 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighborTrack: Improving Single Object Tracking by Bipartite Matching with Neighbor Tracklets
Nov 12, 2022We propose a post-processor, called NeighborTrack, that leverages neighbor information of the tracking target to validate and improve single-object tracking (SOT) results. It requires no additional data or retraining. Instead, it uses the confidence score predicted by the backbone SOT network to automatically derive neighbor information and then uses this information to improve the tracking results. When tracking an occluded target, its appearance features are untrustworthy. However, a general siamese network often cannot tell whether the tracked object is occluded by reading the confidence score alone, because it could be misled by neighbors with high confidence scores. Our proposed NeighborTrack takes advantage of unoccluded neighbors' information to reconfirm the tracking target and reduces false tracking when the target is occluded. It not only reduces the impact caused by occlusion, but also fixes tracking problems caused by object appearance changes. NeighborTrack is agnostic to SOT networks and post-processing methods. For the VOT challenge dataset commonly used in short-term object tracking, we improve three famous SOT networks, Ocean, TransT, and OSTrack, by an average of ${1.92\%}$ EAO and ${2.11\%}$ robustness. For the mid- and long-term tracking experiments based on OSTrack, we achieve state-of-the-art ${72.25\%}$ AUC on LaSOT and ${75.7\%}$ AO on GOT-10K.
SearchTrack: Multiple Object Tracking with Object-Customized Search and Motion-Aware Features
Oct 29, 2022



The paper presents a new method, SearchTrack, for multiple object tracking and segmentation (MOTS). To address the association problem between detected objects, SearchTrack proposes object-customized search and motion-aware features. By maintaining a Kalman filter for each object, we encode the predicted motion into the motion-aware feature, which includes both motion and appearance cues. For each object, a customized fully convolutional search engine is created by SearchTrack by learning a set of weights for dynamic convolutions specific to the object. Experiments demonstrate that our SearchTrack method outperforms competitive methods on both MOTS and MOT tasks, particularly in terms of association accuracy. Our method achieves 71.5 HOTA (car) and 57.6 HOTA (pedestrian) on the KITTI MOTS and 53.4 HOTA on MOT17. In terms of association accuracy, our method achieves state-of-the-art performance among 2D online methods on the KITTI MOTS. Our code is available at https://github.com/qa276390/SearchTrack.
HarDNet-DFUS: An Enhanced Harmonically-Connected Network for Diabetic Foot Ulcer Image Segmentation and Colonoscopy Polyp Segmentation
Sep 15, 2022



We present a neural network architecture for medical image segmentation of diabetic foot ulcers and colonoscopy polyps. Diabetic foot ulcers are caused by neuropathic and vascular complications of diabetes mellitus. In order to provide a proper diagnosis and treatment, wound care professionals need to extract accurate morphological features from the foot wounds. Using computer-aided systems is a promising approach to extract related morphological features and segment the lesions. We propose a convolution neural network called HarDNet-DFUS by enhancing the backbone and replacing the decoder of HarDNet-MSEG, which was SOTA for colonoscopy polyp segmentation in 2021. For the MICCAI 2022 Diabetic Foot Ulcer Segmentation Challenge (DFUC2022), we train HarDNet-DFUS using the DFUC2022 dataset and increase its robustness by means of five-fold cross validation, Test Time Augmentation, etc. In the validation phase of DFUC2022, HarDNet-DFUS achieved 0.7063 mean dice and was ranked third among all participants. In the final testing phase of DFUC2022, it achieved 0.7287 mean dice and was the first place winner. HarDNet-DFUS also deliver excellent performance for the colonoscopy polyp segmentation task. It achieves 0.924 mean Dice on the famous Kvasir dataset, an improvement of 1.2\% over the original HarDNet-MSEG. The codes are available on https://github.com/kytimmylai/DFUC2022 (for Diabetic Foot Ulcers Segmentation) and https://github.com/YuWenLo/HarDNet-DFUS (for Colonoscopy Polyp Segmentation).
HarDNet-MSEG: A Simple Encoder-Decoder Polyp Segmentation Neural Network that Achieves over 0.9 Mean Dice and 86 FPS
Jan 20, 2021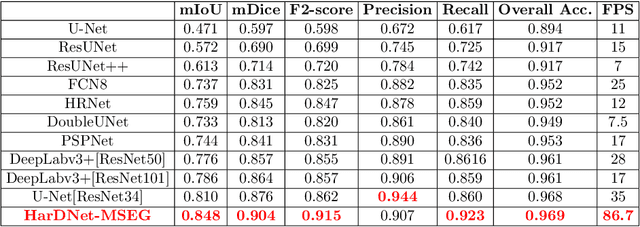
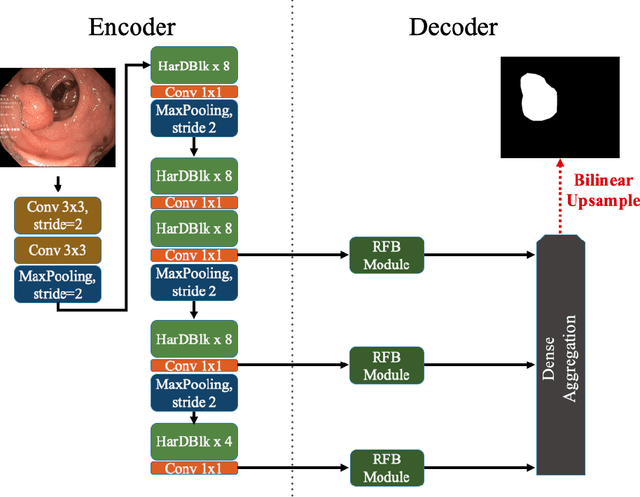
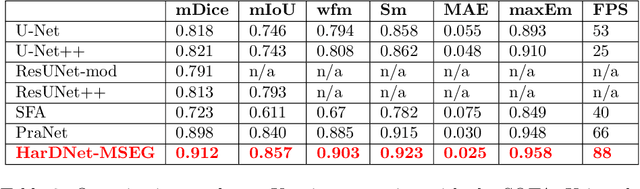
We propose a new convolution neural network called HarDNet-MSEG for polyp segmentation. It achieves SOTA in both accuracy and inference speed on five popular datasets. For Kvasir-SEG, HarDNet-MSEG delivers 0.904 mean Dice running at 86.7 FPS on a GeForce RTX 2080 Ti GPU. It consists of a backbone and a decoder. The backbone is a low memory traffic CNN called HarDNet68, which has been successfully applied to various CV tasks including image classification, object detection, multi-object tracking and semantic segmentation, etc. The decoder part is inspired by the Cascaded Partial Decoder, known for fast and accurate salient object detection. We have evaluated HarDNet-MSEG using those five popular datasets. The code and all experiment details are available at Github. https://github.com/james128333/HarDNet-MSEG
RNNAccel: A Fusion Recurrent Neural Network Accelerator for Edge Intelligence
Oct 26, 2020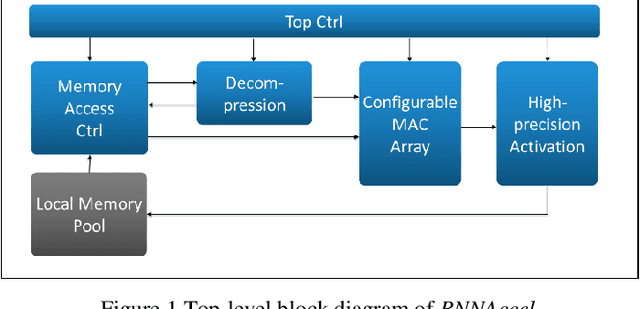
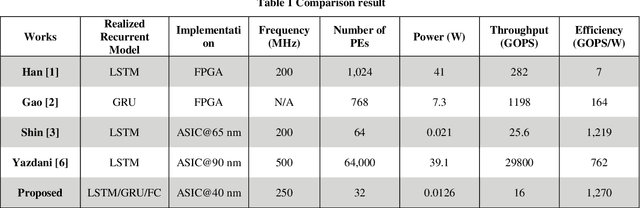
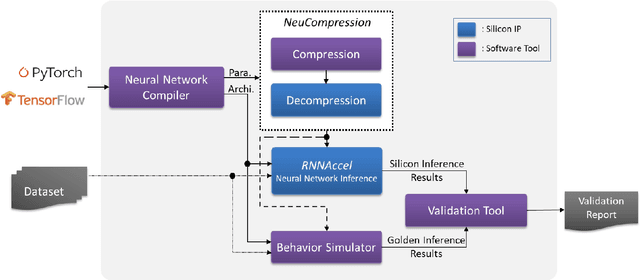
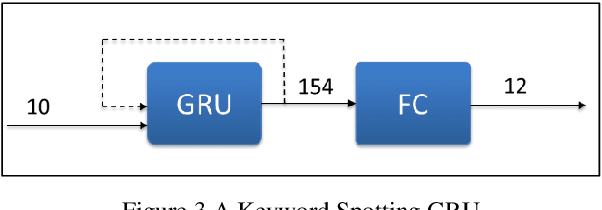
Many edge devices employ Recurrent Neural Networks (RNN) to enhance their product intelligence. However, the increasing computation complexity poses challenges for performance, energy efficiency and product development time. In this paper, we present an RNN deep learning accelerator, called RNNAccel, which supports Long Short-Term Memory (LSTM) network, Gated Recurrent Unit (GRU) network, and Fully Connected Layer (FC)/ Multiple-Perceptron Layer (MLP) networks. This RNN accelerator addresses (1) computing unit utilization bottleneck caused by RNN data dependency, (2) inflexible design for specific applications, (3) energy consumption dominated by memory access, (4) accuracy loss due to coefficient compression, and (5) unpredictable performance resulting from processor-accelerator integration. Our proposed RNN accelerator consists of a configurable 32-MAC array and a coefficient decompression engine. The MAC array can be scaled-up to meet throughput requirement and power budget. Its sophisticated off-line compression and simple hardware-friendly on-line decompression, called NeuCompression, reduces memory footprint up to 16x and decreases memory access power. Furthermore, for easy SOC integration, we developed a tool set for bit-accurate simulation and integration result validation. Evaluated using a keyword spotting application, the 32-MAC RNN accelerator achieves 90% MAC utilization, 1.27 TOPs/W at 40nm process, 8x compression ratio, and 90% inference accuracy.
HarDNet: A Low Memory Traffic Network
Sep 03, 2019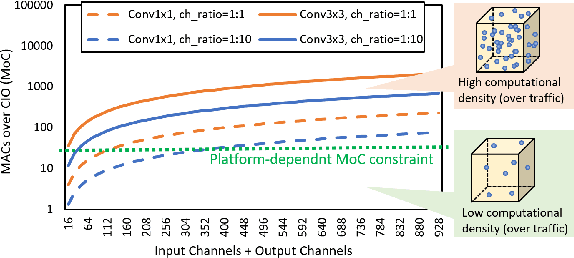
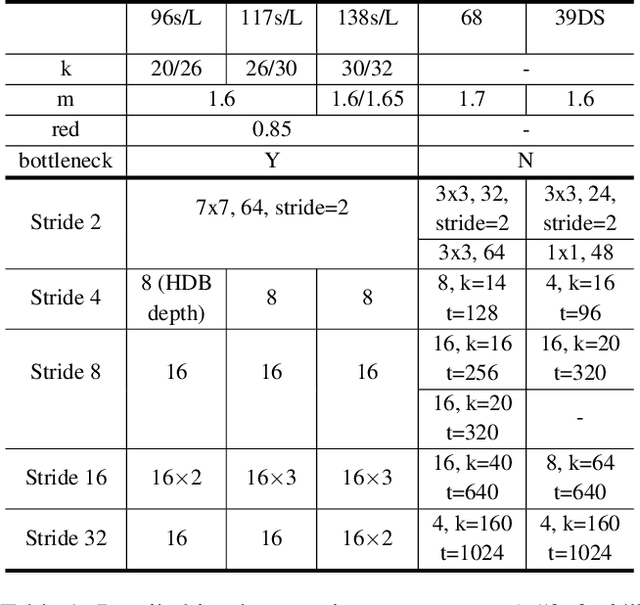
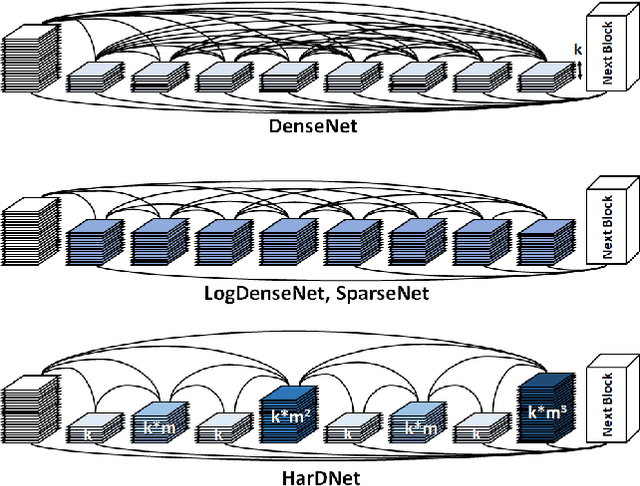
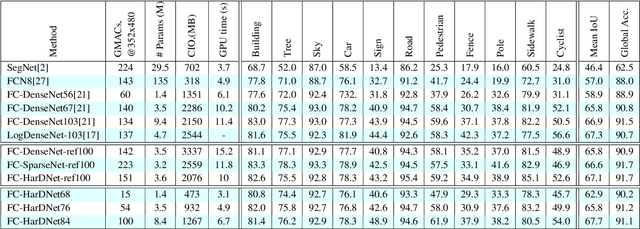
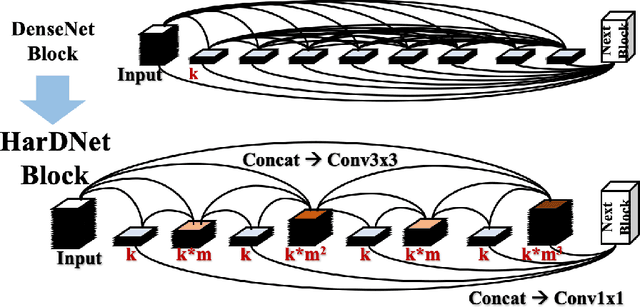
State-of-the-art neural network architectures such as ResNet, MobileNet, and DenseNet have achieved outstanding accuracy over low MACs and small model size counterparts. However, these metrics might not be accurate for predicting the inference time. We suggest that memory traffic for accessing intermediate feature maps can be a factor dominating the inference latency, especially in such tasks as real-time object detection and semantic segmentation of high-resolution video. We propose a Harmonic Densely Connected Network to achieve high efficiency in terms of both low MACs and memory traffic. The new network achieves 35%, 36%, 30%, 32%, and 45% inference time reduction compared with FC-DenseNet-103, DenseNet-264, ResNet-50, ResNet-152, and SSD-VGG, respectively. We use tools including Nvidia profiler and ARM Scale-Sim to measure the memory traffic and verify that the inference latency is indeed proportional to the memory traffic consumption and the proposed network consumes low memory traffic. We conclude that one should take memory traffic into consideration when designing neural network architectures for high-resolution applications at the edge.