated with camera poses. Our collection pipeline addresses filtering using a carefully combined set of task-specific and generalist models. For pose estimation, we combine the latest techniques of point tracking, dynamic masking, and structure-from-motion to achieve improvements over the state-of-the-art approaches. Our analysis and experiments demonstrate that DynPose-100K is both large-scale and diverse across several key attributes, opening up avenues for advancements in various downstream applications.
MegaScenes: Scene-Level View Synthesis at Scale
Jun 17, 2024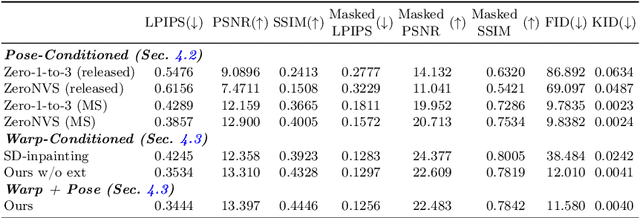
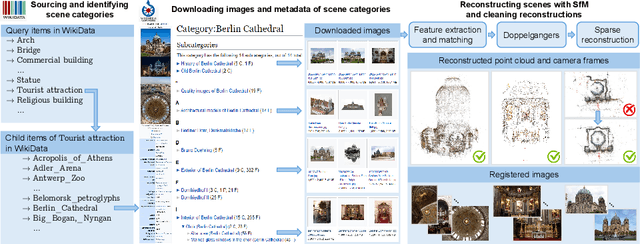
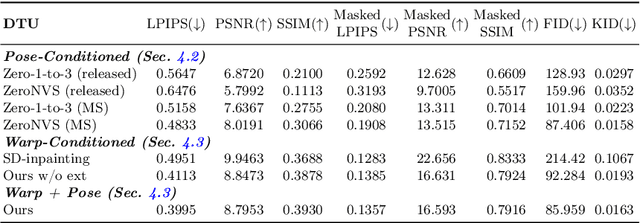
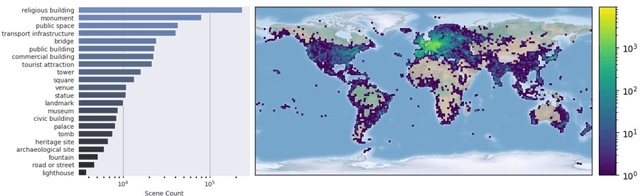
Scene-level novel view synthesis (NVS) is fundamental to many vision and graphics applications. Recently, pose-conditioned diffusion models have led to significant progress by extracting 3D information from 2D foundation models, but these methods are limited by the lack of scene-level training data. Common dataset choices either consist of isolated objects (Objaverse), or of object-centric scenes with limited pose distributions (DTU, CO3D). In this paper, we create a large-scale scene-level dataset from Internet photo collections, called MegaScenes, which contains over 100K structure from motion (SfM) reconstructions from around the world. Internet photos represent a scalable data source but come with challenges such as lighting and transient objects. We address these issues to further create a subset suitable for the task of NVS. Additionally, we analyze failure cases of state-of-the-art NVS methods and significantly improve generation consistency. Through extensive experiments, we validate the effectiveness of both our dataset and method on generating in-the-wild scenes. For details on the dataset and code, see our project page at https://megascenes.github.io .
Doppelgangers: Learning to Disambiguate Images of Similar Structures
Sep 05, 2023We consider the visual disambiguation task of determining whether a pair of visually similar images depict the same or distinct 3D surfaces (e.g., the same or opposite sides of a symmetric building). Illusory image matches, where two images observe distinct but visually similar 3D surfaces, can be challenging for humans to differentiate, and can also lead 3D reconstruction algorithms to produce erroneous results. We propose a learning-based approach to visual disambiguation, formulating it as a binary classification task on image pairs. To that end, we introduce a new dataset for this problem, Doppelgangers, which includes image pairs of similar structures with ground truth labels. We also design a network architecture that takes the spatial distribution of local keypoints and matches as input, allowing for better reasoning about both local and global cues. Our evaluation shows that our method can distinguish illusory matches in difficult cases, and can be integrated into SfM pipelines to produce correct, disambiguated 3D reconstructions. See our project page for our code, datasets, and more results: http://doppelgangers-3d.github.io/.