 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenM3D: Open Vocabulary Multi-view Indoor 3D Object Detection without Human Annotations
Aug 27, 2025Open-vocabulary (OV) 3D object detection is an emerging field, yet its exploration through image-based methods remains limited compared to 3D point cloud-based methods. We introduce OpenM3D, a novel open-vocabulary multi-view indoor 3D object detector trained without human annotations. In particular, OpenM3D is a single-stage detector adapting the 2D-induced voxel features from the ImGeoNet model. To support OV, it is jointly trained with a class-agnostic 3D localization loss requiring high-quality 3D pseudo boxes and a voxel-semantic alignment loss requiring diverse pre-trained CLIP features. We follow the training setting of OV-3DET where posed RGB-D images are given but no human annotations of 3D boxes or classes are available. We propose a 3D Pseudo Box Generation method using a graph embedding technique that combines 2D segments into coherent 3D structures. Our pseudo-boxes achieve higher precision and recall than other methods, including the method proposed in OV-3DET. We further sample diverse CLIP features from 2D segments associated with each coherent 3D structure to align with the corresponding voxel feature. The key to training a highly accurate single-stage detector requires both losses to be learned toward high-quality targets. At inference, OpenM3D, a highly efficient detector, requires only multi-view images for input and demonstrates superior accuracy and speed (0.3 sec. per scene) on ScanNet200 and ARKitScenes indoor benchmarks compared to existing methods. We outperform a strong two-stage method that leverages our class-agnostic detector with a ViT CLIP-based OV classifier and a baseline incorporating multi-view depth estimator on both accuracy and speed.
UA-Pose: Uncertainty-Aware 6D Object Pose Estimation and Online Object Completion with Partial References
Jun 09, 2025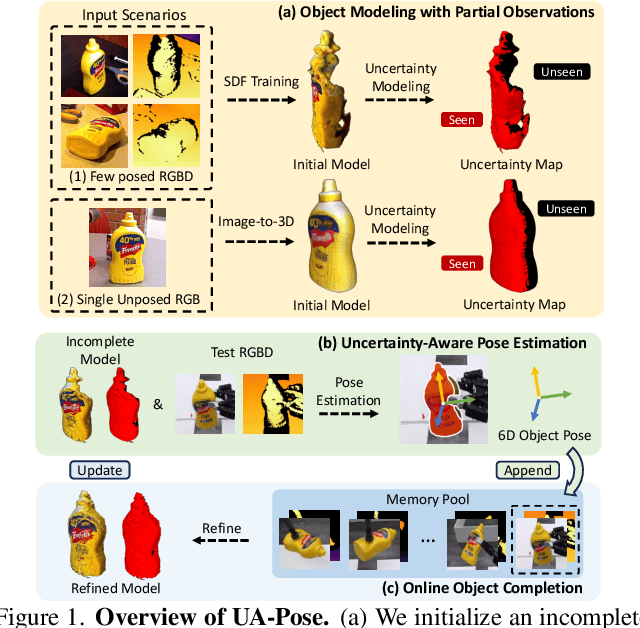

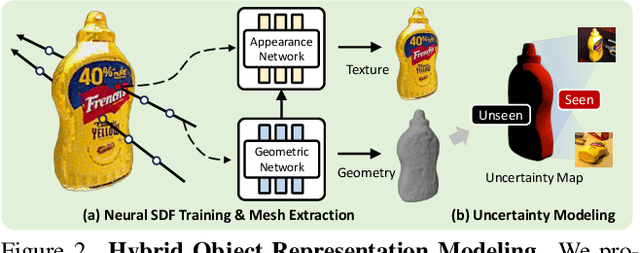

6D object pose estimation has shown strong generalizability to novel objects. However, existing methods often require either a complete, well-reconstructed 3D model or numerous reference images that fully cover the object. Estimating 6D poses from partial references, which capture only fragments of an object's appearance and geometry, remains challenging. To address this, we propose UA-Pose, an uncertainty-aware approach for 6D object pose estimation and online object completion specifically designed for partial references. We assume access to either (1) a limited set of RGBD images with known poses or (2) a single 2D image. For the first case, we initialize a partial object 3D model based on the provided images and poses, while for the second, we use image-to-3D techniques to generate an initial object 3D model. Our method integrates uncertainty into the incomplete 3D model, distinguishing between seen and unseen regions. This uncertainty enables confidence assessment in pose estimation and guides an uncertainty-aware sampling strategy for online object completion, enhancing robustness in pose estimation accuracy and improving object completeness. We evaluate our method on the YCB-Video, YCBInEOAT, and HO3D datasets, including RGBD sequences of YCB objects manipulated by robots and human hands. Experimental results demonstrate significant performance improvements over existing methods, particularly when object observations are incomplete or partially captured. Project page: https://minfenli.github.io/UA-Pose/
uLayout: Unified Room Layout Estimation for Perspective and Panoramic Images
Mar 27, 2025We present uLayout, a unified model for estimating room layout geometries from both perspective and panoramic images, whereas traditional solutions require different model designs for each image type. The key idea of our solution is to unify both domains into the equirectangular projection, particularly, allocating perspective images into the most suitable latitude coordinate to effectively exploit both domains seamlessly. To address the Field-of-View (FoV) difference between the input domains, we design uLayout with a shared feature extractor with an extra 1D-Convolution layer to condition each domain input differently. This conditioning allows us to efficiently formulate a column-wise feature regression problem regardless of the FoV input. This simple yet effective approach achieves competitive performance with current state-of-the-art solutions and shows for the first time a single end-to-end model for both domains. Extensive experiments in the real-world datasets, LSUN, Matterport3D, PanoContext, and Stanford 2D-3D evidence the contribution of our approach. Code is available at https://github.com/JonathanLee112/uLayout.
V-MIND: Building Versatile Monocular Indoor 3D Detector with Diverse 2D Annotations
Dec 16, 2024The field of indoor monocular 3D object detection is gaining significant attention, fueled by the increasing demand in VR/AR and robotic applications. However, its advancement is impeded by the limited availability and diversity of 3D training data, owing to the labor-intensive nature of 3D data collection and annotation processes. In this paper, we present V-MIND (Versatile Monocular INdoor Detector), which enhances the performance of indoor 3D detectors across a diverse set of object classes by harnessing publicly available large-scale 2D datasets. By leveraging well-established monocular depth estimation techniques and camera intrinsic predictors, we can generate 3D training data by converting large-scale 2D images into 3D point clouds and subsequently deriving pseudo 3D bounding boxes. To mitigate distance errors inherent in the converted point clouds, we introduce a novel 3D self-calibration loss for refining the pseudo 3D bounding boxes during training. Additionally, we propose a novel ambiguity loss to address the ambiguity that arises when introducing new classes from 2D datasets. Finally, through joint training with existing 3D datasets and pseudo 3D bounding boxes derived from 2D datasets, V-MIND achieves state-of-the-art object detection performance across a wide range of classes on the Omni3D indoor dataset.
Sparse and Privacy-enhanced Representation for Human Pose Estimation
Sep 18, 2023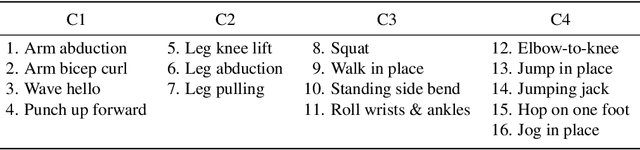
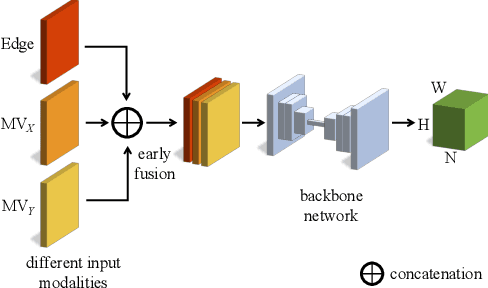
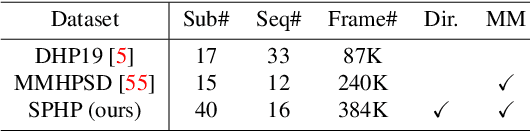
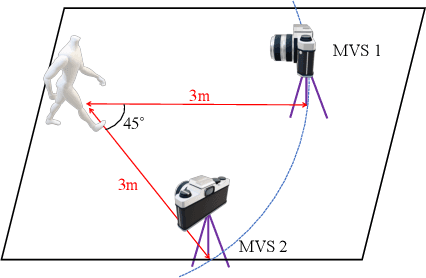
We propose a sparse and privacy-enhanced representation for Human Pose Estimation (HPE). Given a perspective camera, we use a proprietary motion vector sensor(MVS) to extract an edge image and a two-directional motion vector image at each time frame. Both edge and motion vector images are sparse and contain much less information (i.e., enhancing human privacy). We advocate that edge information is essential for HPE, and motion vectors complement edge information during fast movements. We propose a fusion network leveraging recent advances in sparse convolution used typically for 3D voxels to efficiently process our proposed sparse representation, which achieves about 13x speed-up and 96% reduction in FLOPs. We collect an in-house edge and motion vector dataset with 16 types of actions by 40 users using the proprietary MVS. Our method outperforms individual modalities using only edge or motion vector images. Finally, we validate the privacy-enhanced quality of our sparse representation through face recognition on CelebA (a large face dataset) and a user study on our in-house dataset.
VMCML: Video and Music Matching via Cross-Modality Lifting
Mar 22, 2023We propose a content-based system for matching video and background music. The system aims to address the challenges in music recommendation for new users or new music give short-form videos. To this end, we propose a cross-modal framework VMCML that finds a shared embedding space between video and music representations. To ensure the embedding space can be effectively shared by both representations, we leverage CosFace loss based on margin-based cosine similarity loss. Furthermore, we establish a large-scale dataset called MSVD, in which we provide 390 individual music and the corresponding matched 150,000 videos. We conduct extensive experiments on Youtube-8M and our MSVD datasets. Our quantitative and qualitative results demonstrate the effectiveness of our proposed framework and achieve state-of-the-art video and music matching performance.
MixFairFace: Towards Ultimate Fairness via MixFair Adapter in Face Recognition
Nov 28, 2022



Although significant progress has been made in face recognition, demographic bias still exists in face recognition systems. For instance, it usually happens that the face recognition performance for a certain demographic group is lower than the others. In this paper, we propose MixFairFace framework to improve the fairness in face recognition models. First of all, we argue that the commonly used attribute-based fairness metric is not appropriate for face recognition. A face recognition system can only be considered fair while every person has a close performance. Hence, we propose a new evaluation protocol to fairly evaluate the fairness performance of different approaches. Different from previous approaches that require sensitive attribute labels such as race and gender for reducing the demographic bias, we aim at addressing the identity bias in face representation, i.e., the performance inconsistency between different identities, without the need for sensitive attribute labels. To this end, we propose MixFair Adapter to determine and reduce the identity bias of training samples. Our extensive experiments demonstrate that our MixFairFace approach achieves state-of-the-art fairness performance on all benchmark datasets.
BiFuse++: Self-supervised and Efficient Bi-projection Fusion for 360 Depth Estimation
Sep 07, 2022
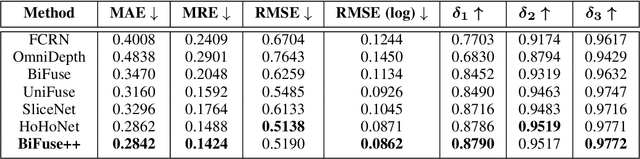

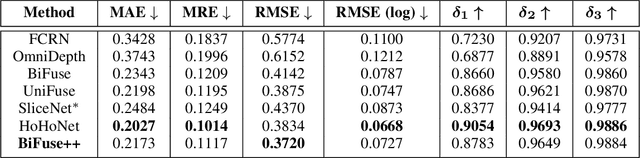
Due to the rise of spherical cameras, monocular 360 depth estimation becomes an important technique for many applications (e.g., autonomous systems). Thus, state-of-the-art frameworks for monocular 360 depth estimation such as bi-projection fusion in BiFuse are proposed. To train such a framework, a large number of panoramas along with the corresponding depth ground truths captured by laser sensors are required, which highly increases the cost of data collection. Moreover, since such a data collection procedure is time-consuming, the scalability of extending these methods to different scenes becomes a challenge. To this end, self-training a network for monocular depth estimation from 360 videos is one way to alleviate this issue. However, there are no existing frameworks that incorporate bi-projection fusion into the self-training scheme, which highly limits the self-supervised performance since bi-projection fusion can leverage information from different projection types. In this paper, we propose BiFuse++ to explore the combination of bi-projection fusion and the self-training scenario. To be specific, we propose a new fusion module and Contrast-Aware Photometric Loss to improve the performance of BiFuse and increase the stability of self-training on real-world videos. We conduct both supervised and self-supervised experiments on benchmark datasets and achieve state-of-the-art performance.
LED2-Net: Monocular 360 Layout Estimation via Differentiable Depth Rendering
Apr 03, 2021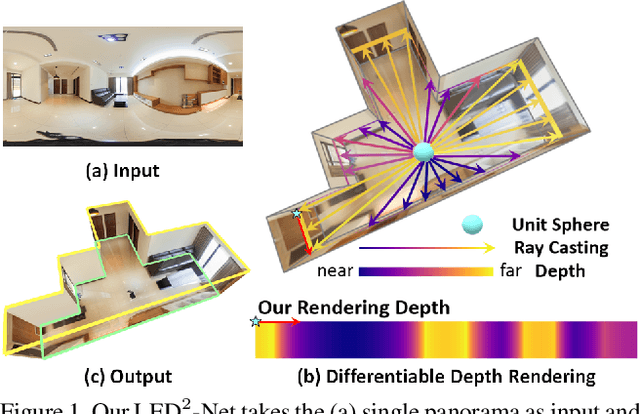
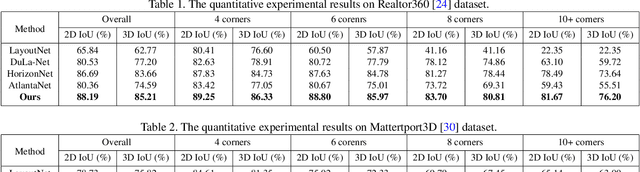


Although significant progress has been made in room layout estimation, most methods aim to reduce the loss in the 2D pixel coordinate rather than exploiting the room structure in the 3D space. Towards reconstructing the room layout in 3D, we formulate the task of 360 layout estimation as a problem of predicting depth on the horizon line of a panorama. Specifically, we propose the Differentiable Depth Rendering procedure to make the conversion from layout to depth prediction differentiable, thus making our proposed model end-to-end trainable while leveraging the 3D geometric information, without the need of providing the ground truth depth. Our method achieves state-of-the-art performance on numerous 360 layout benchmark datasets. Moreover, our formulation enables a pre-training step on the depth dataset, which further improves the generalizability of our layout estimation model.
LayoutMP3D: Layout Annotation of Matterport3D
Mar 30, 2020
Inferring the information of 3D layout from a single equirectangular panorama is crucial for numerous applications of virtual reality or robotics (e.g., scene understanding and navigation). To achieve this, several datasets are collected for the task of 360 layout estimation. To facilitate the learning algorithms for autonomous systems in indoor scenarios, we consider the Matterport3D dataset with their originally provided depth map ground truths and further release our annotations for layout ground truths from a subset of Matterport3D. As Matterport3D contains accurate depth ground truths from time-of-flight (ToF) sensors, our dataset provides both the layout and depth information, which enables the opportunity to explore the environment by integrating both cues.