 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLOR-Based Multi-Task Learning
Paper and Code
Sep 29, 2023

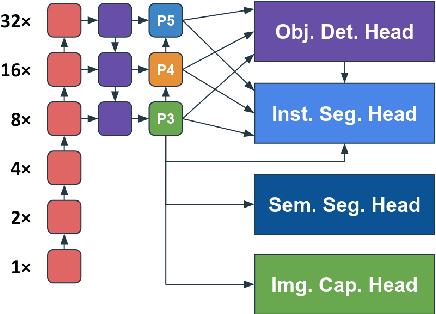

Multi-task learning (MTL) aims to learn multiple tasks using a single model and jointly improve all of them assuming generalization and shared semantics. Reducing conflicts between tasks during joint learning is difficult and generally requires careful network design and extremely large models. We propose building on You Only Learn One Representation (YOLOR), a network architecture specifically designed for multitasking. YOLOR leverages both explicit and implicit knowledge, from data observations and learned latents, respectively, to improve a shared representation while minimizing the number of training parameters. However, YOLOR and its follow-up, YOLOv7, only trained two tasks at once. In this paper, we jointly train object detection, instance segmentation, semantic segmentation, and image captioning. We analyze tradeoffs and attempt to maximize sharing of semantic information. Through our architecture and training strategies, we find that our method achieves competitive performance on all tasks while maintaining a low parameter count and without any pre-training. We will release code soon.