 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashDepth: Real-time Streaming Video Depth Estimation at 2K Resolution
Apr 09, 2025A versatile video depth estimation model should (1) be accurate and consistent across frames, (2) produce high-resolution depth maps, and (3) support real-time streaming. We propose FlashDepth, a method that satisfies all three requirements, performing depth estimation on a 2044x1148 streaming video at 24 FPS. We show that, with careful modifications to pretrained single-image depth models, these capabilities are enabled with relatively little data and training. We evaluate our approach across multiple unseen datasets against state-of-the-art depth models, and find that ours outperforms them in terms of boundary sharpness and speed by a significant margin, while maintaining competitive accuracy. We hope our model will enable various applications that require high-resolution depth, such as video editing, and online decision-making, such as robotics.
Generating 3D-Consistent Videos from Unposed Internet Photos
Nov 20, 2024



We address the problem of generating videos from unposed internet photos. A handful of input images serve as keyframes, and our model interpolates between them to simulate a path moving between the cameras. Given random images, a model's ability to capture underlying geometry, recognize scene identity, and relate frames in terms of camera position and orientation reflects a fundamental understanding of 3D structure and scene layout. However, existing video models such as Luma Dream Machine fail at this task. We design a self-supervised method that takes advantage of the consistency of videos and variability of multiview internet photos to train a scalable, 3D-aware video model without any 3D annotations such as camera parameters. We validate that our method outperforms all baselines in terms of geometric and appearance consistency. We also show our model benefits applications that enable camera control, such as 3D Gaussian Splatting. Our results suggest that we can scale up scene-level 3D learning using only 2D data such as videos and multiview internet photos.
MegaScenes: Scene-Level View Synthesis at Scale
Jun 17, 2024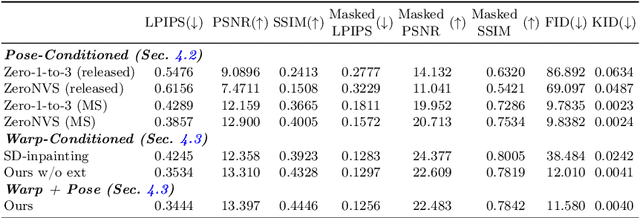
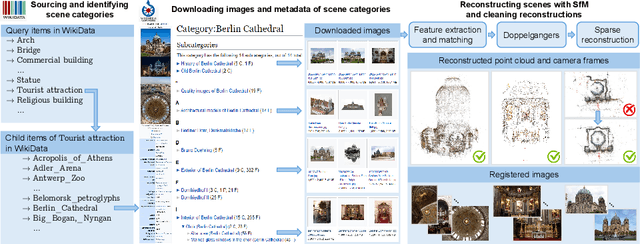
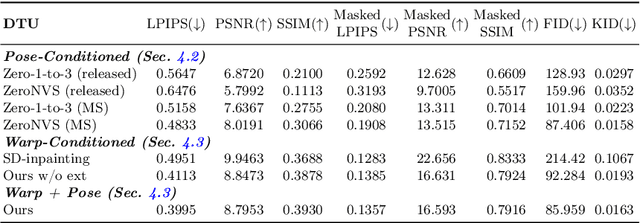
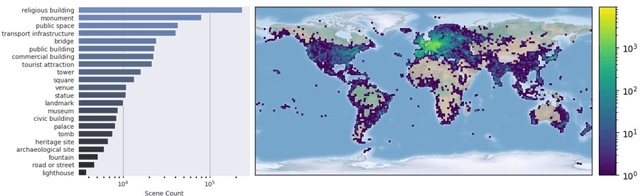
Scene-level novel view synthesis (NVS) is fundamental to many vision and graphics applications. Recently, pose-conditioned diffusion models have led to significant progress by extracting 3D information from 2D foundation models, but these methods are limited by the lack of scene-level training data. Common dataset choices either consist of isolated objects (Objaverse), or of object-centric scenes with limited pose distributions (DTU, CO3D). In this paper, we create a large-scale scene-level dataset from Internet photo collections, called MegaScenes, which contains over 100K structure from motion (SfM) reconstructions from around the world. Internet photos represent a scalable data source but come with challenges such as lighting and transient objects. We address these issues to further create a subset suitable for the task of NVS. Additionally, we analyze failure cases of state-of-the-art NVS methods and significantly improve generation consistency. Through extensive experiments, we validate the effectiveness of both our dataset and method on generating in-the-wild scenes. For details on the dataset and code, see our project page at https://megascenes.github.io .
YOLOR-Based Multi-Task Learning
Sep 29, 2023

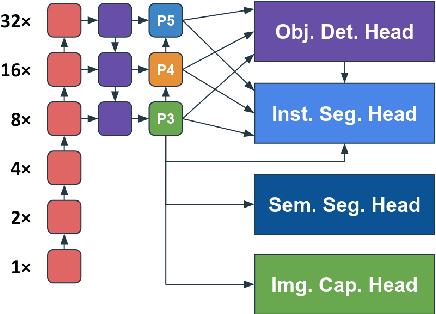

Multi-task learning (MTL) aims to learn multiple tasks using a single model and jointly improve all of them assuming generalization and shared semantics. Reducing conflicts between tasks during joint learning is difficult and generally requires careful network design and extremely large models. We propose building on You Only Learn One Representation (YOLOR), a network architecture specifically designed for multitasking. YOLOR leverages both explicit and implicit knowledge, from data observations and learned latents, respectively, to improve a shared representation while minimizing the number of training parameters. However, YOLOR and its follow-up, YOLOv7, only trained two tasks at once. In this paper, we jointly train object detection, instance segmentation, semantic segmentation, and image captioning. We analyze tradeoffs and attempt to maximize sharing of semantic information. Through our architecture and training strategies, we find that our method achieves competitive performance on all tasks while maintaining a low parameter count and without any pre-training. We will release code soon.
Thin On-Sensor Nanophotonic Array Cameras
Aug 05, 2023

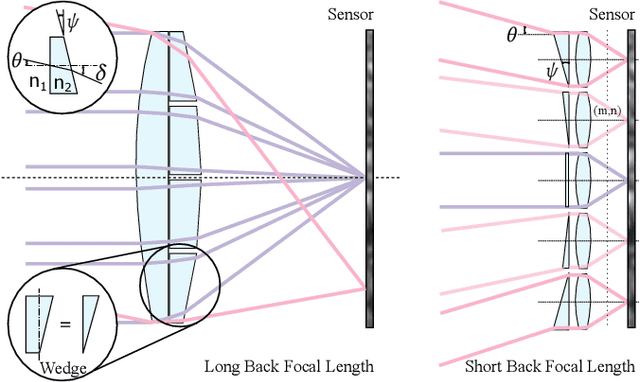
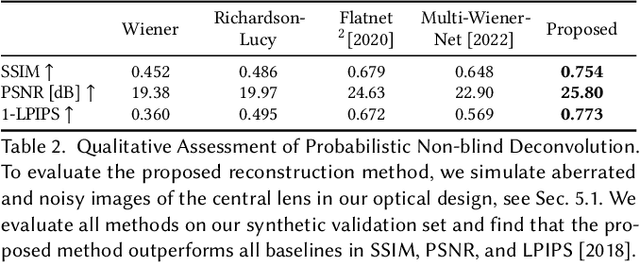
Today's commodity camera systems rely on compound optics to map light originating from the scene to positions on the sensor where it gets recorded as an image. To record images without optical aberrations, i.e., deviations from Gauss' linear model of optics, typical lens systems introduce increasingly complex stacks of optical elements which are responsible for the height of existing commodity cameras. In this work, we investigate \emph{flat nanophotonic computational cameras} as an alternative that employs an array of skewed lenslets and a learned reconstruction approach. The optical array is embedded on a metasurface that, at 700~nm height, is flat and sits on the sensor cover glass at 2.5~mm focal distance from the sensor. To tackle the highly chromatic response of a metasurface and design the array over the entire sensor, we propose a differentiable optimization method that continuously samples over the visible spectrum and factorizes the optical modulation for different incident fields into individual lenses. We reconstruct a megapixel image from our flat imager with a \emph{learned probabilistic reconstruction} method that employs a generative diffusion model to sample an implicit prior. To tackle \emph{scene-dependent aberrations in broadband}, we propose a method for acquiring paired captured training data in varying illumination conditions. We assess the proposed flat camera design in simulation and with an experimental prototype, validating that the method is capable of recovering images from diverse scenes in broadband with a single nanophotonic layer.
DiffusionSDF: Conditional Generative Modeling of Signed Distance Functions
Nov 24, 2022
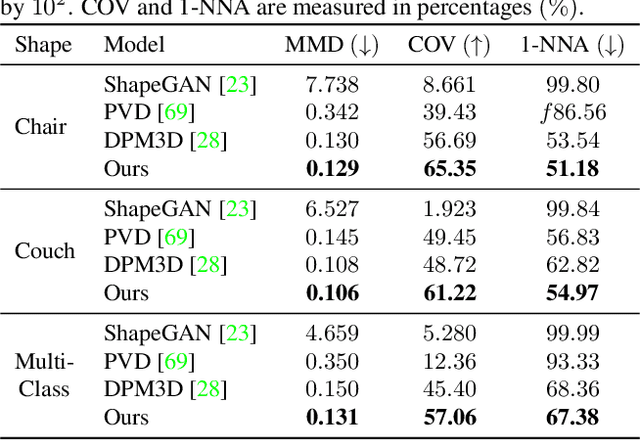

Probabilistic diffusion models have achieved state-of-the-art results for image synthesis, inpainting, and text-to-image tasks. However, they are still in the early stages of generating complex 3D shapes. This work proposes DiffusionSDF, a generative model for shape completion, single-view reconstruction, and reconstruction of real-scanned point clouds. We use neural signed distance functions (SDFs) as our 3D representation to parameterize the geometry of various signals (e.g., point clouds, 2D images) through neural networks. Neural SDFs are implicit functions and diffusing them amounts to learning the reversal of their neural network weights, which we solve using a custom modulation module. Extensive experiments show that our method is capable of both realistic unconditional generation and conditional generation from partial inputs. This work expands the domain of diffusion models from learning 2D, explicit representations, to 3D, implicit representations.
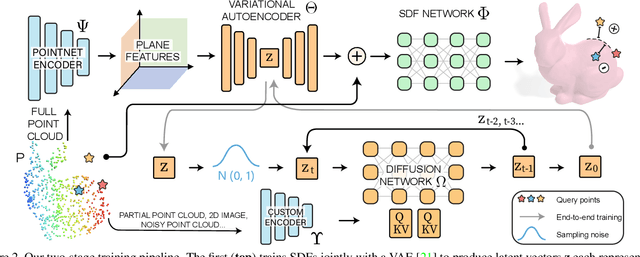
GenSDF: Two-Stage Learning of Generalizable Signed Distance Functions
Jun 06, 2022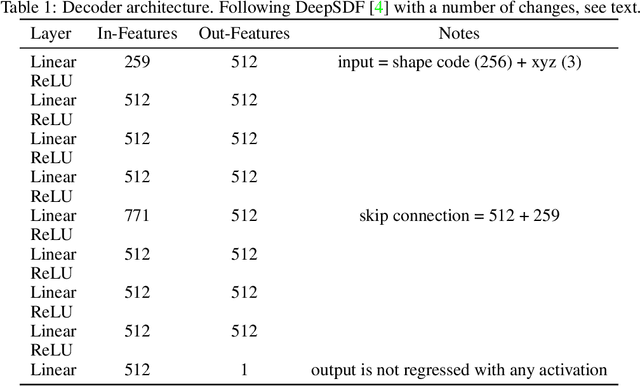
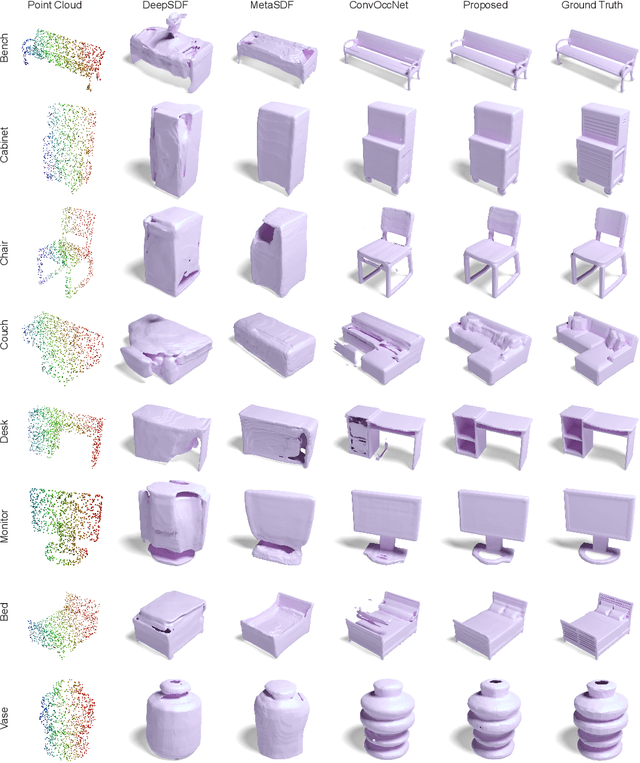
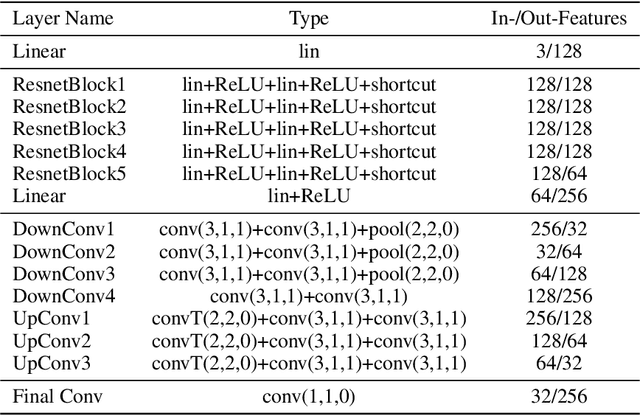

We investigate the generalization capabilities of neural signed distance functions (SDFs) for learning 3D object representations for unseen and unlabeled point clouds. Existing methods can fit SDFs to a handful of object classes and boast fine detail or fast inference speeds, but do not generalize well to unseen shapes. We introduce a two-stage semi-supervised meta-learning approach that transfers shape priors from labeled to unlabeled data to reconstruct unseen object categories. The first stage uses an episodic training scheme to simulate training on unlabeled data and meta-learns initial shape priors. The second stage then introduces unlabeled data with disjoint classes in a semi-supervised scheme to diversify these priors and achieve generalization. We assess our method on both synthetic data and real collected point clouds. Experimental results and analysis validate that our approach outperforms existing neural SDF methods and is capable of robust zero-shot inference on 100+ unseen classes. Code can be found at https://github.com/princeton-computational-imaging/gensdf.