 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeuLayout: Unified Room Layout Estimation for Perspective and Panoramic Images
Mar 27, 2025We present uLayout, a unified model for estimating room layout geometries from both perspective and panoramic images, whereas traditional solutions require different model designs for each image type. The key idea of our solution is to unify both domains into the equirectangular projection, particularly, allocating perspective images into the most suitable latitude coordinate to effectively exploit both domains seamlessly. To address the Field-of-View (FoV) difference between the input domains, we design uLayout with a shared feature extractor with an extra 1D-Convolution layer to condition each domain input differently. This conditioning allows us to efficiently formulate a column-wise feature regression problem regardless of the FoV input. This simple yet effective approach achieves competitive performance with current state-of-the-art solutions and shows for the first time a single end-to-end model for both domains. Extensive experiments in the real-world datasets, LSUN, Matterport3D, PanoContext, and Stanford 2D-3D evidence the contribution of our approach. Code is available at https://github.com/JonathanLee112/uLayout.
V-MIND: Building Versatile Monocular Indoor 3D Detector with Diverse 2D Annotations
Dec 16, 2024The field of indoor monocular 3D object detection is gaining significant attention, fueled by the increasing demand in VR/AR and robotic applications. However, its advancement is impeded by the limited availability and diversity of 3D training data, owing to the labor-intensive nature of 3D data collection and annotation processes. In this paper, we present V-MIND (Versatile Monocular INdoor Detector), which enhances the performance of indoor 3D detectors across a diverse set of object classes by harnessing publicly available large-scale 2D datasets. By leveraging well-established monocular depth estimation techniques and camera intrinsic predictors, we can generate 3D training data by converting large-scale 2D images into 3D point clouds and subsequently deriving pseudo 3D bounding boxes. To mitigate distance errors inherent in the converted point clouds, we introduce a novel 3D self-calibration loss for refining the pseudo 3D bounding boxes during training. Additionally, we propose a novel ambiguity loss to address the ambiguity that arises when introducing new classes from 2D datasets. Finally, through joint training with existing 3D datasets and pseudo 3D bounding boxes derived from 2D datasets, V-MIND achieves state-of-the-art object detection performance across a wide range of classes on the Omni3D indoor dataset.
Self-training Room Layout Estimation via Geometry-aware Ray-casting
Jul 21, 2024



In this paper, we introduce a novel geometry-aware self-training framework for room layout estimation models on unseen scenes with unlabeled data. Our approach utilizes a ray-casting formulation to aggregate multiple estimates from different viewing positions, enabling the computation of reliable pseudo-labels for self-training. In particular, our ray-casting approach enforces multi-view consistency along all ray directions and prioritizes spatial proximity to the camera view for geometry reasoning. As a result, our geometry-aware pseudo-labels effectively handle complex room geometries and occluded walls without relying on assumptions such as Manhattan World or planar room walls. Evaluation on publicly available datasets, including synthetic and real-world scenarios, demonstrates significant improvements in current state-of-the-art layout models without using any human annotation.
No More Ambiguity in 360° Room Layout via Bi-Layout Estimation
Apr 15, 2024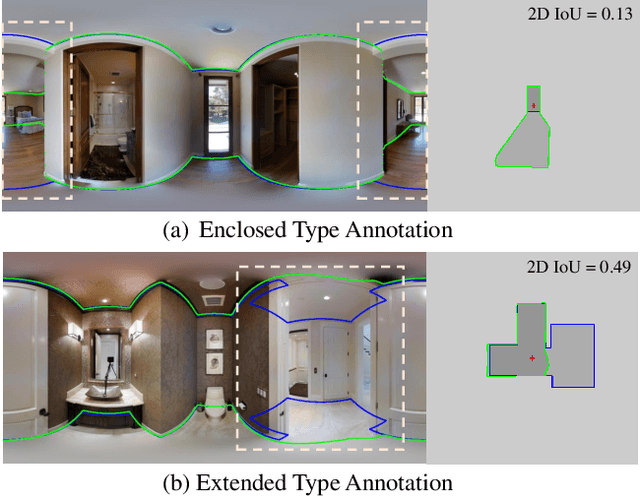
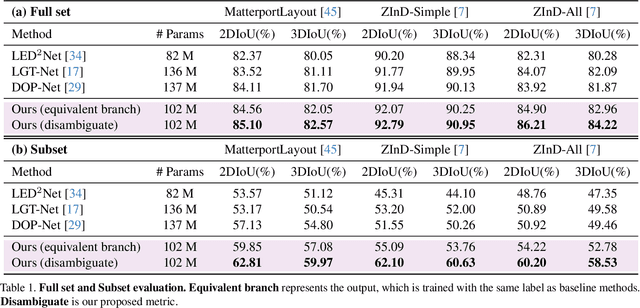
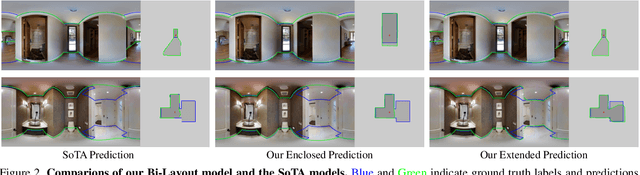
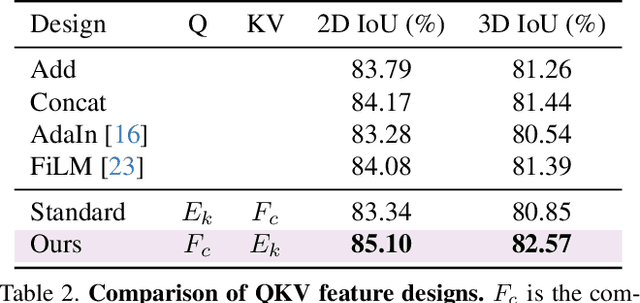
Inherent ambiguity in layout annotations poses significant challenges to developing accurate 360{\deg} room layout estimation models. To address this issue, we propose a novel Bi-Layout model capable of predicting two distinct layout types. One stops at ambiguous regions, while the other extends to encompass all visible areas. Our model employs two global context embeddings, where each embedding is designed to capture specific contextual information for each layout type. With our novel feature guidance module, the image feature retrieves relevant context from these embeddings, generating layout-aware features for precise bi-layout predictions. A unique property of our Bi-Layout model is its ability to inherently detect ambiguous regions by comparing the two predictions. To circumvent the need for manual correction of ambiguous annotations during testing, we also introduce a new metric for disambiguating ground truth layouts. Our method demonstrates superior performance on benchmark datasets, notably outperforming leading approaches. Specifically, on the MatterportLayout dataset, it improves 3DIoU from 81.70% to 82.57% across the full test set and notably from 54.80% to 59.97% in subsets with significant ambiguity. Project page: https://liagm.github.io/Bi_Layout/