 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universal Action Space for General Behavior Analysis
Feb 10, 2026Analyzing animal and human behavior has long been a challenging task in computer vision. Early approaches from the 1970s to the 1990s relied on hand-crafted edge detection, segmentation, and low-level features such as color, shape, and texture to locate objects and infer their identities-an inherently ill-posed problem. Behavior analysis in this era typically proceeded by tracking identified objects over time and modeling their trajectories using sparse feature points, which further limited robustness and generalization. A major shift occurred with the introduction of ImageNet by Deng and Li in 2010, which enabled large-scale visual recognition through deep neural networks and effectively served as a comprehensive visual dictionary. This development allowed object recognition to move beyond complex low-level processing toward learned high-level representations. In this work, we follow this paradigm to build a large-scale Universal Action Space (UAS) using existing labeled human-action datasets. We then use this UAS as the foundation for analyzing and categorizing mammalian and chimpanzee behavior datasets. The source code is released on GitHub at https://github.com/franktpmvu/Universal-Action-Space.
YOLOR-Based Multi-Task Learning
Sep 29, 2023

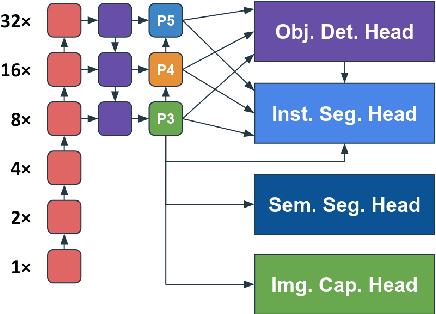

Multi-task learning (MTL) aims to learn multiple tasks using a single model and jointly improve all of them assuming generalization and shared semantics. Reducing conflicts between tasks during joint learning is difficult and generally requires careful network design and extremely large models. We propose building on You Only Learn One Representation (YOLOR), a network architecture specifically designed for multitasking. YOLOR leverages both explicit and implicit knowledge, from data observations and learned latents, respectively, to improve a shared representation while minimizing the number of training parameters. However, YOLOR and its follow-up, YOLOv7, only trained two tasks at once. In this paper, we jointly train object detection, instance segmentation, semantic segmentation, and image captioning. We analyze tradeoffs and attempt to maximize sharing of semantic information. Through our architecture and training strategies, we find that our method achieves competitive performance on all tasks while maintaining a low parameter count and without any pre-training. We will release code soon.
NeighborTrack: Improving Single Object Tracking by Bipartite Matching with Neighbor Tracklets
Nov 12, 2022We propose a post-processor, called NeighborTrack, that leverages neighbor information of the tracking target to validate and improve single-object tracking (SOT) results. It requires no additional data or retraining. Instead, it uses the confidence score predicted by the backbone SOT network to automatically derive neighbor information and then uses this information to improve the tracking results. When tracking an occluded target, its appearance features are untrustworthy. However, a general siamese network often cannot tell whether the tracked object is occluded by reading the confidence score alone, because it could be misled by neighbors with high confidence scores. Our proposed NeighborTrack takes advantage of unoccluded neighbors' information to reconfirm the tracking target and reduces false tracking when the target is occluded. It not only reduces the impact caused by occlusion, but also fixes tracking problems caused by object appearance changes. NeighborTrack is agnostic to SOT networks and post-processing methods. For the VOT challenge dataset commonly used in short-term object tracking, we improve three famous SOT networks, Ocean, TransT, and OSTrack, by an average of ${1.92\%}$ EAO and ${2.11\%}$ robustness. For the mid- and long-term tracking experiments based on OSTrack, we achieve state-of-the-art ${72.25\%}$ AUC on LaSOT and ${75.7\%}$ AO on GOT-10K.