 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompleteMe: Reference-based Human Image Completion
Apr 28, 2025Recent methods for human image completion can reconstruct plausible body shapes but often fail to preserve unique details, such as specific clothing patterns or distinctive accessories, without explicit reference images. Even state-of-the-art reference-based inpainting approaches struggle to accurately capture and integrate fine-grained details from reference images. To address this limitation, we propose CompleteMe, a novel reference-based human image completion framework. CompleteMe employs a dual U-Net architecture combined with a Region-focused Attention (RFA) Block, which explicitly guides the model's attention toward relevant regions in reference images. This approach effectively captures fine details and ensures accurate semantic correspondence, significantly improving the fidelity and consistency of completed images. Additionally, we introduce a challenging benchmark specifically designed for evaluating reference-based human image completion tasks. Extensive experiments demonstrate that our proposed method achieves superior visual quality and semantic consistency compared to existing techniques. Project page: https://liagm.github.io/CompleteMe/
An Improved Variational Method for Image Denoising
Oct 03, 2024
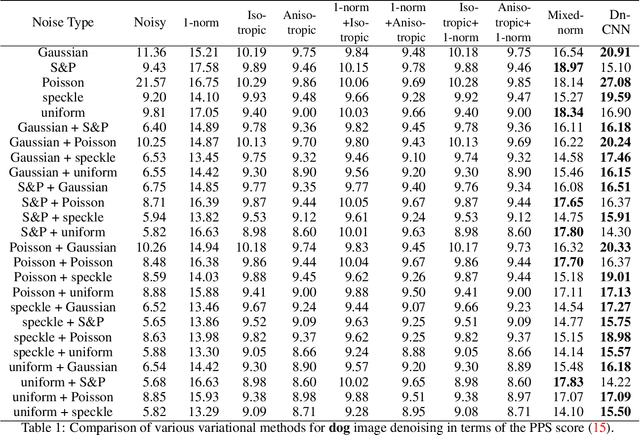
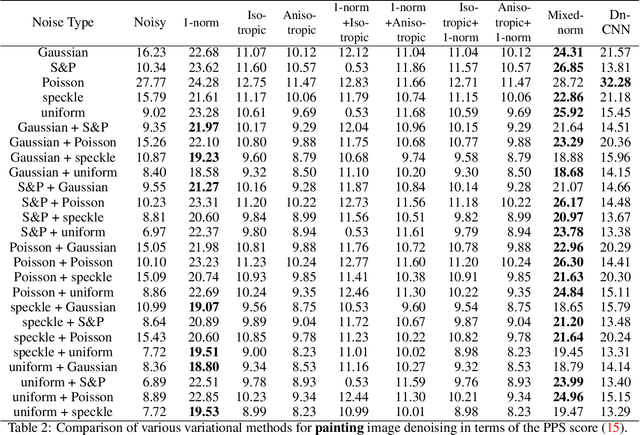

The total variation (TV) method is an image denoising technique that aims to reduce noise by minimizing the total variation of the image, which measures the variation in pixel intensities. The TV method has been widely applied in image processing and computer vision for its ability to preserve edges and enhance image quality. In this paper, we propose an improved TV model for image denoising and the associated numerical algorithm to carry out the procedure, which is particularly effective in removing several types of noises and their combinations. Our improved model admits a unique solution and the associated numerical algorithm guarantees the convergence. Numerical experiments are demonstrated to show improved effectiveness and denoising quality compared to other TV models. Such encouraging results further enhance the utility of the TV method in image processing.
No More Ambiguity in 360° Room Layout via Bi-Layout Estimation
Apr 15, 2024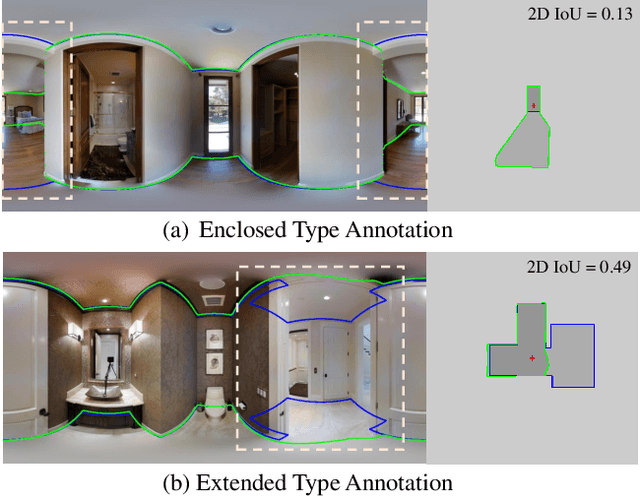
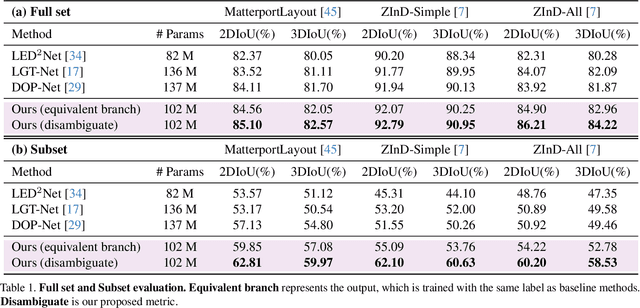
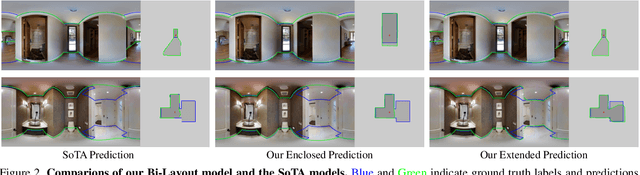
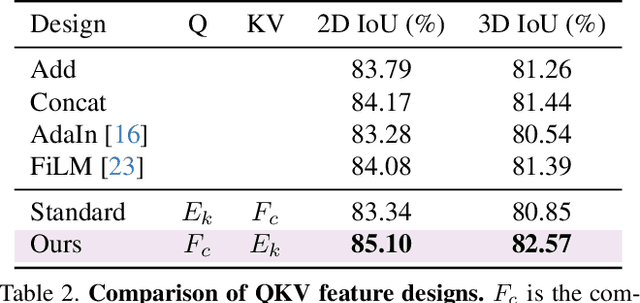
Inherent ambiguity in layout annotations poses significant challenges to developing accurate 360{\deg} room layout estimation models. To address this issue, we propose a novel Bi-Layout model capable of predicting two distinct layout types. One stops at ambiguous regions, while the other extends to encompass all visible areas. Our model employs two global context embeddings, where each embedding is designed to capture specific contextual information for each layout type. With our novel feature guidance module, the image feature retrieves relevant context from these embeddings, generating layout-aware features for precise bi-layout predictions. A unique property of our Bi-Layout model is its ability to inherently detect ambiguous regions by comparing the two predictions. To circumvent the need for manual correction of ambiguous annotations during testing, we also introduce a new metric for disambiguating ground truth layouts. Our method demonstrates superior performance on benchmark datasets, notably outperforming leading approaches. Specifically, on the MatterportLayout dataset, it improves 3DIoU from 81.70% to 82.57% across the full test set and notably from 54.80% to 59.97% in subsets with significant ambiguity. Project page: https://liagm.github.io/Bi_Layout/
Effective Adapter for Face Recognition in the Wild
Dec 04, 2023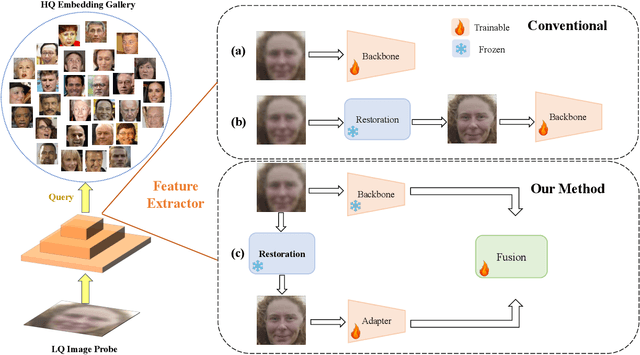

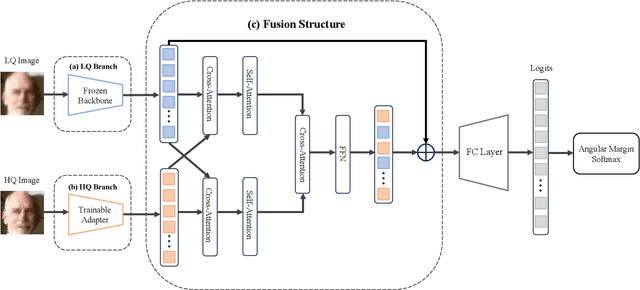

In this paper, we tackle the challenge of face recognition in the wild, where images often suffer from low quality and real-world distortions. Traditional heuristic approaches-either training models directly on these degraded images or their enhanced counterparts using face restoration techniques-have proven ineffective, primarily due to the degradation of facial features and the discrepancy in image domains. To overcome these issues, we propose an effective adapter for augmenting existing face recognition models trained on high-quality facial datasets. The key of our adapter is to process both the unrefined and the enhanced images by two similar structures where one is fixed and the other trainable. Such design can confer two benefits. First, the dual-input system minimizes the domain gap while providing varied perspectives for the face recognition model, where the enhanced image can be regarded as a complex non-linear transformation of the original one by the restoration model. Second, both two similar structures can be initialized by the pre-trained models without dropping the past knowledge. The extensive experiments in zero-shot settings show the effectiveness of our method by surpassing baselines of about 3%, 4%, and 7% in three datasets. Our code will be publicly available at https://github.com/liuyunhaozz/FaceAdapter/.
Dual Associated Encoder for Face Restoration
Aug 14, 2023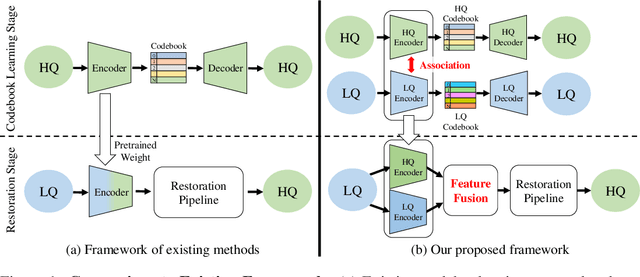

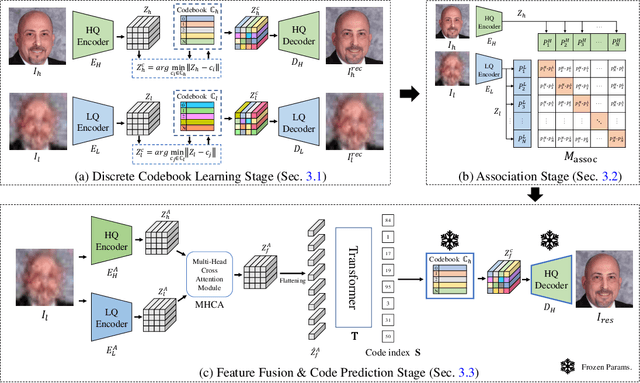

Restoring facial details from low-quality (LQ) images has remained a challenging problem due to its ill-posedness induced by various degradations in the wild. The existing codebook prior mitigates the ill-posedness by leveraging an autoencoder and learned codebook of high-quality (HQ) features, achieving remarkable quality. However, existing approaches in this paradigm frequently depend on a single encoder pre-trained on HQ data for restoring HQ images, disregarding the domain gap between LQ and HQ images. As a result, the encoding of LQ inputs may be insufficient, resulting in suboptimal performance. To tackle this problem, we propose a novel dual-branch framework named DAEFR. Our method introduces an auxiliary LQ branch that extracts crucial information from the LQ inputs. Additionally, we incorporate association training to promote effective synergy between the two branches, enhancing code prediction and output quality. We evaluate the effectiveness of DAEFR on both synthetic and real-world datasets, demonstrating its superior performance in restoring facial details.
SearchTrack: Multiple Object Tracking with Object-Customized Search and Motion-Aware Features
Oct 29, 2022



The paper presents a new method, SearchTrack, for multiple object tracking and segmentation (MOTS). To address the association problem between detected objects, SearchTrack proposes object-customized search and motion-aware features. By maintaining a Kalman filter for each object, we encode the predicted motion into the motion-aware feature, which includes both motion and appearance cues. For each object, a customized fully convolutional search engine is created by SearchTrack by learning a set of weights for dynamic convolutions specific to the object. Experiments demonstrate that our SearchTrack method outperforms competitive methods on both MOTS and MOT tasks, particularly in terms of association accuracy. Our method achieves 71.5 HOTA (car) and 57.6 HOTA (pedestrian) on the KITTI MOTS and 53.4 HOTA on MOT17. In terms of association accuracy, our method achieves state-of-the-art performance among 2D online methods on the KITTI MOTS. Our code is available at https://github.com/qa276390/SearchTrack.